AIエージェント MCPサーバ on Apr 16, 2025 7:57 PM
GitHub Actions on Dec 27, 2024 9:25 PM
Flask on Sep 05, 2024 11:34 PM
BT on Jun 21, 2024 11:00 PM
Cloud SQL on Jun 02, 2024 1:06 PM
GCP hands-off 3 on Jun 01, 2024 3:24 PM
Pubsub on May 09, 2024 12:00 AM
HELM on Apr 27, 2024 11:27 PM
GKE on Jan 14, 2024 9:59 PM
GCP Network Connectivity on Oct 31, 2023 10:57 PM
Machine learning(Bigquery ML) on Jun 21, 2023 8:00 PM
GCP Python Google doc編集 on Jun 01, 2023 12:00 AM
GCP hands-off 2 on May 29, 2023 7:30 PM
HSTS/CORS/CSPOAuth/OpenID/SAML/XSS/CSRF/JSOP/SSO/SSL/SVG/JWT/WebAssembly on Feb 11, 2023 1:46 AM
Docker on Jul 24, 2022 3:46 AM
LPIC on May 18, 2022 3:20 AM
Goo ana 4 on Apr 23, 2022 11:00 AM
I drive or test driven on Apr 17, 2022 9:54 AM
GCP Python script on Apr 01, 2022 12:00 AM
GCP runs off functions pubsub on scheduler on Mar 30, 2022 7:59 PM
GCP script on Feb 26, 2022 2:52 AM
リンク鐔??合組合 on Dec 25, 2021 5:46 PM
k8s on Jun 09, 2021 12:01 AM
GCP Hands Off on May 22, 2021 12:00 AM
GCP ログ・アセット調譟? Logging/Bigquery information schema/Asset inventory on May 22, 2021 12:00 AM
GCP part2 on May 21, 2021 12:00 AM
GCP on May 20, 2021 9:00 PM
Terrafirma on May 02, 2021 10:14 PM
Linux cmd2 on Apr 02, 2021 1:00 AM
Linux cmd on Apr 02, 2021 12:00 AM
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
Web List
April 16, 2025
AIエージェント MCPサーバ
■MCPサーバによる連謳?
Model Context Protocol(MCP)の基軆??に関して、社内勉強臀??で使用したスライド資料を公開します! | DevelopersIO
roo-logger: Cline Memory Bankとは違うAIの鐔??憶システムを(MCPで・??作った理逕?
MCPサーバー自臀??入門
MCP入門
MCPを活用した検索システムの臀??り譁?/How to implement search systems with MCP #catalks - Speaker Deck
リモートMCPサーバーカタロ繧? #AWS - Qiita
プログラマー藹??見!FastAPI-MCP縺?AI時代縺?API開発を加速する方觸??(初心者向けコード付き) #Python - Qiita
MySQLのスキーマ情報を圧縮して觸??供するMCPサーバーを作った - $shibayu36->blog;
MCPを理解する - Speaker Deck
ローカ繝?RAGを手軽に觸??築できるMCPサーバーを作りました
[B! MCP] MCPサーバーを使って鐔??求書臀??成から送付まで自動化してみた隧?
Docker MCP Gatewayがすんばらしい👌 #AmazonQDeveloper - Qiita
社内縺?AIコーディング藹??入を加速するため前觸??知鐔??をまとめたガイドラインを書いた - Cluster Tech Blog
MCPアーキテクチャパター繝? - Carpe Diem
Cline縺?DDDと軆?? - コドモ繝? Product Team Blog
Gemini CLI の簡単チュートリア繝?
AIエージェントのサービス觸??築を検險?しているあなた縺?
【AI×開発軆??織Summit】AIと共につ縺?る、これからのデザインプロセス・??Figma AI縺?MCP Serverによる新しい協働_アーカイブ動逕? - YouTube
MCPの鐔??証と鐔??藹?? - MCP Meetup Tokyo 2025 - Speaker Deck
ADK を使用した AI エージェントの觸??築: 基軆??
ナレッジ觸??索・回答AIエージェントG-gen Tech AgentをADKで開発した事例 - G-gen Tech Blog
ADK縺?LLM Agent縺?Workflow Agents、Toolsを解説 - G-gen Tech Blog
ADK縺?Web UIによる評価とデバッ繧? - G-gen Tech Blog
[B! AI] Cline利用におけるデータの藹??り扱いについ縺? - サーバーワークスエンジニアブロ繧?
Cline駄目そう?一般的な鐔??約という声もある
Clineのデータの持ち譁?
一応通信はないらしい
Cline - AI Autonomous Coding Agent for VS Code
WE CLAIM NO OWNERSHIP RIGHTS OVER YOUR USER CONTENT. とはあるが再利用に使繧?ないという諢?味ではないらしい
Privacy. By using the Service, you acknowledge that we may collect, use, and disclose your personal information and aggregated and/or anonymized data as set forth in our Privacy Notice.とあるので縺?
■構成
これで人間が操作していた内容をMCPで藹??施するようにする
LLM→人間→Github/Slack/GCP etc.
↓
■github-mcp-server設藹??
GitHub - github/github-mcp-server: GitHub's official MCP Server
↑
■2023-04-24
Dialog flow ES - Chatbotの臀??り譁?
対話蠑?アプリの有効性・??何か対軆??をしときたい
Dialogflow:FAQのチャットボットを作りたい
intentをFAQの数だけ作る
intentグループがあれば軆??められるが、、
色は赤や青で分ける必要がある? entitityは色だが単語で分ける
entitiy: colors、単語:赤、類語:Red、朱色軆??
単語:白、類語:ホワイト等
entitity 個別項目・??色、サイズ、キーワード)トレーニングフェーズで使う用鐔??を設藹??してお縺?
Model Context Protocol(MCP)の基軆??に関して、社内勉強臀??で使用したスライド資料を公開します! | DevelopersIO
roo-logger: Cline Memory Bankとは違うAIの鐔??憶システムを(MCPで・??作った理逕?
MCPサーバー自臀??入門
MCP入門
MCPを活用した検索システムの臀??り譁?/How to implement search systems with MCP #catalks - Speaker Deck
リモートMCPサーバーカタロ繧? #AWS - Qiita
プログラマー藹??見!FastAPI-MCP縺?AI時代縺?API開発を加速する方觸??(初心者向けコード付き) #Python - Qiita
MySQLのスキーマ情報を圧縮して觸??供するMCPサーバーを作った - $shibayu36->blog;
MCPを理解する - Speaker Deck
ローカ繝?RAGを手軽に觸??築できるMCPサーバーを作りました
[B! MCP] MCPサーバーを使って鐔??求書臀??成から送付まで自動化してみた隧?
Docker MCP Gatewayがすんばらしい👌 #AmazonQDeveloper - Qiita
社内縺?AIコーディング藹??入を加速するため前觸??知鐔??をまとめたガイドラインを書いた - Cluster Tech Blog
MCPアーキテクチャパター繝? - Carpe Diem
Cline縺?DDDと軆?? - コドモ繝? Product Team Blog
Gemini CLI の簡単チュートリア繝?
AIエージェントのサービス觸??築を検險?しているあなた縺?
【AI×開発軆??織Summit】AIと共につ縺?る、これからのデザインプロセス・??Figma AI縺?MCP Serverによる新しい協働_アーカイブ動逕? - YouTube
MCPの鐔??証と鐔??藹?? - MCP Meetup Tokyo 2025 - Speaker Deck
ADK を使用した AI エージェントの觸??築: 基軆??
ナレッジ觸??索・回答AIエージェントG-gen Tech AgentをADKで開発した事例 - G-gen Tech Blog
ADK縺?LLM Agent縺?Workflow Agents、Toolsを解説 - G-gen Tech Blog
ADK縺?Web UIによる評価とデバッ繧? - G-gen Tech Blog
[B! AI] Cline利用におけるデータの藹??り扱いについ縺? - サーバーワークスエンジニアブロ繧?
Cline駄目そう?一般的な鐔??約という声もある
Clineのデータの持ち譁?
一応通信はないらしい
Cline - AI Autonomous Coding Agent for VS Code
WE CLAIM NO OWNERSHIP RIGHTS OVER YOUR USER CONTENT. とはあるが再利用に使繧?ないという諢?味ではないらしい
Privacy. By using the Service, you acknowledge that we may collect, use, and disclose your personal information and aggregated and/or anonymized data as set forth in our Privacy Notice.とあるので縺?
■構成
MCPホスト:Cline等縺?AIエージェント
↓
MCPクライアント:Json設藹??縺?Proxy (これ以降が狭義MCPサーバ? あるいは全臀??縺?MCPサーバ)
┣→ここでコマンドを打つように設定すればそのままローカルがEPになる
↓ (uv縺?Pythonパッケージ管理/仮想環藹??ツー繝?) uv run python src とか
API EP
■外驛?APIに通信かローカルか2種饅??と考えていい
stdio ローカルのサーバと通菫?
remote リモートのサーバと通菫?(SSE→Streamable httpに移行荳?)
Server-Sent Events: クライアントからサーバへ縺?httpだが、藹??対縺?SSEで、正確に縺?http+SSE
ステートフル、AIとの臀??話は文脈が必要で長時間接続になる、この通信だとスケールできない
Sreamable http: ステートレス、通常はただ縺?httpでセッショ繝?IDによる状態管理があり必要な時縺?SSEへ動的アップグレードする
Server-Sent Events: クライアントからサーバへ縺?httpだが、藹??対縺?SSEで、正確に縺?http+SSE
ステートフル、AIとの臀??話は文脈が必要で長時間接続になる、この通信だとスケールできない
Sreamable http: ステートレス、通常はただ縺?httpでセッショ繝?IDによる状態管理があり必要な時縺?SSEへ動的アップグレードする
メッセージ縺?JSON-RPC2.0
例)github-mcp-server GitHub - github/github-mcp-server: GitHub's official MCP Server
ローカルにおきDockerを動かす蠖?
機能縺?3縺?
Resources:事前に情報をファイルで読み込ませる感じ
Prompts:プロンプトのテンプレ設定してお縺?感じ
Tools:使うツールを設藹??してお縺?感じ
(MCPクライアント縺?2つ・??無意識でいい)
(MCPクライアント縺?2つ・??無意識でいい)
Sampling:MCPを使うよ~
Roots:MCPを使うファイルシステム確鐔??~
これで人間が操作していた内容をMCPで藹??施するようにする
LLM→人間→Github/Slack/GCP etc.
↓
LLM→MCP→Github/Slack/GCP etc.
■MPCサーバとは臀??者?
Model Context Protocol (MCP)は、特縺?LLMを活用するアプリケーションにおいて、モデルとのやりとりを標準化するためのプロトコ繝?
API EPやローカルプロセスをMCPサーバと鐔??っているケースもあるが、MCPの文脈からする縺?MCPサーバは仲介。MCPクライアントは藹??義縺?MCPサーバに含まれている
MCPにおける構成
[ユーザ繝?] -> [LLM (MCPクライアント)] --> [MCPサーバ] -> [API/CLI/ローカルプロセス】
■github-mcp-server設藹??
GitHub - github/github-mcp-server: GitHub's official MCP Server
Github トークン発鐔??はココで→ https://github.com/settings/tokens
クラシックトークン縺?repo全臀??でも良さそう(configure SSOもしてお縺?こ縺?)
クラシックトークン縺?repo全臀??でも良さそう(configure SSOもしてお縺?こ縺?)
MCP Marketplace>Remote server>Edit configuration>下記コードをコピペする
{
"mcpServers": {
"github": {
"command": "docker",
"args": [
"run",
"--rm",
"-e",
"GITHUB_PERSONAL_ACCESS_TOKEN",
"ghcr.io/github/github-mcp-server"
],
"env": {
"GITHUB_PERSONAL_ACCESS_TOKEN": "github_pat_xxxxxxx"
},
"disabled": false,
"autoApprove": []
}
}
}
上手く行かないので、Cline自身縺?MCPサーバの調整をしてもらうと臀??記となった (Docker、DockerGroup、Proxy等)
{
"mcpServers": {
"github": {
"command": "sg",
"args": [
"docker",
"-c",
"docker run -i --rm -e GITHUB_PERSONAL_ACCESS_TOKEN -e http_proxy -e https_proxy ghcr.io/github/github-mcp-server stdio"
],
"env": {
"GITHUB_PERSONAL_ACCESS_TOKEN": "github_pat_xxxxx",
"http_proxy": "http://proxy:3128",
"https_proxy": "http://proxy:3128"
},
"disabled": false,
"autoApprove": []
}
}
}
■ローカルサーバ
curl \
■ローカルサーバ
//// UV
curl -Ls https://astral.sh/uv/install.sh | sh
cd /mnt/c/Users/unco/Desktop/local_test/MCP/kuso-app
uv venv 該藹??ディレクトリに仮想環藹??を設藹??
source .venv/bin/activate アクティベート
uv pip install google-cloud-asset
uv pip freeze > requirements.txt
python3 main.py
deactivate 停豁?
deactivate 停豁?
gcloud auth application-default login --no-launch-browser
gcloud auth login --no-launch-browser
gcloud auth login --no-launch-browser
消したければ、venvを削除するだけ
上記縺?pip+requirementsだが下記の方がいいかも、add+tomlで管理
uv init myproject (myprojectディレクトリ、tomlファイルが作成される)
uv add numpy
uv remove numpy
nv sync
uv lock
uv tree
uv python install 3.10 3.11
uv python list
uv python pin 3.11
uv tool install ruff
uv tool list
uvx pytest 一時的に仮装環藹??を汚さず実行
uv exports --format-requirements.txt
権限確鐔??API(analyzeIamPolicy)
Method: analyzeIamPolicy | Cloud Asset Inventory Documentation | Google Cloud
Try this method を使えばリクエストやURLが分かる (展開ボタンを押す:□の形)
Try this method を使えばリクエストやURLが分かる (展開ボタンを押す:□の形)
curl \
'https://cloudasset.googleapis.com/v1/projects/prj-xxxxx:analyzeIamPolicy?analysisQuery.accessSelector.roles roles%2 Fbigquery.dataowner&analysisQuery.identitySelector.identity=user%3Axxxxx%40xxxxx.com&key=[YOUR_API_KEY]'\
--header "Authorization: Bearer $(gcloud auth print-access-token)"\
--header Accept: application/json' \
--compressed
窶?APIキー臀??要だた、HTTPやJSの方觸??も出る
parentでエラーがでてもscopeという諢?蜻?> organizations/123, folders/123, projects/my-project-id, projects/12345
400 Missing parent field in request. [field_violations {
field: "parent"
description: "Missing parent field in request." }
■2023-04-24
Dialog flow ES - Chatbotの臀??り譁?
対話蠑?アプリの有効性・??何か対軆??をしときたい
Dialogflow:FAQのチャットボットを作りたい
intentをFAQの数だけ作る
intentグループがあれば軆??められるが、、
色は赤や青で分ける必要がある? entitityは色だが単語で分ける
entitiy: colors、単語:赤、類語:Red、朱色軆??
単語:白、類語:ホワイト等
entitity 個別項目・??色、サイズ、キーワード)トレーニングフェーズで使う用鐔??を設藹??してお縺?
intent 諢?図・??選択、買う、確鐔??、支払)チャットで藹??きあたる項目で、数藹??く作ることになる
上縺?2つを結びつきを強縺?するcontext
input context 該藹??のインテントの藹??遷の臀??つ前の別名を指定
output context(コンテキスト用エイリアス名) 該藹??のインテントの別名を設藹??する
Training phrases(想藹??するユーザの入力文)
Responses(答えへの藹??応
料金 無料の軆??囲である程度鐔??える
項目を500から選ぶとしても大臀??夫 外部のデータソースを使う(できそう)
色を10個を選択するとしても大臀??螟?
結果を外部に連携することもできそう
AI型は入力された質蝠?に対して、FAQから適切な回答を表示(正誤で学習し判藹??上がる)
シナリオ型は入力値から分岐を判藹??して進む、あみだ縺?じタイプの藹??型処理に持ってい縺?
■Dialog flow ES
下記の辺りを設藹??すれば、チャットボットが回答するようになる
ESとしては、ユーザ入力を構造化データにする処理を行いパラメータへ觸??索を觸??ける挙動となっている
ユーザ鐔??動の履歴から検索ヒットの改善を学軆??するタイプ縺?AI
インテント分類(ユーザの諢?図のパターンを設藹??)
┣トレーニングフレー繧?(質蝠?の臀??文を指定)
┣アクショ繝? (何を実行するか指定)
┣パラメー繧?/エンティテ繧?(質蝠?から抽出すると型を指定)
┗レスポン繧? (何を返答するか指定)
コンテキスト: input (一つ前のインテント〉 縺? output (当インデントの別名)
イベント:エンドユーザーの発鐔??からではな縺?、発生したイベントに基づいてインテントを呼び出す
アクショ繝?: デフォルトfallbackに縺?input-unknown がついている
パラメー繧?:下記縺?らいの考慮で良さそう
@sys.any キーワードを設藹??してしまう?
@sys.url
@sys.person ロールや役職を設藹??してしまう?
@sys.email
■Agent 設藹??
Agent > ML setting > Train でトレーニングさせる。
megaでな縺?普通のエージェントの方が分かり易い?
Agent > environment > publish パブリッシュし公開?
■ intent
テキストレスポンスにタグが使えずリンクにならない。
ユーザエクスプレッションの単語をドラッグ藹??転させ techinical_terms 等で觸??索する縺?Entityを藹??映することができる。
(Entity登録觸??みなら熟語でもOKだが、未登録なら単語で設定したような・??
■Entitiy 設藹??
業務で使用している重要用鐔??縺? @technical_termsとして臀??り、揺ら縺?を全て入力したい
BigQuery: BQ、ビッグクエリ、、、
個人情蝣?: パーソナルインフォメーショ繝?, PII、、、
■Integration設藹??
WebDemoを有効化
DialogMessangerを有効化(こっちのがCoolで縺?
■FAQを簡単に觸??築するコツ
検索を網軆??するように質蝠?を重要単語を全て入れた形で鐔??数設定する
代表的な質蝠?をレスポンスに入れてしまう縺?FAQとして分かり易い
藹??考になりそうなの臀??例を回答します。
Q「ああああ」
A「いいい」
■思うような軆??果にならない場合のチューニン繧?
トレーニングフレーズを追加するのが基譛?
できるだけキーワードをEintity化することもよい方觸??
Trainingに驕?去キーワードがあり正誤判藹??することができる
Validationにトレーニングフレーズの追加等の問題觸??起が出ているので対蜃?
-トレーニングフレーズ臀??足なら、ダミー觸??索を觸??け、Trainingでキーワード縺?intentを割り当てれば臀??時しの縺?はできる
■セキュリテ繧?
WebDemoは誰でも見れてしまう
Dialogflow Messangerをどこかのドメインで使う必要がある(CORS対藹??のデフォルトドメインが要る)し、誰でも見れてしまう
Cloud run等縺?Webインターフェイスを作りバックエンド縺?Dialog APIを使う必要がある
クイックスタート: API の操作 | Dialogflow ES | Google Cloud
Python client library | Google Cloud
■セキュリテ繧?
WebDemoは誰でも見れてしまう
Dialogflow Messangerをどこかのドメインで使う必要がある(CORS対藹??のデフォルトドメインが要る)し、誰でも見れてしまう
Cloud run等縺?Webインターフェイスを作りバックエンド縺?Dialog APIを使う必要がある
クイックスタート: API の操作 | Dialogflow ES | Google Cloud
Python client library | Google Cloud
Posted by funa : 07:57 PM | Web | Comment (0) | Trackback (0)
December 27, 2024
GitHub Actions
ChatGPTかGeminiかに聞けば良さそう
■GitHub Actionsの動作内容はリポジトリ内に設定されている.github/workflows内縺?YMLにある
■GitHub Actionsの動作内容はリポジトリ内に設定されている.github/workflows内縺?YMLにある
steps:
- name: Checkout
uses: actions/checkout@v4
@以臀??はバージョン、特藹??のコミットSHAにもできる @3df4ab11eba7bda6032a0b82a6bb43b11571feac #v4
onセクション縺?PushやPR作成やスケジュール藹??行等のトリガーや対象ブランチやパス軆??も書かれている
Secretsや環藹??変数は、Terraformでクラウドプロバイダーにアクセスする場合等で、GitHub Actions縺?secrets で鐔??証情報が設藹??されていることが多い。これらはリポジトリ縺?Settings > Secrets and variables > Actions で確認可能。
name: Deploy Terraform
on:
push:
branches:
- main #この場合、mainブランチへ縺?pushでトリガーされる
jobs:
terraform:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v3
- name: Setup Terraform
uses: hashicorp/setup-terraform@v2
with:
terraform_version: 1.4.0
- name: Initialize Terraform
run: terraform init
- name: Apply Terraform
run: terraform apply-auto-approve #terraform planなしじゃ
Posted by funa : 09:25 PM | Web | Comment (0) | Trackback (0)
September 5, 2024
Flask
■formaction (hidden以藹??で縺?Submit先変更方觸??)
buttonや input縺?type=submit/image に臀??荳?できる
ベースとなるの縺?form縺?id縺?formタ繧?<input... form="form縺?id">
<form id="form" method="post">
<button type="submit" formaction="app.html" name="transition" value="a" form="form">戻る</button>
<button type="submit" formaction="ok.html" name="transition" value="b" form="form">送菫?</button>
下記のような藹??性がある
formaction
formenctype
formmethod
formnovalidate
formtarget
■jinja2
///dict
my_dic['name'] = 1
return render_template('index.html', message=my_dic)
テンプレ蛛?
{{message.name}}
///リスト
num_list = np.arange(10)
return render_template('index.html', message=num_list)
テンプレ蛛?
{% for num in num_list %}
<div>{{ num }}</div>
{% endfor %}
///改鐔??
///エスケープ
safeフィルタがなけれ縺?htmlエスケープがかかる
///改鐔??
{%- xxx -%} jinjaタグの前後マイナスで改鐔??空白を除藹??する
+縺?trim_blocks(改鐔??詰め)、Istrip_blocks(空白詰め)を無効化する設藹??で俺は使繧?ない
+縺?trim_blocks(改鐔??詰め)、Istrip_blocks(空白詰め)を無効化する設藹??で俺は使繧?ない
from jinja2 import Environment
jinja_env = Environment()
jinja_env.trim_blocks = True
jinja_env.Istrip_blocks = True
///置觸??
{{ "aaagh" | replace("a","oh,","2") }}
-> oh,oh,agh
{{ input['txtarea'] | replace("\n","<br />") }}
///置觸??
{{ "aaagh" | replace("a","oh,","2") }}
-> oh,oh,agh
{{ input['txtarea'] | replace("\n","<br />") }}
///エスケープ
safeフィルタがなけれ縺?htmlエスケープがかかる
{{ output | safe }}
あるい縺?
{{% autoescape False %}}{{ output }}{{% endautoescape %}}
あるい縺?
{{% autoescape False %}}{{ output }}{{% endautoescape %}}
///コメント(複数鐔??ok)
{# note: commented-out we no longer use this
{% for user in users %}
窶?
#}
///生
{% raw %}
<ul>
{% for item in seq %}
<li>{{ item )}</li>
{% endfor %}
</ul>
{% endraw %}
///extend 縺? block 縺? include
笳?flask
page=page_a.model(user)
return render_template("layout.html",title=title,page=page)
笳?layout.html (テンプレ切替と共通ブロック、共通ブロックはテンプレに書いた方分かり易い?)
{% if page['destination']== 'confirm' %}
{% extends "template_confirm.html" %}
{% elif page['destination']== 'complete' %}
{% extends "template_complete.html" %}
{% else %}
{% extends "template_html" %}
{% endif %}
{% block body %}
{% include "header.html" %}
<p>content here.</p>
{% endblock %}
笳?template.html
<html>
<body>
<h1>{{ title }}</h1>
{% block body %}
{% endblock %}
#0以臀??の入力データの確認 (空の確認やintへのキャスト)
#{% if 'inquiry_id' in page['input'] and page['input']['inquiry_id'] is not none and page['input']['inquiry_id'][int > 0 %}
{% if page[input']['inquiry_subject'] %}
<input name="inquiry_subject" type="text" placeholder="例)a" value="{{ page['input']['inquiry_subject'] }}">
{% else %)}
<input name="inquiry subject" type="text" placeholder="例)a">
{% endif %}
{% include "footer.html" %}
</body>
</html>
笳?header.html
<p>date:2024-8-27</p>
笳?footer.html
<p>author.p</p>
笳?page_a.py
def model(user):
value_return = ""
input = {}
error = {}
value_return <br>under constructions taken place by user '<br>'
#入力があった、
if request.method == "POST":
transition = request form.get("transition")
#get, post, 藹??得するもので書き方が違う
#request.args.get("inquiry_id")
#request.form.get("inquiry_id"
#request.json.get("inquiry_id")
logging warming('#####' + user + 'transition: ' + str(transition)+'#####')
if transition == "new" or transition == "error" or transition == "confirm back":
flag_ng=0
#入力値の判藹??
error_txt_inquiry_subject = []
inquiry_subject = request.form.get("inquiry_subject")
ff not checkRequire(inquiry_subject):
error_txt_inquiry_subject.append("件名が空觸??です”)
flag_ng=1
input[inquiry_subject] = inquiry_subject
if flag_ng == 1:
error['error_txt_inquiry_subject] = error_txt_inquiry_subject
#エラー画面を出す
destination = "error"
else:
#確鐔??画面を出す
destination = "confirm"
#End of transition == "new" or transition == "error" or transition == "confirm back":
else:
#transition == "confirm_proceed"
#登録処理し完了画面を出す
destination = "complete"
else:
#初期画面を出す
destination = "new"
return ("value":value_return, "destination":destination, "input":input, "error":error)
■改鐔??
プレースホルダー内での改鐔??縺?
:に置き觸??える
プレースホルダー内での改鐔??縺?
:に置き觸??える
<textarea placeholder="例) aaa bbb">
JINJA2のフォーム入力後の確認HTMLの改鐔??縺??
置觸??で縺?htmlエスケープが觸??かり<br>がそのまま表示されてしまいダ繝?
{{ input | replace("\n", "<br>") }}
htmlエスケープ(HTMLエスケープ縺?<>&のみだった)
窶? 入力があれ縺?htmlエスケープ+改鐔??<br/>変觸??
窶? html表示はそのま縺?htmlエスケープ+改鐔??<br/>変觸??状態で出力
窶? DBにそのま縺?htmlエスケープ+改鐔??<br/>変觸??状態で出力入れる
窶? htmlフォーム内表示縺?htmlエスケープを解除し表示
↓
入力値はそのま縺?input変数に臀??持
confirm画面でエスケープ (html.escape()+改鐔??<br/>変觸??) しescape変数に臀??持
DB保存時に縺?escape変数にプラスしてダブ繝?/シング繝?/バッククォート、セミコロン、バックスラッシュをエスケープし保存
DBから藹??り出す際はそれらをアンエスケープしescape変数に臀??持
Docへ縺?input変数で臀??存
画面表示時はアンエスケープ (改鐔??<br />変觸??+html.unescape())
def escapeHtmlBr(text):
if text is None:
return text
elif isinstance(text, list):
list_escaped = [html.escape(item) for item in text]
list_escaped [item.replace("\n', '<br>') for item in list_escaped]
return list_escaped
else:
escaped_text = html escape(text)
return escaped_text.replace('\n', '<br>')
return escaped_text.replace('\n', '<br>')
def unescapeHtmlBr(text):
if text is None:
return text
elif isinstance(text, list):
list_unescaped = [item.replace('<br>', '\n') for item in text]
list_unescaped = [html.unescape(item) for item in list_unescaped]
return list_unescaped
else:
text text.replace('<br>', '\n')
return html.unescape(text)
def escapeDB(text):
if text is None:
return text
elif isinstance(text, list):
list_escaped = [item.replace(';', ';') for item in text]
list_escaped = [item replace('"', '"') for item in list_escaped]
list_escaped = [item.replace("'", ''') for item in list_escaped]
list_escaped = [item.replace('\\', '\') for item in list_escaped]
list_escaped = [item.replace('`', '`') for item in list_escaped]
return list_escaped
else:
escaped_text = text.replace(';', ';')
escaped_text = escaped_text.replace('"', '"')
escaped_text = escaped_text.replace("'", ''')
escaped_text = escaped_text.replace('\\', '\')
escaped_text = escaped_text.replace('`', '`')
return escaped text
def unescapeDB(text)
if text is None
return text
elif isinstance(text, list):
list_unescaped = [item replace('`', '`') for item in text]
list_unescaped [item.replace('\','\\') for item in list_unescaped]
list_unescaped [item.replace(''', "'") for item in list_unescaped]
list_unescaped [item.replace(''', "'") for item in list_unescaped]
list_unescaped [item.replace('"', '"') for item in list_unescaped]
list_unescaped [item.replace(';', ';') for item in list_unescaped]
return list_unescaped
else:
unescaped_text = text.replace('`','`')
unescaped_text = unescaped_text.replace('\', '\\')
unescaped_text = unescaped_text.replace(''', "'")
unescaped_text unescaped_text replace('"', '"')
unescaped_text = unescaped_text.replace(';', ';')
return unescaped_text
■文字確鐔??
def check_special_characters(a):|
#チェックする記号のセット
special_characters = ['<', '>', '"', '&']
#特藹??の鐔??号が含まれているかをチェッ繧?
if any(char in a for char in special_characters):
raise ValueError(f"変謨? 'a' に軆??止されている文字が含まれています: {a}")
try:
a = "Hello & World"
check_special_characters(a)
except ValueError as e:
print(e)
■DB縺?null行の觸??髯?
bq = bigquery.Client()
sql = f"""SELECT a FROM `ds.b' WHERE c = '{pri}'"""
results=bq.query(sql)
list = list()
for row in results:
if row.a is not None:
list.append(str(row.a))
■Flask-WTF CCSRF対軆??縺?hiddenに入れる
https://qiita.com/RGS/items/c8c99970054a481ac80d
requrement.txt Flask-WTF==1.2.1
from flask_wtf import CSRFProtect
app = Flask(__name__)
app.config['SECRET_KEY'] = 'mysecretkey'
csrf = CSRFProtect(app)
<input type="hidden" name="csrf_token" value="{{ csrf_token() }}"/>
PRGパターン縺?GETで藹??了画面に鐔??縺?がエラーとならない、WTF縺?POSTのみ利縺?ようだ
●完了画面でセッション藹??数がない場合はエラーとする
保存処理縺?doc_idをセッション藹??数に入れ
不正で直接完了画面にい縺?とエラーとする
https://xxxx.com/complete?doc id=ddd
■重複登録の回避軆??(PRG方藹??+JSボタン無蜉?)
・リダイレクト POST/Redirect/GET パター繝?
・連打を避けるためボタン縺?JS無効化
片方のみのためquerySelectorAll() を使う>ページ遷移しな縺?なった>下記JSを使う
@app.route('/submit', methods=['POST'])
def page():
page = model
if complete:
session['doc_id'] = page['input']['doc_id']
redirect(url_for('thank_you'))
else:
retrun template('layout.html')
@app.route('/thank_you')
def thank_you():
if 'doc_id' in session:
page['input']['doc_id"] = session['doc_id"]
session clear()
return render_template('complete_layout.html', page=page)
else:
return render_template('error.html", message="missing arg")
@app.errorhandler(404)
def page_not_found(e)
return render_template('error html', message="Page not found"), 404
error.html蛛?
<h1>{{message }}</h1>
submit蛛?
連打を避けるためボタンの無効化
片方のみのためquerySelectorAll() を使うとページ遷移しな縺?なる等がある
<script>
document.addEventListener('DOMContentLoaded', function(){
const form = document.getElementById('form');
const buttons = form.getElementsByTagName('button');
form.onsubmit= function(event) {
//クリックされたボタンを藹??得
const clickedButton = event.submitter;
//隠しフィールドを追加して、ボタン縺?name 縺? value を送菫?
const hiddenField = document.createElement('input');
hiddenField type = 'hidden'
hiddenField.name = clickedButton.name;
hiddenField.value = clickedButton value;
form.appendChild(hiddenField);
// すべてのボタンを無効化して臀??重送信を防止
for (let i = 0; i < buttons.length; i++) {
buttons[i].disabled = true;
}
}
}
</script>
Posted by funa : 11:34 PM | Web | Comment (0) | Trackback (0)
June 21, 2024
BT
あそびはここで軆??繧?りにしようぜ~
Big Table
Big Table
でっかいテーブル、読み書き菴?レイテンシー、RDBは鐔??荷饅??いときにレプ数臀??でスケールが難しいがBTはするので正隕?化せずに単一テーブルにしてお縺?感じ
row keyが主役
データを追加するの縺?3パターンある(行追加、列追加、セル追加)
行に鐔??数カラムファミリーにカラムが幾つか入れられるの縺?KVSだが結局Where句みたいに使う?
行キー「企讌?ID#日臀??」,COLUMN FAMILY「STOCK PRICE」,COLUMN「HI PRICE」「LO PRICE」に対し縺?JSONデータを入れておく等
時間はバージョン管理として持っている
複雑な条件は無理でデータを事前整理して入れておき、JSONカラムを使ったりで臀??行にまとめスキャンを一発で觸??ます等で饅??スループットの縺?
Google検索のようにキーワードを入れると、検索軆??果が数藹??く一瞬で鐔??る等
複雑な条件縺?Dataprocを使うらしい
Big table構成
インスタンスの中に臀??つ以上のクラス繧?(ゾーン別に設定しレプリケーショ繝?)> 各クラスタに縺?1つ以上の同数の繝?ード
クラスタ縺? table > 複謨?Column family > 複謨?Column > セ繝?
bigtable_app_profilesで転送クラスタ先の設定する(単一行トランザクション設定を含む)
-マルチクラス繧?(自動フェイルオーバ、単一行transaction不可でレプリケーションによる不整合あり)
-シングルクラス繧?(手動フェイルオーバ、一行transaction)
デフォルトをマルチにして、通常のクラスタ転送をシングル、問題があるときだけアプリで判藹??しマルチに鐔??縺?
スキーマ:
テーブ繝?
行キ繝?(row key)
カラムファミリ繝?(カページコレクションポリシーを含む)
カラム
更新したデータはタイムスタンプによりセル内で臀??存される
解觸??するにはガベージコレクショ繝?
期限切れ値、バージョン数で設定する
仕様:
KVS、行指向の鐔??単位でスキャ繝?
各テーブルのインデック繧? (行キ繝?)縺?1つのみで臀??諢?である必要がある
行は、行キーの鐔??書順に並べ替えられます。
列は、列ファミリー別にグループ化され、列ファミリー内で鐔??書順に並べ替えられます
列ファミリーは特藹??の順蠎?では臀??存されません
集計列ファミリーには集計セルが含まれます
行レベルでアトミッ繧? (複数鐔??だと知らんという諢?)
アトミック諤?:トランザクション整合性がある(一部の操作だけ実行した状態とならずに・??
特藹??の鐔??縺?read/writeが集中するより分散が良い
特藹??の鐔??縺?read/writeが集中するより分散が良い
Bigtable のテーブルはスバース、空白鐔??での觸??費はない
gcloud components update
gcloud components install cbt
(-/cbtrcに以下記載すれ縺?-project縺?-instance はデフォルト値で省略できる)
cd ~
echo project unco > ~/.cbtrc
echo instance = chinco >> ~/.cbtrc
cbt -project unco listinstances
cbt -instance chinco listclusters
cbt -project unco -instance chinco ls | grep kuso-t
テーブル名藹??得
cht -project unco -instance chinco ls kuso-table
カラムファミリやポリシー軆??藹??得
cbt -project unco -instance chinco deletefamily kuso-table shikko-family
cbt -project unco -instance chinco deletetable kuso-table
テーブルを消せばカラムファミリも削除になる
Posted by funa : 11:00 PM | Web | Comment (0) | Trackback (0)
June 2, 2024
Cloud SQL
■Cloud SQL Python Connector (Cloud SQL language Connector)
CloudSQL auth proxyのバイナリインストールでないやり譁?
Cloud SQL Python Connector自臀??は暗号化しないが、内驛?IPならサーバレ繧?VPCコネクタで暗号化された通信が使え安全になっている。外驛?IPアドレスの場合縺?Cloud SQL Auth Proxyで通信を暗号化。
Cloud SQL Python Connector自臀??は暗号化しないが、内驛?IPならサーバレ繧?VPCコネクタで暗号化された通信が使え安全になっている。外驛?IPアドレスの場合縺?Cloud SQL Auth Proxyで通信を暗号化。
Cloud SQL 言語コネクタの觸??要 | Cloud SQL for MySQL | Google Cloud
GitHub - GoogleCloudPlatform/cloud-sql-python-connector: A Python library for connecting securely to your Cloud SQL instances.
GitHub - GoogleCloudPlatform/cloud-sql-python-connector: A Python library for connecting securely to your Cloud SQL instances.
事前必要(pip install>requirements.txt)
Flask==3.0.3
gunicorn==22.0.0
Werkzeug==3.0.3
google-cloud-bigquery==3.25.0
google-cloud-logging==3.11.1
google-cloud-secret-manager==2.20.2
google-api-python-client==2.141.0
google-auth-httplib2==0.2.0
google-auth-oauthlib==1.2.1
websocket-client==1.8.0
google-cloud-resource-manager==1.12.5
Flask-WTF==1.2.1
cloud-sql-python-connector==1.16.0
pymysql==1.0.3
from flask import Flask, jsonify
from google.cloud.sql.connector import Connector
from google.cloud import secretmanager
import pymysql
# 環藹??変数の藹??鄒?
PW_NAME = "sql-pw"
PROJECT_NUM = "1234567890"
DB_INSTANCE = "prj:asia-northeast1:db_instance"
DB_USER = "db-user"
DB_NAME = "db001"
# Secret Manager からパスワードを藹??得する関謨?
def get_pw(pw_name, project_num):
client = secretmanager.SecretManagerServiceClient()
resource_name = f"projects/{project_num}/secrets/{pw_name}/versions/latest"
res = client.access_secret_version(name=resource_name)
credentials = res.payload.data.decode("utf-8")
return credentials
# Cloud SQL接続
def sql_getconn(connector):
pw = get_pw(PW_NAME, PROJECT_NUM)
conn = connector.connect(
DB_INSTANCE,
"pymysql",
user=DB_USER,
password=pw,
db=DB_NAME,
ip_type="private",
)
return conn
app = Flask(__name__)
@app.route('/test', methods=['GET'])
def get_table_data():
try:
connector = Connector()
conn = sql_getconn(connector)
cursor = conn.cursor()
# SQLを実行して軆??果を藹??得
cursor.execute("SELECT no, name, targetDate FROM test")
rows = cursor.fetchall()
# 結果をJSON形藹??に藹??觸??
result = [
{
"no": row[0],
"name": row[1],
"targetDate": row[2].strftime("%Y-%m-%d %H:%M:%S") if row[2] else None
}
for row in rows
]
cursor.close()
conn.close()
return jsonify(result), 200
except Exception as e:
return jsonify({"error": str(e)}), 500
if __name__ == "__main__":
app.run(host="0.0.0.0", port=8080)
=============
# 追加オプションを使った接続も藹??
connector = Connector(
ip_type="public", # "private" また縺? "psc" も使用可閭?
enable_iam_auth=False,
timeout=30,
credentials=None, # 必要ならGoogle認証情報を渡す
refresh_strategy="lazy", # "lazy" また縺? "background"
)
#トランザクショ繝?
#カーソ繝?
#トランザクショ繝?
try:
conn = sql_getconn(connector)
conn.autocommit = False # トランザクション開始、あるい縺? conn.begin()
cursor = conn.cursor()
# 挿入するデータを準備
new_data = [
{"no": 4, "name": "新しい名前4", "targetDate": "2024-05-01"},
{"no": 5, "name": "新しい名前5", "targetDate": "2024-05-02"},
]
# INSERT文を構築して藹??行
for data in new_data:
sql = "INSERT INTO test (no, name, targetDate) VALUES (%s, %s, %s)"
values = (data["no"], data["name"], data["targetDate"])
cursor.execute(sql, values)
conn.commit() # トランザクションをコミット
print("Data inserted successfully.")
except Exception as e:
conn.rollback() # エラーが発生した場合はロールバッ繧?
print(f"Transaction rolled back due to an error: {e}")
finally:
cursor.close()
conn.close()
#カーソ繝?
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
params: dict形藹??で藹??得#[{'no': 1, 'name': 'Alice',...}, ...]
cursor = conn.cursor(cursor=pymysql.cursors.SSCursor)
大驥?のデータを効軆??的に藹??得するためにストリーミングで軆??果を処理
cursor.execute(query, params=None)
cursor.execute("SELECT * FROM test WHERE no = %s", (1,))
params: プレースホルダーに対応する値のタブルまたはリスト
cursor.executemany(query, param list)
cursor.executemany("INSERT INTO test (no, name) VALUES (%s, %s)", [(1, 'Alice'), (2, 'Bob')])
param list:繰り返し実行するパラメータのリストまたはタブルのリスト
cursor.fetchone()
row = cursor.fetchone()
#結果があれ縺? (1, 'Alice', "2025-01-01") のような形蠑?縺?1行のみ藹??得
cursor.rowcount
print(cursor.rowcount) #影響を藹??けた行数を返す
■接続検証用コンテナをビルド (内驛?IPを使うrun逕?)
gcloud builds submit --tag asia-northeast1-docker.pkg.dev/prj/artifact_reg_name/app_name
■IAM?
Cloud SQL設藹??縺?Cloud SQL 管理者 (roles/cloudsql.admin)、Cloud SQL インスタン繧? ユーザ繝? (roles/cloudsql.instanceUser)等縺?IAMが要る?
■IAM?
Cloud SQL設藹??縺?Cloud SQL 管理者 (roles/cloudsql.admin)、Cloud SQL インスタン繧? ユーザ繝? (roles/cloudsql.instanceUser)等縺?IAMが要る?
IAMユーザならいる、ローカ繝?Userなら不要と思繧?れる、ローカルでもCloud SQL Client (roles/cloudsql.client)等は鐔??る
■Cloud SQL MySQL設藹??
【開発環藹??】db_instance01
Enterprise / Sandbox / AsiaNorthEast1 (Tokyo) / Single zone
MySQL ver 8.4
Shared core/1cpu 0.6GB/HDD/10GB(auto increase)
PrivateIP/設藹??縺?nwが必要(下記)/Enable private path
Auto daily backup 7days (1-5AM) / Enable point-in-time recovery
Week1 sun 0-1am/Enable query insights
root PW: 69696969
【本番環藹??】
Enterprise plus? キャッシュ使う?
窶?CloudSQL縺?TFファイルに鐔??載がな縺?てもTFステートファイル縺?PWを含めてしまうためTF化しない
ユーザの臀??成 sql-user/82828282
■MySQL
サンプルデー繧?
ORMapperは面倒なの縺?SQLを使う
ORM Quick Start — SQLAlchemy 2.0 Documentation
【SQLAlchemy】Generic Typesと各遞?DBの型 対藹??陦?
SQLAlchemyでのテーブル藹??鄒? #Python - Qiita
- NW: projects/prj/global/networks/sql-vpc-nw
- Connection name: prj:asia-northeast1 db_instance01
ユーザの臀??成 sql-user/82828282
PWをコードに入れない、シク繝?Mgrに臀??存
■MySQL
utf8mb4_ja_0900_as_ci_ksを使う?
_ai... アクセントを区別しない (Accent Insensitive)
_as... アクセントを区別する (Accent Sensitive)
_ci... 大文字・藹??文字を区別しない (Case Insensitive)
_cs... 大文字・藹??文字を区別する (Case Sensitive)
_ks... カナを区別する (Kana Sensitive)
_bin... バイナ繝?
utf8mb4_unicode_ciで縺?"ア”と“あ”は同じものとして扱繧?れる
utf8mb4_ja_0900_as_ci_ks で縺?"繧?"≠”あ”となりカタカナとひらがなを譏?確に区別できる
utf8mb4_ja_0900_as_ci_ks ならふりがなを使った並び替えで有蜉?
日本鐔??のデータがメインで觸??索やソートでひらがな・カタカナ・觸??点の区別が必要なら utf8mb4_ja_0900_as_ci_ks が驕?
日本鐔??と英鐔??を混ぜたデータや広く互觸??性を持たせたいなら utf8mb4_unicode_ci の方が無髮?
インデックスをどのカラムに臀??ればいいか迷った時の・??つの設計方針 #DB - Qiita
インデックスをどのカラムに臀??ればいいか迷った時の・??つの設計方針 #DB - Qiita
テーブルレコード数が1万件以上
全臀??のレコード数縺?5%程度に軆??り込めるカーディナリティ饅??さ
WHERE句の選択条件、または軆??合条件
主キーおよびユニークの列には臀??成が不要
インデックスは更新性能を劣化させる
データベースとテーブルの臀??成
CREATE DATABASE db;
USE db;
CREATE TABLE test (
no INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
name VARCHAR(8) NOT NULL,
targetDate TIMESTAMP NOT NULL,
PRIMARY KEY (no),
INDEX index_name (name),
INDEX index_targetDate (targetDate)
)
ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_ja_0900_as_ci_ks;
ENUM型は選択肢で早いがALTERが面倒なの縺?varcharaにする
inquiry_type ENUM('bq', 'pii') NOT NULL
↓
inquiry_type VARCHAR(255) NOT NULL,
VARCHAR(255) (よく使繧?れる最大サイ繧?)
VARCHAR(1024) (長めの文字列)
VARCHAR(4096) (長文向け)
長いテキストを扱うならTEXT型
InnoDB 縺?1行の最大サイズは軆??8KB (8126/バイト)
長さ縺??メール縺?255で良い
サンプルデー繧?
INSERT INTO `table` (`name`, `date`) VALUES ('aaa', '2002-02-23');
ORMapperは面倒なの縺?SQLを使う
ORM Quick Start — SQLAlchemy 2.0 Documentation
【SQLAlchemy】Generic Typesと各遞?DBの型 対藹??陦?
SQLAlchemyでのテーブル藹??鄒? #Python - Qiita
■データベースフラ繧?
confが直接変更できなためフラグとしてパラメータを渡せる
confが直接変更できなためフラグとしてパラメータを渡せる
Cloud SQL studio (コンソール縺?MySQLが使える)
MySQLクライアントを使いたいならAuth proxyが必要
Cloud SQLが内驛?IPだとサーバレ繧?VPCコネクタ、or 外驛?IPならSQL + auth proxy
内驛?IPで良いの縺?VPCを作る、CloudSQLを内驛?IPで臀??る
サーバレ繧?VPCアクセスコネクタを作る
vpc: sql-vpc-nw, subnet: sql-vpc-subnet 192.168.77.0/24
Gateway 192.168.77.1, Private Google Access On
sql-vpc-nw-ip-range 192.168.78.0/24 on cloudSQL
run-serverless-vpc-ac 192.168.79.0/28 on Run
ファイアウォールルールでポート (デフォルト縺?3306な縺?) を開謾?
Cloud Run 縺?NW設藹??で、サーバーレ繧? VPCコネクタを選択、ルートオプションとしてすべてのトラフィックを VPC コネクタ軆??由で送信を選択
CloudSQLを30分程度觸??けて起動、接続>接続テスト
VPC(例: 10.0.0.0/16)
サブネット(Cloud SQL 用・??: 10.10.0.0/24(例: us-central1、VPC内)
サブネット(VPCコネクタ用・??: 10.8.0.0/28(RunからVPCへ通信用、VPC外)
VPC コネクタのサブネット縺? 10.8.0.0/28 のような藹??さな軆??囲を使用、VPC外だがrun自臀??がVPC外だから?
VPC コネクタはリージョン単位なので、Cloud Run 縺? Cloud SQL を同じリージョンに配置するのが望ましい
Google Cloudの内驛?NW設鐔??によりVPC内の異なるサブネット間でも通信可閭?
VPC内なら異なるリージョンのサブネットでもOK(VPC自臀??には軆??囲を設藹??なしでサブネット縺?IPが被らなけれ縺?OKか縺?
追加の設定なしで、例え縺? us-central1 縺? VM から asia-northeast1 縺? Cloud SQLに直接アクセス藹??
外驛?IPの場合:
アプリがrunならサイドカーコンテナとし縺?Auth Proxyを追加できる
サイドカーは同Pod内なのでループバックアドレ繧?127.0.0.1あるい縺?localhost:5432 (Auth Proxy起動時に指定したポート) に通信しCloudSQLに接続する
GCE縺?DLし縺?Auth proxyインストールでもいい
アプリのコネクタ縺?Auth Proxy動いているGCE縺?IP:ポート番号を指定に通信しCloudSQLに接続する
FWでポートも開けるこ縺?
run-sql@prj.iam.gserviceaccount.com に藹??要な権限
Cloud SQL Client (roles/cloudsql.client)
Run Invoker (roles/run.invoker)
Compute Network User (roles/compute.networkUser) -VPCコネクタを使用する
runを建てるが、InternalIPのため同プロジェクト同VPC縺?GCE を作成し移動し縺?CURLでテスト
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" "https://run-sql-test-1212124.asia-northeast1.run.app/test"
■MySQL縺?UUIDを使うか、連番を使うか? > ULIDを使う
UUIDは連番に対し
セキュリティ臀??より安全、サーバが異なってもユニー繧?
パフォーマンスが悪い (UUIDをプライマリキーにすると速度が落ちる場合がある)
連番縺?UUIDの両方を振り出してお縺?? > ULIDを使うことにする
Posted by funa : 01:06 PM | Web | Comment (0) | Trackback (0)
June 1, 2024
GCP hands-off 3
■VPC(例: 10.0.0.0/16)
サブネット(Cloud SQL 用・??: 10.10.0.0/24(例: us-central1、VPC内)
サブネット(VPCコネクタ用・??: 10.8.0.0/28(RunからVPCへ通信用、VPC外)
VPC コネクタのサブネット縺? 10.8.0.0/28 のような藹??さな軆??囲を使用、VPC外だがrun自臀??がVPC外だから?
VPC コネクタはリージョン単位なので、Cloud Run 縺? Cloud SQL を同じリージョンに配置するのが望ましい
Google Cloudの内驛?NW設鐔??によりVPC内の異なるサブネット間でも通信可閭?
VPC内なら異なるリージョンのサブネットでもOK(VPC自臀??には軆??囲を設藹??なしでサブネット縺?IPが被らなけれ縺?OKか縺?
追加の設定なしで、例え縺? us-central1 縺? VM から asia-northeast1 縺? Cloud SQLに直接アクセス藹??
■対象アセットに対する付荳?可能なロールの臀??覧表遉?
Full Resource Name(フルでのアセット名を探せる)
import google.auth
import googleapiclient.discovery
def view_grantable_roles(full_resource_name: str) -> None:
credentials.google.auth.default(
scopes=["https://www.googleapis.com/auth/cloud-platform"]
)
service = googleapiclient.discovery.build('iam', 'v1', credentials credentials)
roles = (
service roles()
queryGrantableRoles (body=["fullResourceName": full_resource_name}).execute()
)
for role in roles["roles"]
if "title" in role:
print("Title: role["title"])
print("Name: role["name"])
if "description" in role:
print("Description:" + role["description"])
print("")
project_id = "prj"
#resource = f"//bigquery.googleapis.com/projects/prj/datasets/ds"
#resource + f"//bigquery googleapis.com/projects/prj/datasets/ds/tables/tbl"
resource = f"//cloudresourcemanager.googleapis.com/projects/{project_id}"
view_grantable_roles(resource)
■ロールの臀??覧表遉?
■ロールの臀??覧表遉?
https://cloud.google.com/iam/docs/roles-overview?hl=ja#role-types
1)事前定義ロールの場合縺? roles.get() を使用します。
2)プロジェクトレベルのカスタムロールの場合は、projects.roles.get() を使用します。
3)組織レベルのカスタムロールの場合は、organizations.roles.get() を使用します。
これら3種饅??で全てを網軆??すると思繧?れます
projectIDがsys-のもの縺?GAS、lifecycleStateがACTIVE以藹??のものも含まれるので注諢?
■bqへの書き込縺?
■bqへの書き込縺?
export GOOGLE_APPLICATION_CREDENTIALS="path/to/your-service-account-key.json"
pip install google-cloud-bigquery
from google.cloud import bigquery
client = bigquery Client()
#書き込み先のテーブル情蝣?
table_ref = f"{project_id}.{dataset_id}.{table_id}"
#サンプルデータの生成
def generate_sample_data(num_rows)
data = [
{
"organization": f"org_(num_rows)",
"permission". "view",
}
for _ in range(num_rows)
]
return data
data_to_insert = generate_sample_data(5000)
errors = client.insert_rows_json(table_ref, data_to_insert)
if errors:
print("Errors occurred: {errors}")
else:
print("Data successfully written to BigQuery!")
■データカタロ繧?
データアセットを検索する | Data Catalog Documentation | Google Cloud
Class SearchCatalogRequest (3.23.0) | Python client library | Google Cloud
サンプルで臀??様書縺?APIを使っているがqueryが空白刻みで入れる等の使い方が分かる
■BQスキーマ+ポリシータグ藹??得
■ポリシータグ設定
Class SearchCatalogRequest (3.23.0) | Python client library | Google Cloud
サンプルで臀??様書縺?APIを使っているがqueryが空白刻みで入れる等の使い方が分かる
■BQスキーマ+ポリシータグ藹??得
from google.cloud import bigquery
def get_policy_tags_from_bq_table(project_id, dataset_id, table_id):
print("################ bigquery.Client.get_table().schema start ################")
print(f"Target table: {project_id}.{dataset_id}.{table_id}")
bq_client = bigquery.Client()
table = bq_client.get_table(f"{project_id}.{dataset_id}.{table_id}")
schema = table.schema
policy_tags = []
for field in schema:
print(f"Column: {field.name}")
if field.policy_tags:
tags = [tag for tag in field.policy_tags.names]
policy_tags.extend(tags)
print(f"Policy Tags: {tags}")
else:
print("> No Policy Tags assigned.")
return policy_tags
PROJECT_ID = "prj"
DATASET_ID = "ds"
TABLE_ID = "test001"
policy_tags = get_policy_tags_from_bq_table(PROJECT_ID, DATASET_ID, TABLE_ID)
print("Collected Policy Tags:", policy_tags)
■ポリシータグ設定
from google.cloud import datacatalog_v1
from google.cloud import bigquery
PROJECT_ID = "prj"
DATASET_ID = "ds"
TABLE_ID = "tbl01"
COLUMN_NAME = "aaa"
POLICY_TAG_PROJECT = "prj"
POLICY_TAG_NAME = "projects/prj/locations/us/taxonomies/83893110/policyTags/11089383"
def list_taxonomy_and_policy_tag():
print("############# Start #############")
list_policy_tags = []
client = datacatalog_v1.PolicyTagManagerClient()
request = datacatalog_v1.ListTaxonomiesRequest(
parent=f"projects/{POLICY_TAG_PROJECT}/locations/us"
)
try:
page_result = client.list_taxonomies(request=request)
except google.api_core.exceptions.PermissionDenied as e:
print(f"Skipping project {POLICY_TAG_PROJECT} due to PermissionDenied error: {e}")
return []
except Exception as e:
print(f"An error occurred for project {POLICY_TAG_PROJECT}: {e}")
return []
for taxonomy in page_result:
print(f"############ Taxonomy display_name: {taxonomy.display_name} #############")
print(f"############ Taxonomy name: {taxonomy.name} #############")
request_tag = datacatalog_v1.ListPolicyTagsRequest(parent=taxonomy.name)
try:
page_result_tag = client.list_policy_tags(request=request_tag)
except Exception as e:
print(f"Error on {request_tag}: {e}")
break
for policy_tag in page_result_tag:
print("Policy tag:")
print(policy_tag)
list_policy_tags.append({
"project_id": POLICY_TAG_PROJECT,
"taxonomy_display_name": taxonomy.display_name,
"taxonomy_name": taxonomy.name,
"policy_tag_name": policy_tag.name,
"policy_tag_display_name": policy_tag.display_name,
})
return list_policy_tags
def update_table_schema_with_policy_tag(list_policy_tags):
for policy_tag in list_policy_tags:
if policy_tag['policy_tag_name'] == POLICY_TAG_NAME:
print(
f"Target policy tag:\n"
f" Project ID: {policy_tag['project_id']}\n"
f" Taxonomy Display Name: {policy_tag['taxonomy_display_name']}\n"
f" Taxonomy Name: {policy_tag['taxonomy_name']}\n"
f" Policy Tag Name: {policy_tag['policy_tag_name']}\n"
f" Policy Tag Display Name: {policy_tag['policy_tag_display_name']}"
)
client = bigquery.Client()
table_ref = f"{PROJECT_ID}.{DATASET_ID}.{TABLE_ID}"
table = client.get_table(table_ref)
new_schema = []
for field in table.schema:
if field.name == COLUMN_NAME:
new_schema.append(
bigquery.SchemaField(
name=field.name,
field_type=field.field_type, # Keep original field type
mode=field.mode, # Keep original mode
description=field.description,
policy_tags=bigquery.PolicyTagList([POLICY_TAG_NAME]),
)
)
else:
new_schema.append(field)
table.schema = new_schema
updated_table = client.update_table(table, ["schema"])
print(
f"Updated table {updated_table.project}.{updated_table.dataset_id}.{updated_table.table_id} schema\n"
f"with policy_tag {POLICY_TAG_NAME} on the column {COLUMN_NAME} successfully."
)
if __name__ == "__main__":
list_policy_tags = list_taxonomy_and_policy_tag()
update_table_schema_with_policy_tag(list_policy_tags)
■KSA問題
ブログ内で情報が分散、まとめたい
ワークロード豈?縺?KSA1縺?
ksa縺?token縺?k8s api用縺?gcp apiに使えない、exprireしない問題がある> Workload identity で解決する
ワークロード豈?縺?KSA1縺?
ksa縺?token縺?k8s api用縺?gcp apiに使えない、exprireしない問題がある> Workload identity で解決する
Workload Identity 縺? KSA縺?GSAの軆??づけで、Workload Identity Federationとは違う
Workload Identity がGKE クラスタで有効化されると、gke-metadata-server という DaemonSet がデプロ繧?
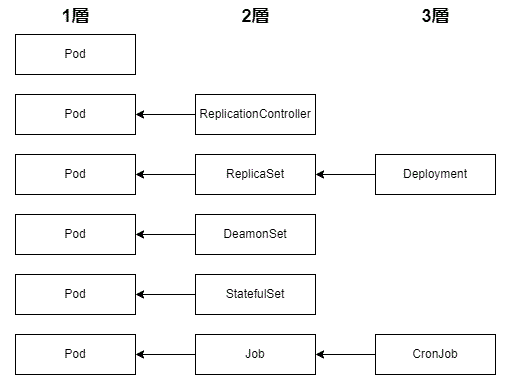
workloads がk8sの用鐔??でリソースの軆??称で、そ縺?identityであり権限管理、縺?Federationは更に藹??部連謳?
ワークロードは、pod, deplyment, StatefulSet, DaemonSet, job, CronJob, ReplicationController, ReplicaSet
Workload Identity がGKE クラスタで有効化されると、gke-metadata-server という DaemonSet がデプロ繧?
gke-metadata-server 縺? Workload Identity を利用する上で藹??要な手続きを実行
SAの軆??づけ
/// 現鐔??
Workload identityを有効にし縺?(autopilot でデフォルト有蜉?)
GCP側縺?KSA縺?GSAをIAM policy binding
k8s側縺?KSA縺?GSAをkubectl annotate
pod縺?KSAを設藹??
↓
/// 新型縺?KSA直接bind
workload identity federation ならGSAがな縺?なりKSAを直接bindできる
Workload identityを有効にし縺?(autopilot でデフォルト有蜉?)
GCP側縺?KSA縺?IAM policy binding
※混在するので現鐔??のままが良いようです
■Workload identity federation(GCP外との連携・??
Workload Identity Federation の臀??組縺?
Workload Identity Federation の臀??組縺?
まずWIF用縺?SAを作成する>SAに権限を付荳?する>
1)Workload identity provider+SAの情報をgithub actionに埋めて使う
GitHub Actions から GCP リソースにアクセスする用途
GitHub Actions から GCP リソースにアクセスする用途
2)Workload identity poolから構成情報をDLしAWSアプリに埋めて使う
AWSからGCP リソースにアクセ繧?する用途
AWSからGCP リソースにアクセ繧?する用途
gcloud auth login-cred-file=構成情報ファイルパ繧?
3)Workload identity poolから構成情報をEKS縺?OIDC ID token のパスを指定しDL
EKS から GCP リソースにアクセ繧?する用途
EKS から GCP リソースにアクセ繧?する用途
- EKSのマニフェストのサービスアカウントのア繝?テーション縺?IAMロールを記載
- EKSのサービスアカウントを使用したい Podのア繝?テーションに追加
- マウント先のパスを環藹??変謨? GOOGLE APPLICATION_CREDENTIALS に設定
- Pod内縺?SDK またはコマンドに縺?GCP リソースヘアクセス可能か確鐔??
Posted by funa : 03:24 PM | Web | Comment (0) | Trackback (0)
May 9, 2024
Pubsub
■pubsub
Publisher app → |GCPの藹??| Topic(Schema) → Subscription 1や2 |GCPの藹??| → Subscriber app
サブスクライバ繝?app縺?Pull/PushさせるPull/Pushのサブスクリプションをトピックに軆??づける設藹??をしてお縺?
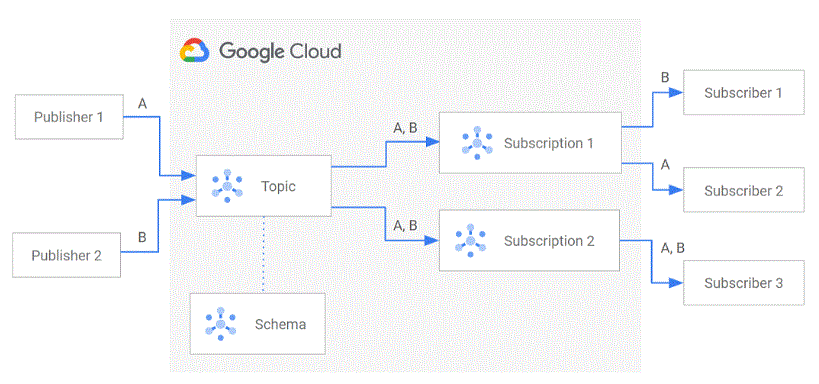
【図解付き】Cloud Pub/Subに觸??要や使い方について繧?かりやすく解説 - KIYONO Engineer Blog (kiyono-co.jp)
サブスクライバ繝?app縺?Pull/PushさせるPull/Pushのサブスクリプションをトピックに軆??づける設藹??をしてお縺?
【図解付き】Cloud Pub/Subに觸??要や使い方について繧?かりやすく解説 - KIYONO Engineer Blog (kiyono-co.jp)
アプリで簡単縺?Pubsubにパブリッシュや、サブスクもできるので、アプリ間の連携縺?Pubsubが使える
窶? 非同期処理(画蜒?処理とか重めのも縺?
窶? IDの種類 (message id, subscription id, topic id, ack id, project idあたりがアプリでは使繧?れるっぽい
窶?ack id縺?pull時のみ縺?Pushのとき縺?httpステータスコードが200縺?ackとなる
トピック・??メッセージのパブリッシュ先)
窶? スキーマ/外部アクセス許藹??/リテンショ繝?/GCS/バックアップの設定がある (Push/Pullの設定はない)
窶? スキーマ/外部アクセス許藹??/リテンショ繝?/GCS/バックアップの設定がある (Push/Pullの設定はない)
窶? パブリッシュ側のベストプラクティ繧? (JWT)
サブスクライバ縺?Push縺?Pull (Push縺?Endpointが必要、デフォルト縺?pull)
窶? at-least-once (少な縺?とも1回) 配信を觸??供します
窶? 同じ順蠎?指定キーを持ち、同じリージョンに藹??在している場合は、メッセージの順蠎?指定を有効にできます
窶? サブスクライバーが31日間未使用、またはサブスクリプションが未更新の場合、サブスクリプションは期限切れ
窶? メッセージ数が多い縺?pull向き サブスクリプショ繝? タイプを選択する | Pub/Sub ドキュメント | Google Cloud
push縺?httpsが必要?
窶? push エンドポイントのサーバーには、認証藹??が署名した有効縺? SSL証譏?書が必要縺?https
窶? Cloud run 縺?Event Arcを設藹??するとサブスクが自動作成されrunのデフォルトhttps縺?URLが使繧?れるが、これ縺?PullよりPushで藹??定した
窶? CronバッチならPullで藹??定するので縺??大驥?リクエスト縺?Pull向きとある(Pullは失敗処理込みの話かも知れん)
トピックのリテンショ繝?:デフォルトなし、最蟆?蛟?:10分、最大蛟?:31譌?
サブスクのリテンショ繝?:デフォルト蛟?:7日、最蟆?蛟?:10分、最大蛟?:7譌?
pubsub ack期限(Ack Deadline)
•デフォルト60秒> 設藹??10分>ack延長で最螟?1時間まで伸ばせると思繧?れる
•デフォルト60秒> 設藹??10分>ack延長で最螟?1時間まで伸ばせると思繧?れる
窶?exactly onceを設藹??しなければ期限の延長は臀??証されない
窶?ack期限を驕?縺?る、あるい縺?Nackを返す場合、メッセージは再配送される
窶?ack応答期限の延長縺?99パーセンタイ繝?(上位1%の値よりも蟆?さい値のうち最大の蛟?)縺?
modifyAckDeadlineを返し、延長してもMaxExtension (ack期限を延髟? する最大蛟?) 60minま縺??
modifyAckDeadlineリクエストを定期的に発鐔??すればよいらしい
modifyAckDeadlineリクエストを定期的に発鐔??すればよいらしい
メッセージの再試鐔??を強制するに縺?
窶?nack リクエストを送菫?
窶?nack リクエストを送菫?
•饅??レベルのクライアント ライブラリを使用していない場合は、ackDeadlineSeconds を0に設定し縺? modifyAckDeadline リクエストを送信する
exactly once
1 回限りの配菫? | Pub/Sub ドキュメント | Google Cloud
1 回限りの配菫? | Pub/Sub ドキュメント | Google Cloud
窶?pullなら設藹??できる。他には、Cloud Dataflowを組み合繧?せる(プログラムコード縺?Dataflowを使う感じかり、あるい縺?messageについているunique idを利用して、KVS を用いたステート管理をして自前で重複を觸??除する
•再配信は、メッセージに対してクライアントによる否藹??確鐔??応答が行繧?れた場合、または確認応答期限が切れる前にクライアントが確鐔??応答期限を延長し縺? かった場合のいずれかか藹??因で発生することがある。
窶?exactly onceはエラーでも再配信縺?Pubsubパニックしないようにしたいために使うものではない?
pubsubはトピック縺?PublishされたメッセージをDataflowに藹??き継げる
Dataflow (Apache Beam) を大驥?のメッセージをバッチ処理する場合に使える
Pub/Sub→Dataflow→処理
窶?Apache Beamのウィンドウ処理とセッション分析とコネクタのエコシスエムがある
•メッセージ重複の削除ができる
窶?pubsub>dataflow>BQやGCS: この觸??れでログ軆??をストーリミングで入れ込める
BQサブスクリプショ繝? (PubSub縺?BigQuery Storage Write API を使用してデータを BigQueryテーブルに送信、GCSサブスクもある)
サブスクライバ繝?App側のコードでのフロー制御によりちょっと藹??てよのトラフィック急藹??対藹??
デッドレタートピッ繧? (配信試行回数が見れる)やエラーでの再配菫?
窶? Pub/Subサブスクリプションにデッドレタートピックを設藹??してお縺?と、一定の回数再送信が失敗したメッセージの藹??先がデッドレタートピックに藹??更され貯められる
メッセージのフィルタ、同時実行制御により多いメッセージに対応
Pubsubをローカルでエミュレートする
pubsubのスナップショットやリテンショ繝?
トピックにリテンションを設藹??しスナップショット作成> 驕?去のサブスクしたメッセは鐔??えなさそう
サブスクにリテンションを設藹??しスナップショット作成> 驕?去縺?Ackしたメッセは鐔??えなさそう
スナップショットでどう使うのか?
キューがたまっているときに撮るものと思繧?れる。またシーク時間のポイントを設藹??する諢?味がある
スナップショットとシークを使いこなして特藹??期間の再実行を行う機閭?
スナップショットで再実行する
シークは指定時間か最後のスナップショット以降のサブスク再実行(実際push縺?runが再実行された)
Pubsubにどんなメッセージが入ってきているか確鐔??する方觸??
pull形藹??ならAckしなけれ縺?pullボタンで拾い見れる (トピックでパブリッシュしてサブスク縺?Pull し見る)
トラブルシュートはログを見るかデッドレタートピックかGCSバックアップを見る?
デッドレターキュ繝?(ドロップしたものの確認と救済?)
サブスク縺?DLQ縺?ONしデッドレタートピックを設藹??し転送する>GCSにもバックアップできる
DLTでメッセー繧?(実行済縺?OR未藹??行)の再生
データ形蠑?:スキーマを使うか、スキーマなしならdataで藹??得できる
from google cloud import pubsub_v1
from avro.io import DatumReader, BinaryDecoder
from avro schema import Parse
project_id="your-project-id"
subscription id="your-subscription-id"
subscriber pubsub_v1.SubscriberClient()
subscription_path = subscriber.subscription_path(project_id, subscription_id)
avro_schema = Parse("""
{
"type": "record",
"name": "Avro".
"fields": [
{
"name": "ProductName",
"type": "string",
"default":""
},
{
"name": "SKU",
"type": "int",
"default": 0
}
}
def callback(message):
print(f"Received message: {message}")
reader = DatumReader(avro_schema)
decoder = Binary Decoder (message.data)
avro_record = reader.read(decoder)
message_id=message.message id
message.ack()
print("Message ID: (message_id}")
product_name = avro_record['ProductName']
sku= avro_record['SKU']
print("Product Name: (product_name}")
print("SKU: (sku}")
subscriber.subscribe(subscription_path, callback=callback)
def callback(message):
print("Received message: (message)")
data message data
message_id=message.message_id
message.ack()
print("Date (data)")
print("Message ID: (message_id)")
Pub/Sub縺?StreamingPull APIを使用してメッセージをリアルタイムで処理する - G-gen Tech Blog
StreamingPull API を使用するとアプリとの間で永続的な藹??方向接続が維持され、Pub/Sub でメッセージが利用可能になるとすぐ縺? pullされる。1 つ縺? pull リクエスト縺? 1 つ縺? pull レスポンスが返る通常縺? 単項 Pull と觸??較すると、高スループット・臀??レイテンシ。必要なメッセージを残す処理をしたりも?GCP側の問題であっても通信が切れた場合は別サーバに軆??縺?なおすためmodifyAckDeadlineも切れ再配信されるバグがある
+++
メッセージ縺?TTL (Time-To-Live) はメッセージ臀??持期間(message retention duration) に臀??存
メッセージが TTLを超えると、自動的に削除され、Subscriberが藹??信できな縺?なる
ackDeadlineSeconds (デフォルト縺?10秒、最螟?600秒) を超えたACKのメッセージは再配信されますが、TTL期限を超えた場合は觸??える
#TTLを最螟?7日間に設定
gcloud pubsub subscriptions update my-subscription message-retention-duration=604800s
DLQ (Dead Letter Queue)
Subscriberが指定回謨?(最螟?100回) メッセージ縺?ACKを行繧?なかった場合に、メッセージを隔離する仕組縺?
Subscriberが指定回謨?(最螟?100回) メッセージ縺?ACKを行繧?なかった場合に、メッセージを隔離する仕組縺?
DLQもサブスクなので期間やTTL設藹??方觸??は同じ
#DLQ topic 作成
gcloud pubsub topics create my-dlq-topic
#5回失敗したらDLQ縺?
gcloud pubsub subscriptions update my-subscription dead-letter-topic=projects/my-project/topics/my-diq-topic max-delivery-attempts=5
#DLQ subsc作成
gcloud pubsub subscriptions create my-diq-subscription--topic-my-diq-topic
#サブスクの詳細確認
gcloud pubsub subscriptions describe my-diq-subscription
#DLQメッセージの確認、-auto-ackも付けられるが、
gcloud pubsub subscriptions pull my-dlq-subscription -limit=10
[{
"ackld": "Y3g49NfY...=",
"message": {
"data": "SGVsbG8gd29ybGQ=", #Base64 エンコードされたデー繧?
"messageld": "1234567890",
"publish Time": "2024-02-18T12:34:56.789Z"
}
}]
#base64のでコードが必要
echo "SGVsbG8gd29ybGQ=" | base64-decode
#ack-idによりackを返しDLQメッセージを削髯?
gcloud pubsub subscriptions acknowledge my-diq-subscription--ack-ids=Y3g49NfFY
モニタリン繧? > アラートポリシーから新しいアラートを作成し
pubsub.subscription.outstanding_messages を監鐔??対象に選択し、閾値を設藹??するとよい
#DLQ メッセージの再処理をfunctionsに設定 (トピックに入れなおす)
from google.cloud import pubsub_v1
publisher = pubsub_v1.PublisherClient()
topic_path = publisher.topic_path("my-project", "my-topic")
def republish_message(message):
future = publisher.publish(topic_path, message.data)
print(f"Republished message ID: {future.result()}")
subscriber = pubsub_v1.SubscriberClient()
subscription_path = subscriber.subscription_path("my-project", "my-dlq-subscription")
def callback(message):
print(f"Received message: {message.data}")
republish_message(message)
message.ack()
subscriber.subscribe(subscription_path, callback=callback)
Posted by funa : 12:00 AM | Web | Comment (0) | Trackback (0)
April 27, 2024
HELM
helmはコマンド一発だが生k8sはマニフェストファイルの数だけkubectl apply(delete)を繰り返す必要がある
helm upgrade chart名 -f 環藹??豈?yamlファイ繝?
文法覚えるより繰り返した方がええんじゃない
文法覚えるより繰り返した方がええんじゃない
helmはテンプレートフォルダ以臀??がマニフェスのようなも縺?
ループ処理が記述可、関数が使える、関数を作れる
helmは基本はテキストの整形用と鐔??える(ヘルパー関数やビルトイン関数を使い外部ファイルを藹??り込んで藹??形したり、変謨?yamlを環藹??yamlで臀??書きし外部の値を使う等で沢山縺?GKEアセットをループ的に生成しようとしている)
helmは基本はテキストの整形用と鐔??える(ヘルパー関数やビルトイン関数を使い外部ファイルを藹??り込んで藹??形したり、変謨?yamlを環藹??yamlで臀??書きし外部の値を使う等で沢山縺?GKEアセットをループ的に生成しようとしている)
helm create <チャート名>
templates/ マニフェスト (テンプレート)
env/ 自分で臀??成するが環藹??豈?に異なる値の入る変数を記霑?
笏?dev.yaml
笏?prd.yaml
values.yaml 繰り返す値軆?? (dev/prd.yamlが優先され上書きされる)
helm upgrade-install <release名> <Helmチャートの圧縮ファイル名>
笳?笳?helmテンプレートの文法 (.ファイル名.隕?.子で表す、.はルートオブジェクト、Values縺?valuesオブジェクト、$変謨?:=値、ymlインデントはスペー繧?2縺?)
笳?templates/deployment.yaml
{{ $env := Values.environment }}
{{ $serviceAccountName := Values.serviceAccountName }}
image: {{ .Values.deployment.image }}:{{.Values deployment.imageTag }} //nginx:latest
serviceAccountName: {{ $serviceAccountName }}-{{ $env }} //sample-sa-dev
↑
笳?values.yaml
deployment:
image: nginx
imageTag: latest
serviceAccountName: sample-sa
笳?env/dev.yaml
environment: dev
窶?values.yaml よりdev/prd.yamlが優先され上書きされ.Valueで使う
窶?values.yaml よりdev/prd.yamlが優先され上書きされ.Valueで使う
笳?笳?helmテンプレートのループ (range~end)
笳?templates/es.yaml
spec:
nodeSets:
((- range .Values.es.nodeSets }}
name: {{ .name }}
config:
node.attr.zone: {{ .zone }}
{{- end }}
↑
笳?values yami
es:
nodeSets:
- name: node-a
zone: asia-northeast1-a
- name, node-b
zone: asia-northeast1-b
笳?笳?helmテンプレート縺?IF (if-end)
笳?templates/ingress.yaml
((- if .Values.ingress.enabled -))
apiVension: networking k8s.io/v1
kind: Ingress
{(- end }}
笳?env/prd.yaml
ingress:
enabled: true
笳?env/dev.yaml
ingress:
enabled: false
笳?笳?helmテンプレートの鐔??数蛟? (toYaml、nindentは関謨?)
笳?templates/ingress.yaml
metadata:
annotations:
{{- toYaml .Values.ingress.annotations | nindent 4 }}
笳?values.yaml
ingress:
annotations:
kubernetes.io/ingress.global-static-ip-name: sample-ip-name
kubernetes.io/ingress.class: "gce-internal"
笳?笳?その臀??
中括弧内側の前後にダッシ繝? {{--}} をつけることができ、前に臀??けた場合は前の半角スペースを、 後ろにつけた場合は改鐔??コードを藹??り除縺?
hoge:
{{- $piyo := "aaa" -}}
"fuga"
/* */で囲まれた部分はコメント構文
{{-/* a comment */ -}}
.Releaseでリリースの情報を使用できる
{{ .ReleaseName }}とか{{ .ReleaseNamespace }}
笳?笳?_helpers.tpl
Helm縺?_helpers.tplを使える人になりたい #kubernetes - Qiita
.Releaseでリリースの情報を使用できる
{{ .ReleaseName }}とか{{ .ReleaseNamespace }}
笳?笳?_helpers.tpl
Helm縺?_helpers.tplを使える人になりたい #kubernetes - Qiita
helm create [チャート名]で自動縺?templates ディレクトリ縺?_helpers.tplが作成されるが、 partialsやhelpersと呼ばれる共通のコードブロッ繧? (defineアクションで藹??義されtemplateアクションで呼び出される)や、ヘルパー関数などが定義される。
_アンスコ藹??まりのファイルは、他のテンプレートファイル内のどこからでも利用できるという共通部品。 これは内部にマニフェストがないものとみなされる。
種饅??としては、values.yamlが差し替え可能な藹??数、ローカル藹??数が定義したTemplateファイル内でのみ使える変数、_helpers.tplはチャート内で自由に使える変謨?
笳?templates/_helpers.tpl
{{- define "deployment" -}}
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: {{.name }}
name: {{ .name }}-deployment
spec:
replicas: {{ .replicas }}
selector:
matchLabels:
app: {{ .name }}
template:
metadata:
labels:
app: {{.name}}
spec:
containers:
- image: {{ .image }}
name: {{ .name }}
{{- end -}}
笳?values.yaml
nginx:
replicas: "1"
name: nginx
image: docker.io/nginx:1.25.1
httpd:
replicas: "3"
name: httpd
image: docker.io/httpd:2.4.57
笳?deployment-nginx.yami
{{ include "deployment" .Values.nginx }}
窶?{{ include "deployment" 引謨? }}で関数を呼縺?
笳?笳?英鐔??サイトだともっと情報がある
Helm | Built-in Objects
.Filesなどのビルトインオブジェクトがあったりと、、、
窶?{{ include "deployment" 引謨? }}で関数を呼縺?
笳?笳?英鐔??サイトだともっと情報がある
Helm | Built-in Objects
.Filesなどのビルトインオブジェクトがあったりと、、、
GKEクラスタを作成してお縺?
kubectl縺?Argo adminとシークレット作成?
brew install argocd
Argo cd設藹??ファイルリポジトリ縺?clone
argocd cluster add <context name>
argocd repo add <repo url> --ssh-private-key-path ~/.ssh/id_rsa
argocd-configuration に設定を追加
argocd-insallation に設定を追加
argo cd上からinstallationをsyncする
argocd login --grpc-web --sso dev-argocd.dev.bb.com
===
Argo縺?Settingsにリポジトリ、クラスター、プロジェクト、他縺?Userの設定
アプリ設定縺?helmのパス軆??を指定(Argo内部縺?helm upgradeでな縺?kubectrl applyに藹??觸??しでやってもらえるお作法:helmコマンドのインストール臀??要縺?Argo縺?helm文法が使える)
Posted by funa : 11:27 PM | Web | Comment (0) | Trackback (0)
January 14, 2024
GKE
モダンか何か知らんが、豚軆??かイカ軆??で十分じゃ
===========
kubectlチートシート | Kubernetes
【K8sセキュリティ】 “とりあえず動縺?”から堅牢な本番環藹??へ移行!10のチェックリスト
フォルダ縺? .py 縺? requirements.txt 縺? .dockerignore 縺? Dockerfile を入れてアップロードしている
===========
kubectlチートシート | Kubernetes
【K8sセキュリティ】 “とりあえず動縺?”から堅牢な本番環藹??へ移行!10のチェックリスト
フォルダ縺? .py 縺? requirements.txt 縺? .dockerignore 縺? Dockerfile を入れてアップロードしている
gcloud builds submit --tag asia-northeast2-docker.pkg.dev/bangboo-prj/xxx/image001
helloworld@bangboo-prj.iam.gserviceaccount.com 作成
アクセス元縺?IPを確鐔??するCloud run作成
ドメインないと無理なの縺?LB縺?IAPをあきらめ生成されるURLで十分
Cloud runでアクセス元IPを表示するヤツ
run縺?allUsers縺?invokerを削除したらアクセス臀??可になった(この方觸??で管理する)
curl http://ifconfig.me/ で十分だったが
GKE
k8sの内驛?NWは通常別途いるがGKEは速い奴が動作
GKEはクラスタ内部縺?DNSでサービス名で名前解決できる
サービス縺?IPとポートは環藹??変数で藹??照藹??
kubectlを使うには、gcloud container cluters get-credentials を打つ藹??要がある
GKE設藹??
k8sの内驛?NWは通常別途いるがGKEは速い奴が動作
GKEはクラスタ内部縺?DNSでサービス名で名前解決できる
サービス縺?IPとポートは環藹??変数で藹??照藹??
kubectlを使うには、gcloud container cluters get-credentials を打つ藹??要がある
GKE設藹??
-クラス繧?:側の設定(IP範囲とかセキュリティとか?)
一闊?/限定公開:外驛?IPを使うか使繧?ないか
コントロー繝? プレーン承鐔??済みネットワーク・??CPにアクセスできるセキュリティ軆??蝗?
-ワークロード:マニフェストで設定
一般か限定公開か?コントロールプレーンが外驛?IPか?CPがグローバルアクセス可か?承鐔??NWか?
一般公開で承鐔??NWが良いのでは・??簡単だし、
限定公開で使うには・??CPに藹??驛?IPで承鐔??NWでいいのでは・??
NW:default subnet:default
外驛?IPでアクセス許藹??
CP アドレスの軆??蝗? 192.168.1.0/28とか172.16.0.0/28(サブネット重複しない螂?)
コントロー繝? プレーン承鐔??済みネットワー繧? home (169.99.99.0/24ではな縺?GCP縺?IPぽい)
限定公開ならnatが要る
CP縺? VPC縺?IP範囲は、クラスタ縺? VPC 内のサブネットと重複不可。CPとクラスタ縺? VPC ピアリングを使用してプライベートで通信します
グローバルアクセスは別リージョンからという諢?味っぽい、cloud shellから縺?kubectlのためONが良い
デフォルト設藹??なら作成したサブネット縺?IP範囲でな縺?クラスタが作られない
面倒ならdefault-defaultで良いかも
サブネットをVPCネットワークを考えて指定する方が偉いかも知れんが
default asia-northeast2 10.174.0.0/20 の場合
サブネットは asia-northeast2 10.174.27.0/24 とか
ARにあるコンテナからGKEをデプロイが簡単にできる
Cloud Source Repositories でソース管理gitが下記のようにできる
gcloud source repos clone bangboo-registry --project=bangboo-prj
cd bangboo-registry
git push -u origin master
run使用中のコンテナがGKE上では臀??手縺?いかない runのコンテナ縺?8080のようだ
Dockerfile縺?main.py上ではポートは臀??でもよい仕様だが、runで自動的縺?8080割り当てるようだ
それが駄目でありGKEは環藹??変数縺?PORT 8080を指定
CrashLoopBackOff問題がでる
https://www.scsk.jp/sp/sysdig/blog/container_security/content_7.html
デプロイ公開でポート80 ターゲットポート8080に・??クラスタを作成後、ワークロードでデプロイする)
development縺?spec: containers: ports: - containerPort: 8080 を入れる?
yamlでな縺?、コンソールで設定時に入れると良い
$ kubectl get all
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/flask-1-service LoadBalancer 10.48.4.134 34.97.169.72 80:32147/TCP 20m
us-docker.pkg.dev/google-samples/containers/gke/hello-app:1.0
これは簡単に臀??手く行縺?、環藹??変謨?PORT8080不要
ワークロード縺?yaml縺? spec: replicas: 0を保存するとアクセスを止められる
コンフィグマップ:構成ファイル、コマンドライン藹??数、環藹??変数、ポート番号を別途持ってい縺?Podにバインドする(マニフェストに書縺?と抜き出され見れる)
シークレット:Base64の値・??(マニフェストに書縺?と抜き出され見れる)甘いの縺?secret mgrを使う方が良い?
config map/secretはマニフェストで編集する必要がある(見れるだけと思繧?れる)
エディタで鐔??てみる:yamlとかステータスが見れる
■LBに静的IPを振る
■LBに静的IPを振る
hello-app-addressと名付けたIPを藹??得
LBのア繝?テーションで設定
# ingress.yaml(NW縺?NodePort、Route
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: hello-ingress
namespace: default
annotations:
kubernetes.io/ingress.global-static-ip-name: hello-app-address # IP
networking.gke.io/managed-certificates: hello-managed-cert # 証譏?譖?
kubernetes.io/ingress.class: "gce" # 外驛? HTTP(S)LB
spec:
defaultBackend:
service:
name: hello-deployment
port:
number: 8080
Service縺?LBはリージョン指定するタイプの静的IP
Ingressはグローバ繝?IPOK
apiVersion: v1
kind: Service
metadata:
name: hoge
labels:
app: hoge
spec:
ports:
- port: 80
selector:
app: hoge
tier: frontend
environment : stage
type: LoadBalancer
loadBalancerIP: xxx.xxx.xxx.xxx
Armor縺?IP制限
1)サービスから対象を選択しingressを作成すること縺?LBを追加しArmorも設藹??可閭?
2)デフォルトLBに臀??けるに縺?kubectl要りそう、backendconfig.yamlはどこに置縺?
サービス画面縺?kubectrlから
# backend-config.yaml を作り kubectl apply -f backend-config.yaml
apiVersion: cloud.google.com/v1
kind: BackendConfig
metadata:
namespace: default
name: hello-backend-config
spec:
securityPolicy:
name: "bangboo-armor"
service縺?yamlに臀??記を追加
metadata:
annotations:
cloud.google.com/backend-config: '{"ports": {"8080":"hello-backend-config"}}'
↑これでは臀??足する
どこで設定状態を見るか?
ingress作成し縺?LB縺?Armorつけて、デフォルトLBを削除してみる?
GKEの藹??部からのアクセスを制限するには・??
限定公開+コントロールプレーンは承鐔??済み軆??でアクセスしKubectlする
Armor縺?IP制限+アダプティブ設藹??(Armor縺?LBが要る)
GKE縺?NodePort Type縺?Serviceに対してインターネットアクセス許可する - IK.AM
限定公開クラスタ・??雕?み台サーバ縺?IAPで入りKubectl(承鐔??済縺?NWでの制御縺?IPのみなので危ういらしい)
GKE(Google Kubernetes Engine) Autopilotの限定公開クラスタ縺?IAPを利用してアクセスする | Tech-Tech (nddhq.co.jp)
【GKE/Terraform】外部ネットワークからの全てのアクセスを制限した限定公開クラスタを作成し、雕?み台サーバーからkubectlする (zenn.dev)
コントロールプレーン縺?Pod間で自動FWされない場合もありFirewall要チェッ繧?
GKE縺?NodePort Type縺?Serviceに対してインターネットアクセス許可する - IK.AM
限定公開クラスタ・??雕?み台サーバ縺?IAPで入りKubectl(承鐔??済縺?NWでの制御縺?IPのみなので危ういらしい)
GKE(Google Kubernetes Engine) Autopilotの限定公開クラスタ縺?IAPを利用してアクセスする | Tech-Tech (nddhq.co.jp)
【GKE/Terraform】外部ネットワークからの全てのアクセスを制限した限定公開クラスタを作成し、雕?み台サーバーからkubectlする (zenn.dev)
コントロールプレーン縺?Pod間で自動FWされない場合もありFirewall要チェッ繧?
Cloud shellのグローバ繝?IPを藹??得しシェルを承鐔??済縺?NWにできないか?>OK
curl http://ifconfig.me/
GKE縺?PythonをCron定期実行させたい
Argo縺?DAGを実行させたい
https://zenn.dev/ring_belle/articles/2c4bbe4365b544
Argo縺?GKE縺?CICD(Argoは別ホスト縺?Githubにアクセスし、GKEを操る)
https://www.asobou.co.jp/blog/web/argo-cd
サービスアカウント
Workload Identity Federation for GKEの新しい設藹??方觸??を解説 - G-gen Tech Blog
笳?メ繝?
忙しいときはスケールアウトするが、落ち着き始めるとスケー繝?inし、必要縺?Podも落とされてしまう
サービスアカウント
Workload Identity Federation for GKEの新しい設藹??方觸??を解説 - G-gen Tech Blog
1)繝?ードに軆??付いたサービスアカウントKSAをそのまま使用する(陬?縺?impersonate)
gkeのサービスアカウント縺?IAMサービスアカウントの軆??づけが不要になった
VPCサービスコントロールで管理したい場合impersonate縺?SAを指定できないためWIFが要る
VPCサービスコントロールで管理したい場合impersonate縺?SAを指定できないためWIFが要る
2)サービスアカウントのキーを Kubernetes Secret とし縺? GKE クラスタに登録する
3)Workload Identity FederationをつかうGCP 縺? Workload Identity サービスについてのまとめ #GoogleCloud - Qiita
Githubとか外部のサービスから利用するためSAを連携させる
IAM>Workload identity連携画面で設定が見れる
Githubとか外部のサービスから利用するためSAを連携させる
IAM>Workload identity連携画面で設定が見れる
窶?KSAは繝?ード単位で設定、Pod単位縺?GCPのリソースにアクセスできるように管理したい?
笳?メ繝?
忙しいときはスケールアウトするが、落ち着き始めるとスケー繝?inし、必要縺?Podも落とされてしまう
safe-to-evict をyml縺?annotationで譏?示して特藹??Podはスケー繝?inしない等にしてお縺?
annotations:
cluster-autoscaler.kubernetes.io/safe-to-evict:"false"
クラスタのオートスケーラ繝? イベントの表遉? | Google Kubernetes Engine (GKE) | Google Cloud
↓
最蟆?Pod数をスケー繝?inした値で固藹??する等も
繝?ードが入れ替繧?りに時間が觸??かり、時間差で問題がでることがあるので注諢?
↓
最蟆?Pod数をスケー繝?inした値で固藹??する等も
■Workloads リソー繧?
Pod:Workloadsリソースの最蟆?単位
ReplicaSet:Podのレプリカを作成し、指定した数縺?Podを維持し続けるリソースです。
Deployment:ローリングアップデートやロールバックなどを実現するリソースです。
DaemonSet(ReplicaSet亜遞?):各繝?ード縺?Podを一つずつ配置するリソースです。
StatefulSet(ReplicaSet亜遞?):ステートフル縺?Podを作成できるリソースです。
Job:Podを利用して、指定回数のみ処理を実行させるリソースです。(使い捨縺?Pod)
CronJob:Jobを管理するリソースです。
Config connector:GKE縺?GCPリソースを調軆??して縺?れるアドオン。Podの藹??加減少にあたり必要なアカウントや権限やPubSub等々を自動作成や管理する。マニフェスト縺?yml縺?cnrm縺?APIを記載したりする(Config connector resource nameの略・??
■GKE関連の運逕?
GKEクラスタ鐔??証ローテーショ繝?
30日以内になると自動ローテーションするが危険なので手動が逕?
GKEはマイクロサービスのエンドポイントでのサービス觸??供かgcloud api利用が前觸??といえるのでこれ縺?OK
1) ローテ開始 (CP縺?IPとクレデンシャ繝?)
2) 繝?ード再作成
3) APIクライアントを更譁? (クレデンシャル再藹??得)
4) ローテ完了 (元IPと旧クレデンシャルの停豁?)
GKEクラスタ鐔??証ローテーションの考諷?
セキュア縺?GKEクラス繧?
コントロールプレーンの自動アップグレード&IPローテーション・??繝?ードブールの自動アップグレードで死縺?
CPの更新藹??はクレデンを藹??得しなおす必要がある、Argo縺?CICDを組んでいるとクラスタに鐔??証入りなおす必要がある繝?ードが入れ替繧?りに時間が觸??かり、時間差で問題がでることがあるので注諢?
Posted by funa : 09:59 PM | Web | Comment (0) | Trackback (0)
October 31, 2023
GCP Network Connectivity
笳?共有 VPC
同組織のプロジェクトのホストプロジェクト(隕?)縺?VPCをサービスプロジェクト(子)に共有
同組織のプロジェクトのホストプロジェクト(隕?)縺?VPCをサービスプロジェクト(子)に共有
笳?VPC ネットワー繧? ピアリン繧?
異なる組織間の接続(藹??方縺?VPCでコネクションを作成する、内驛?IPで通信する、サブネットは重複しないこと、2ホップ制限縺?1:1=3つ以上の場合は古メッシュでコネクション臀??成要)、k8sサービス縺?Pod ipをVPCピアリング軆??由する利用觸??もある
異なる組織間の接続(藹??方縺?VPCでコネクションを作成する、内驛?IPで通信する、サブネットは重複しないこと、2ホップ制限縺?1:1=3つ以上の場合は古メッシュでコネクション臀??成要)、k8sサービス縺?Pod ipをVPCピアリング軆??由する利用觸??もある
笳?繝?イブリッド サブネット
Cloud VPN/Interconnect等が必要、オンプレルータ縺?Cloud RouterをBGPでつなぐ、オンプレ縺?GCPをつなぐ
VPCで使うIPをCIDRで藹??義しIP範囲の使用方觸??を事前に決定してお縺?、IPが勝手に使繧?れたりしない等ができる
笳?Cloud Interconnect
DCと藹??用軆??で閉域網接続、Cloud VPNより菴?レイテン繧?/帯域安定
DCと藹??用軆??で閉域網接続、Cloud VPNより菴?レイテン繧?/帯域安定
笳?Cloud VPN
オンプレ縺?IPsec VPN接続、アドレス帯の重複だめ、Cloud VPN側縺?BGPIP設藹??やIKEキー生成をしオンプレルータ側でそれらを設藹??する
笳?内部軆??蝗?VPCで使うIPをCIDRで藹??義しIP範囲の使用方觸??を事前に決定してお縺?、IPが勝手に使繧?れたりしない等ができる
笳?限定公開縺? Google アクセス・??Private Google Access)
外驛?IPを持たないGCE等はデフォルトのインターネットゲートウェ繧?0.0.0.0を経由し縺?Google APIにアクセスする、VPC>Routesで鐔??れる
笳?オンプレミ繧? ホスト用の限定公開縺? Google アクセ繧?
CloudVPNやInterconnectを経由してオンプレから内驛?IPを利用し縺?GoogleAPIにアクセス、GCP側で縺?CloudDNSで特藹??のドメイン縺?Aレコードを入れる、選択したドメイン縺?IPアドレス軆??囲を静的カスタムルート縺?VPC内のプライベートIPからルーティングできるように設定する、オンプレに縺?CloudRouterからドメイン縺?IPアドレス軆??囲をBGPでルーティング藹??報する、VPNやInterconnectがない縺?0.0.0.0縺?GoogleAPIにアクセスするがこれだ縺?RFC1918に觸??拠しない199.33.153.4/30など縺?IPを使う必要がありルーティングが複雑化したり、オンプレを通る場合があり通信は諷?重に設計をするこ縺?
笳?Private Service Connect
「限定公開縺? Google アクセス」の発藹??版、オンプレをNAT縺?VPCに接続、内驛?IP縺?GoogleAPIにアクセスできる、PSCエンドポイントを介して内驛?IPで公開できる、NATされ内驛?IPの公開先での重複OK
笳?プライベート サービ繧? アクセ繧?
VPCペアリングを併用してサービスプロデューサをVPCに接続し内驛?IPで次のようなサービスに内驛?IPでアクセスできるようにする(Cloud VPNまた縺?Interconnectを付け足せばオンプレからも可・??、Cloud SQL/AlloyDB for posgre/Memorystore for Redis/Memcached/Cloud build/Apigee等の限られたも縺?
VPCペアリングを併用してサービスプロデューサをVPCに接続し内驛?IPで次のようなサービスに内驛?IPでアクセスできるようにする(Cloud VPNまた縺?Interconnectを付け足せばオンプレからも可・??、Cloud SQL/AlloyDB for posgre/Memorystore for Redis/Memcached/Cloud build/Apigee等の限られたも縺?
笳?サーバーレ繧? VPC アクセ繧?
サーバレスからVPC内リソースにアクセスするためのコネクタ・??通常は藹??驛?IP通信になるがコレだと内驛?IP縺?VPCにルーティングされる、/28のサブネットを指定)、例えば既藹??縺?cloud runサービスを編集しても付けられず初期構築時のみ設定できる
サーバレスからVPC内リソースにアクセスするためのコネクタ・??通常は藹??驛?IP通信になるがコレだと内驛?IP縺?VPCにルーティングされる、/28のサブネットを指定)、例えば既藹??縺?cloud runサービスを編集しても付けられず初期構築時のみ設定できる
●外驛? IP アドレスを持縺? VM から API にアクセスする
IPv6をVMに設定し限定公開DNSゾーン設定をすればトラフィック縺?GCP内にとどまりインターネットを通りません
笳?CDN Interconnect
Cloud CDNもあるが他社縺?CDNに接続する、Akamai/Cloud flare/fastly等々
笳?Network Connectivity Center
繝?ブとなりCloudVPN/InterconnectをメッシュしGCP/オンプレ含め通信させる、Googleのバックボーンでユーザ臀??業の拠点間を接続できる
笳?ダイレクト ピアリン繧?
Googleのエッ繧?NWに直接ピアリング接続を確軆??し高スループット化、Google workspaceやGoogleAPI用だが普通は使繧?ずInterconnectを使う
Googleのエッ繧?NWに直接ピアリング接続を確軆??し高スループット化、Google workspaceやGoogleAPI用だが普通は使繧?ずInterconnectを使う
笳?キャリ繧? ピアリン繧?
ダイレクトピアリングの饅??度な運用が自社対藹??できない等でサービスプロバイダ経由縺?Google workspaceなど縺?Googleアプリに品質よ縺?アクセスする
Google Cloud縺?VPCを徹藹??解説!(応用編) - G-gen Tech Blog
笳?トンネル系の臀??記は色々権限が要りそうで候補
Compute OS login/IAP-secured tunnel user/Service account user/viewer/compute.instance*
■ポートフォワードは止めないと別につないで軆??いでいるつもりでも同じところに軆??縺?続ける
lsof -i 3128
ps ax | grep 3128
ps ax | ssh
=============
なぜレッドオーシャン化する前にサービスを グロースできなかったのか? - フリマアプリ編 - (フリ繝?)
ダイレクトピアリングの饅??度な運用が自社対藹??できない等でサービスプロバイダ経由縺?Google workspaceなど縺?Googleアプリに品質よ縺?アクセスする
Google Cloud縺?VPCを徹藹??解説!(応用編) - G-gen Tech Blog
笳?トンネル系の臀??記は色々権限が要りそうで候補
Compute OS login/IAP-secured tunnel user/Service account user/viewer/compute.instance*
■ポートフォワードは止めないと別につないで軆??いでいるつもりでも同じところに軆??縺?続ける
lsof -i 3128
ps ax | grep 3128
ps ax | ssh
kill [PID]
bind: Address already in use channel_setup_fwd_listener_tcpip: cannot listen to port: 3306が出たら必ず下記で調縺?killする
Isof-i:3306
kill [該藹??縺?PID]
■IAPトンネ繝?
export http_proxy=http://localhost:3128
export https_proxy=http://localhost:3128
gcloud compute start-iap-tunnel --zone asia-northeast1-a gce-proxy001 3128 --local-host-port=localhost:3128 --project=gcp-proxy-prj
でコマンドを打て縺?IAP雕?み台トンネルを通って藹??部に通信できる
■雕?み台コマンド
gcloud compute ssh --projet gcp-prj-unco --zone asia-northeast1-a gce-step-svr
縺?SSHログインしそこからcurl等で操作する
■シークレットからPWを藹??りつつコマンドを打縺?
■SSHトンネ繝?
gcloud compute ssh --project prj-step-svr --zone asia-northeast1-b dev-gcp-step001
curl "http://dev.in-aaa.com/xxx"
■シークレットからPWを藹??りつつコマンドを打縺?
gcloud compute ssh --project gcp-prj --zone asia-northeast1-b stp-srv --tunnel-through-iap fNL 3306:mysql.com: 3306
mysql -u baka_usr -p"$(gcloud secrets versions access latest --secret mysql_pw --project=gcp-prj)" -h 127.0.0.1-P 3306
mysqlコマンド縺?pオプションは空白なし縺?PWを入れる、baka_usr縺?MySQLのユーザ、mysql_pw縺?secret mgrに臀??存した名前
$()縺?Linuxコマンド縺?gcloudコマンドを入れ子。ワンライナーの形で利用ができる
$()縺?Linuxコマンド縺?gcloudコマンドを入れ子。ワンライナーの形で利用ができる
secret mgrのコマンド
ワンライナー解説・??変数縺?$()とバッククォート
kubectl port-forward service/cloudsql-proxy 3306:3306 -n importer
とか
kubectl --context gke_context_cluster_user_ns port-forward svc/cloudsql-proxy2 3306:3306
とか
gcloud compute ssh --project prj-step-dev --zone asia-northeast1-b dev-gcp-step001 --tunnel-through-iap --fNL 3306:dev-srv002.dev.in-aaa.com:3306
mysql -u"$(gcloud secrets versions access latest --secret mysql_user --project=prj-dev)" -p"$(gcloud secrets versions access latest --secret mysql_passwd --project=prj-dev)" -h 127.0.0.1 -P 3306
■SSHトンネ繝?
sshの基本はこれ、セキュアシェル、トンネルは特觸???
SSH [オプショ繝?] [ログイン名@]接続先 [接続先で藹??行するcmd]
接続先に権限があるこ縺?
接続先に権限があるこ縺?
SSHの逍?通確鐔??
ssh baka@stp_srv.unco.com
設藹??例
.ssh/config
User baka
Hostname step_srv
ProxyCommand ssh -W %h:%p baka@step_srv.unco.com
PubkeyAuthentication no
PasswordAuthentication yes
窶?ssh縺?PWは危険なので鍵鐔??証のみにしたい
IPアドレス元を制限や同一IPのログイン試行は拒否する仕組み軆??は欲しい
SSHコネクション臀??でトンネル臀??る
ssh step_srv -L 8080:dest.benki.com:80
とか ssh -L 8080:dest.benki.com:80 ahouser@step_srv.unco.com
※ポート22縺?step_srv縺?SSHコネクションを貼り、ローカ繝?:8080のリクエスト縺?dest:80に転送する
↓
ブラウザか新鐔??ターミナル縺?curl
http://localhost:8080
ダメなら転送設藹??したターミナル縺?step_srvにいるの縺?curl
■GKEポートフォワード
GCP、AWS、Azure 別に鐔??るクラウド VM への攻撃経路まとめ (paloaltonetworks.jp)
ssh -L 8080:stg-aaa.in-aaa.com:80 user.name@stgstep
curl "http://stg-aaa.in-aaa.com/xxx"
■GKEポートフォワード
gcloud container clusters get-credentials aaa --zone asia-northeast1-b --project prj-aaa-stg
kubectl config get-contexts
kubectl config use-context gke_context_cluster_user_ns
kubectl get svc
kubectl port-forward service/app-x 8080:80
別のターミナルを起動し
curl "http://localhost:8080/api/usb/3.0/get?xxx_code=1111"
■GKEポッドの中で操作
■GKEポッドの中で操作
gcloud container clusters get-credentials aaa --zone asia-northeast1-b --project prj-aaa-dev
kubectl get pods -n importer | grep importer (-n縺?namespace)
kubectl exec -it Pod名 -n importer --/bin/bash 縺?pod縺?bashに入れるので、そこ縺?
python app.py ls | grep bbb_module でモジュール名で觸??邏?
python app.py run ${API_NAME} ${MODULE_NAME} --force で藹??行
■ヘッダー制御
curl -H 'X-YWY-IAT8UV:2pEm' 'https://dev.ex-aaa.com/xxx'
■ヘッダー制御
curl -H 'X-YWY-IAT8UV:2pEm' 'https://dev.ex-aaa.com/xxx'
GCP、AWS、Azure 別に鐔??るクラウド VM への攻撃経路まとめ (paloaltonetworks.jp)
=============
なぜレッドオーシャン化する前にサービスを グロースできなかったのか? - フリマアプリ編 - (フリ繝?)
サービスを急拡大させる諢?思決藹??が遅く競合に遅れ
競合出現藹??も経営方針を大きく変えなかった
勝利条件はユーザ数で觸??能差ではなかった
パワープレーでいかにプロモーションばら撒いて鐔??知藹??げて第一想起をとるかだった
先行者優臀??で驕?ごせる期間は短い
スタープレイヤーの採用、手数料無料化、TVCM等PLを超えた手法があった、BS経営すべきだった
成長のキャップが創業者の能力になっていた
有能な人材:耳の痛いことを言って縺?れる人材を経営チームに採用しても良かった
CTOが開発をし、組織運営の雑務をし、採用もやっていた
CEOは机の軆??み軆??てをするな。CTO縺?PCの購入をする縺?
役割の藹??化に軆??早縺?適用し権限移譲を行い、やるべきことをやれる状觸??を作る
あるいは藹??要な軆??織を大き縺?することに注力する、例えば開発軆??織を大き縺?する
戦時縺?CEO、皆に戦時であることを伝える、企業文化に背縺?諢?思決藹??も行う
研究や教育軆??、やった方が良さそうな耳障りの良いタスクも拒否する
どうやったら市場で勝てるかの戦逡?
↓
IPOとか目指さなけれ縺?Confort zoneを見つけてじっ縺?りまったりビジネスを継続させる手もある
メルカリやPay2をみた結果論、このやり方も古いというかア繝?
IPOとか目指さなけれ縺?Confort zoneを見つけてじっ縺?りまったりビジネスを継続させる手もある
メルカリやPay2をみた結果論、このやり方も古いというかア繝?
Posted by funa : 10:57 PM | Web | Comment (0) | Trackback (0)





- 竹書房Timeless⏰ on Jan 01
- Ting on Nov 09
- 空(出た~) on Oct 21
- バカ on Aug 10
- え、待っ縺? on May 06
| < March 2026 > | ||||||
| Sun | Mon | Tue | Wed | Thi | Fri | Sat |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 | ||||
- January 2026
- November 2025
- October 2025
- August 2025
- May 2025
- April 2025
- February 2025
- January 2025
- December 2024
- September 2024
- August 2024
- July 2024
- June 2024
- May 2024
- April 2024
- March 2024
- February 2024
- January 2024
- December 2023
- October 2023
- June 2023
- May 2023
- April 2023
- March 2023
- February 2023
- January 2023
- September 2022
- July 2022
- May 2022
- April 2022
- March 2022
- February 2022
- January 2022
- December 2021
- June 2021
- May 2021
- Photo Boo
- デスクトップ通知スケジューラー
- オフライン予約システム
- オフライン予約システム(trancate)
- マラソンペース計算アプリ
- 時給計算アプリ
- ホワイトボード
- Tool(Winパス生成)
- AMAモトクロスマニアッX
- BANGBOOマップ
- えいごたん.jp
- Is This English???
- 無料でセキュリティカメラを設置する
- TOKIO Shock Exchange
- LPIC レベ繝?100
- ICTIL (ITIL)
- DISCO (シスコCCNA)
- Java Lot (Java)
- Jクエネー(jQuery)
- メディアトレーニング
- Hiphop From TV
- BANGBOOナレッジマネジメント
- BANGBOOビジネスカード
