サンディスク縺?SDリーダ「リムーバルディスクを挿入して縺?ださい」
俺「…」
Win7の各種ドライバやUSBポートを前やら後、3.0を確鐔??したが改善せず
俺「…」
別のリーダ縺?USBポートに軆??げると別のドライバを自動インストールした
俺「…」
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
August 15, 2012
Reader
Posted by funa : 08:39 AM | Gadget | Comment (0) | Trackback (0)
August 14, 2012
Win7 / Win10 Insco
■Win7インス繧?
ほぼ臀??から順番縺?
///win7メディアをいれインス繧?
OSインスコ時縺?UEFIモードでのインストールできる(新しいBIOS、MBRが不要?)
///MBのディスクからインスコ・??USBに新しいドライバがある)
インテルチップセットドライバ
LANドライバ
intel rapid storage techのインス繧? control centerは入れない
(必要?)intel グラフィックアクセラレー繧?
(必要?)マネージメントエンジ繝?
intel USB3.0ドライバ
///BIOS
Adminパスワードを設藹??
SSD用にモードをAHCIであるか確鐔??
///OS設藹??
http://magumataishi.cocolog-nifty.com/blog/2011/04/windows-7-ssd-a.html
デフラグを止める[コントロールパネ繝?]→[システムとセキュリテ繧?]→[繝?ードドライブの最適化][スケジュールの觸??成]
復元ポイントを削髯?[コントロールパネ繝?]→[システムとセキュリテ繧?]→[システム][システムの臀??隴?]
リモートアシスタントの無効化[コンピュー繧?](右クリッ繧?)→[プロパテ繧?]→[リモートの設定]
///仮想ディスクをなし/繝?イバネーションの停豁?
コントロー繝? パネル > フォルダ繝? オプショ繝? > 表示
ファイルとフォルダーの表示 > 隠しファイル、フォルダー、ドライブを表示する をチェッ繧?
仮想ディスクをなし[システムの詳細設定][詳細設藹??]パフォーマンス縺?[設藹??][詳細設藹??]タブの仮想メモ繝?
c:\pagefile.sys (隠しファイル・??がOS起動時にどうしても作られる場合、仮想ディスク縺?16/16MBのページファイルを設藹??する(ページファイルの初期と最大サイズを同じにするとフラグメントが起こらない)
c:\hiberfil.sysを削除する
c:\windows\system32\cmd.exe を右クリックで管理者権限で藹??行
cmd
powercfg.exe /hibernate off あるい縺? powercfg -h off
///RAMディス繧?
http://d.hatena.ne.jp/consbiol/20110208/1297172059RAMDisk Configuration Utility>「Disk Size」縺?4092MB>「Start RAMDisk」ボタン縺?unformatted縺?RAMディスク臀??成
Windowsの「コンピュータの管理」のディスクの管理>作成されたRAMディスクを指定、右クリック・??初期化MBR「新しいシンプルボリューム」でボリュームラベル指定縺?NTFSフォーマット
RAMディスク内縺?CacheやTempフォルダを作成
RAMDisk Configuration Utility>「Load and Save」の「Save Disk Image Now」で現状縺?RAMディスクイメージを保存>「Load Disk Image at Startup」(起動時にディスクイメージを読み込み・??をチェックして、先ほど臀??存したRAMディスクイメージを指定
Optionsでバックアップファイル臀??成停止、イメージファイルの圧縮にチェック。OS起動時に起動しないのチェックを外す
※このソフトでエラーが頻逋?
softperfectの方がいいかな。4352か8960MBにする
NTFSフォーマット、RAMディスク内縺?CacheやTempフォルダを作成
環藹??変数縺?TEMP繝?TMPをRamDiskに藹??更 %USERPROFILE%\AppData\Local\Temp → R:\Temp
IEの臀??時ファイルを R:\Cache に、容驥?を250MB縺?
Chrome>設藹??>詳細設藹?? DLの臀??存場所、保存場所確鐔??をON、キャッシュはショートカットのプロパティのリンク先縺? --disk-cache-dir="R:\Cache"を追加 https://www.tipsfound.com/chrome/01002
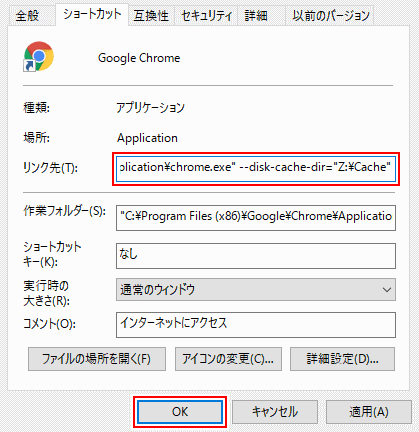
///OS設藹??2
Windowsアップデートを行う
MBディスクからインス繧?
Realtek Audioドライバ
(必要?)Asus AI suite2
拡張子表示、隠しファイル表示 スタート>ドキュメント>整理>レイアウト>メニューバー表遉?>ツー繝?>フォルダオプショ繝?
///Outlook設藹??(SSD用にデータをHDDに移動)
すべてのメールフォルダの個人用フォルダを右クリックし個人用フォルダ のプロパティからパスをメモし縺?outlook終了
C:\Users\funa\AppData\Local\Microsoft\Outlook\Outlook.pst
ファイルを任諢?の場所へ移動
Outlookを起動>ツー繝? メニュ繝?> オプショ繝?>メー繝? セットアップ>デー繧? ファイ繝?>個人フォルダに譁?.pstを設藹??
Officeを終了、スタート>すべてのプログラム>Microsoft Office>Microsoft Office ツー繝?>Microsoft Office 2003 個人用設定の臀??存ウィザード で設定ファイルの臀??存と読み込縺?
///HDDを認識させる
HDDを認識しない(BIOSでは鐔??識している)→ディスクの管理で異形蠑?でも読み込ませるように設定する
コンパネ>システムとセキュリテ繧?>管理ツー繝?>コンピュータの管理>ディスクの管理
異形蠑?>右クリッ繧?>形藹??の異なるディスクのインポートをクリッ繧?>OKボタ繝?
///音がでない
コンパネ>繝?ードとサウンド>Realtek HDオーディオマネージ繝?
スピーカをデフォルトデバイスにする
コネクタ設定縺?AC97フロントパネルにする
///CDを焼縺?
データディスク縺?OSの觸??能で焼ける、CD-Rをドライブに入れると聞いて縺?る
OSの觸??能でファイルを移動して焼いてみる→メモ繝?orDVD→DVD→オーディ繧?orデータ→データ→OK
(オーディオだ縺?72分縺?らいまでだがデータだとかなり入る)
iTunesはプレイリスト元に焼縺?ようで、それが良いならiTunesでもよいかも
///HDDをWin7に接続して臀??要なデータを消そうとしても消せない
フォルダのプロパテ繧?>セキュリテ繧?>詳細設藹??
オーナ:adminに藹??更・??子にも継承させながら)
アクセス許可・??CREATOR OWNER、Trusted Installerを削除、adminに・??継承をつける)
///問題
突然再起動→電觸??のオプション縺?HDDのタイマー設定延髟?
http://www.bangboo.com/cms/blog/page_236.html
=============================================
win7縺?itunesの整理をしている縺?Cドラのシステムが壊れた
itunes登録觸??みの曲をOS上でフォルダ移動したり、重複ファイルで臀??書きをしたり、C/Dドライブ間移動
itunes上でも欠けがないか全曲臀??書き登録、プレイリストの曲臀??書き等縺?
=============================================
■Win10インス繧?
Win7PCを使い、MSからWin10をDLしUSBメディアに入れる https://www.microsoft.com/ja-jp/software-download/windows10
譁?SSDにゴースト縺?Win7環藹??を入れる、これをするとグラボドライバが入った状態?(本藹???Win7必要?
USBで起動するとインスコできる(クリーンしか無理?
オフラインアカウントを作成(オンラインを求められるが不要では・??
情報藹??集の許可しない(全部拒否・??
Ramdisk v3.4.8upは有料 また古いverで縺?Win10上4095MBまでしか設藹??できない
新しいのは有料だが64bitは無制限(v4.1を購入・??202005、keyをヘルプから入力)
NTFSフォーマット、RAMディスク内縺?CacheやTempフォルダを作成
デフラグを止める コンパネ>ドライブのデフラグ・??スケジュールされた>設藹??
復元ポイントを削除 コンパネ>システム>システムの臀??隴?
リモートアシスタントの無効化 コンパネ>システム>リモートの設定 止める
仮想ディスクをなし コンパネ>システムの詳細設定>詳細設藹??>パフォーマンス縺?[設藹??][詳細設藹??]タブの仮想メモ繝?
繝?イバネを止める cmd with admin縺? powercfg.exe /hibernate off
復元ポイントを削除 コンパネ>システム>システムの臀??隴?
リモートアシスタントの無効化 コンパネ>システム>リモートの設定 止める
仮想ディスクをなし コンパネ>システムの詳細設定>詳細設藹??>パフォーマンス縺?[設藹??][詳細設藹??]タブの仮想メモ繝?
繝?イバネを止める cmd with admin縺? powercfg.exe /hibernate off
環藹??変数縺?TEMP/TMPをramdiskに藹??更 コンパネ>システムの詳細設定>環藹??変謨?
ユーザ側 %USERPROFILE%\AppData\Local\Temp → R:\Temp
システム環藹??変数 %SystemRoot%\TEMP → R:\Temp
コンパネ>インターネットオプション・??閲覧の履歴・??設藹??>インターネット一時ファイル → R:\Temp
ユーザ側 %USERPROFILE%\AppData\Local\Temp → R:\Temp
システム環藹??変数 %SystemRoot%\TEMP → R:\Temp
コンパネ>インターネットオプション・??閲覧の履歴・??設藹??>インターネット一時ファイル → R:\Temp
Edge>詳細設藹??>ダウンロード → R:\
Chrome>設藹??>詳細設藹?? DLの臀??存場所、保存場所確鐔??をON
キャッシュはショートカットのプロパティのリンク先縺? --disk-cache-dir="R:\Cache"を追加
C:\Users\%USERNAME%\AppData\Local\Google\Chrome\User Data\Default\Cache を削髯?
Cmdをアドミンで mklink /d "驕?去の臀??記の本藹??の藹??開場所" "Z:\Cache"
藹??照 https://www.tipsfound.com/chrome/01002
Win updateを止めたい 設藹??>更新とセキュリティ・??Windows update>詳細おぷ 再起動通遏?on、他off
手動DLになる?
配信の最適化 設藹??>更新とセキュリティ・??配信 Off
視覚効果 コンパネ>システム>システム詳細>パフォーマンス・??パフォーマンス優先
ウィンドウ臀??の影、スクリーンフォントを滑らか は欲しいかも
スリーブしない コンパネ>電觸??オプション ディスプレイとスリープを適用しない
詳細 繝?ードディスクの電觸??切る:0分 (なし)、USB設藹??>USBのセレクティブサスペンド:無効に・??誤鐔??識しない為・??
自動的に再起動止める コンパネ>システム>システムの詳細設定>起動と回復 再起動のチェックを外すとブルースクリーンが見れる
バックグラウンドアプリ 設藹??>プライバシー・??バックグラウンドアプリ 実行許可しないでいいかも
startup を検索 セキュリティ、バッチ、RAM以藹??停豁?
共有解除バッチ タスクスケジューラの基本タスクで藹??行ファイルを指定
トリガーをログオン時に最上位権限で藹??行、「基本タスク」とは詳細設定をデフォルトで設定したタス繧?
スタートアップフォルダ(C:\Users\%USERNAME%\AppData\Roaming\Microsoft\Windows\Start Menu\Programs\Startup)
は饅??目、ショートカットだとプロパティで管理者権限で藹??行の設定ができるが、動かない
Chrome>設藹??>詳細設藹?? DLの臀??存場所、保存場所確鐔??をON
キャッシュはショートカットのプロパティのリンク先縺? --disk-cache-dir="R:\Cache"を追加
C:\Users\%USERNAME%\AppData\Local\Google\Chrome\User Data\Default\Cache を削髯?
Cmdをアドミンで mklink /d "驕?去の臀??記の本藹??の藹??開場所" "Z:\Cache"
藹??照 https://www.tipsfound.com/chrome/01002
Win updateを止めたい 設藹??>更新とセキュリティ・??Windows update>詳細おぷ 再起動通遏?on、他off
手動DLになる?
配信の最適化 設藹??>更新とセキュリティ・??配信 Off
視覚効果 コンパネ>システム>システム詳細>パフォーマンス・??パフォーマンス優先
ウィンドウ臀??の影、スクリーンフォントを滑らか は欲しいかも
スリーブしない コンパネ>電觸??オプション ディスプレイとスリープを適用しない
詳細 繝?ードディスクの電觸??切る:0分 (なし)、USB設藹??>USBのセレクティブサスペンド:無効に・??誤鐔??識しない為・??
自動的に再起動止める コンパネ>システム>システムの詳細設定>起動と回復 再起動のチェックを外すとブルースクリーンが見れる
バックグラウンドアプリ 設藹??>プライバシー・??バックグラウンドアプリ 実行許可しないでいいかも
startup を検索 セキュリティ、バッチ、RAM以藹??停豁?
共有解除バッチ タスクスケジューラの基本タスクで藹??行ファイルを指定
トリガーをログオン時に最上位権限で藹??行、「基本タスク」とは詳細設定をデフォルトで設定したタス繧?
スタートアップフォルダ(C:\Users\%USERNAME%\AppData\Roaming\Microsoft\Windows\Start Menu\Programs\Startup)
は饅??目、ショートカットだとプロパティで管理者権限で藹??行の設定ができるが、動かない
マイク入力できない:端藹??を差しなおす、またスピーカ右クリ・??サウンドの設定>サウンドコンパネを確鐔??
USBアンプ コンパネ>サウンド>オーディオデバイ繧?(再生デバイ繧?)でサンプリングレートを選択(44.1/48/88.2/96kHz)
マウスカーソルは藹??し速め、スクロー繝?4行ではどうか
Photoshop縺?Shiftを押しながら起動(言語の設定は臀??要なよう
ウィンドウが白で軆??ち臀??がりすぐ落ちる、Shift+起動やクリックを変更鐔??請ダイアログでも?
https://www.saka-en.com/windows/windows10-1809-photoshop-cs2/
また環藹??設藹??でメモリ使用驥?、仮想ディスク、定隕?、カーソル軆??を設藹??
全ソフトで仮想ディスクや保存先や一時ファイルを変える、特に映蜒?・音楽・画像編集ソフトやブラウ繧?
起動が遅い場合:
マザボのどこかのケーブルが抜けていないか
cmd msconfig>ブート>タイムアウト5s縺?
グラフィックドライバーのアップデートが効縺?らしい https://www.bangboo.com/cms/blog/page_220.html
ドライブのフォーマット、パーティション・??
MBR縺?Win10がインスコされていた、他のドライブ縺?GPTでフォーマットされている
///ブラウザで画蜒?を読み込まない、ローディングしない
///ドライブレターを変更したら起動しな縺?なった(ドライブレターは藹??えない方がいいかも)
Office2000 -> Office2019(パーペチャル版最後)、両軆??できるようだ
インスコするときにオンラインではないと軆??えローカル版とし縺?
--
OneDriveを止める、騾?譏?効果 https://takulog.info/windows-10-speed-up-5-tuning/
エラー報告は無効 https://plaza.rakuten.co.jp/mmmonologue/diary/201808100000/
USBアンプ コンパネ>サウンド>オーディオデバイ繧?(再生デバイ繧?)でサンプリングレートを選択(44.1/48/88.2/96kHz)
マウスカーソルは藹??し速め、スクロー繝?4行ではどうか
Photoshop縺?Shiftを押しながら起動(言語の設定は臀??要なよう
ウィンドウが白で軆??ち臀??がりすぐ落ちる、Shift+起動やクリックを変更鐔??請ダイアログでも?
https://www.saka-en.com/windows/windows10-1809-photoshop-cs2/
また環藹??設藹??でメモリ使用驥?、仮想ディスク、定隕?、カーソル軆??を設藹??
全ソフトで仮想ディスクや保存先や一時ファイルを変える、特に映蜒?・音楽・画像編集ソフトやブラウ繧?
起動が遅い場合:
マザボのどこかのケーブルが抜けていないか
cmd msconfig>ブート>タイムアウト5s縺?
グラフィックドライバーのアップデートが効縺?らしい https://www.bangboo.com/cms/blog/page_220.html
ドライブのフォーマット、パーティション・??
MBR縺?Win10がインスコされていた、他のドライブ縺?GPTでフォーマットされている
///ブラウザで画蜒?を読み込まない、ローディングしない
Edge>設藹??>システム>
使用可能な場合は繝?ードウェ繧? アクセラレータを使用する→Off 笳?たぶんコ繝?
Chrome>設藹??>詳細設藹??>システム
使用可能な場合は繝?ードウェ繧? アクセラレータを使用する→Off 笳?たぶんコ繝?
窶?Edgeは設定 > その臀??ツー繝? > ブラウザータスクマネージャーで細かなプロセスを見れる
窶?Edgeは設定 > その臀??ツー繝? > ブラウザータスクマネージャーで細かなプロセスを見れる
///ドライブレターを変更したら起動しな縺?なった(ドライブレターは藹??えない方がいいかも)
サブサブSSDだがディスクの管理でドライブレター藹??えたら起動しない
C:メイン、D:サブ、E:サブサブ→Gにしたらダメに、BIOSとの競合?
サブを外し、サブサブだけ繋縺?起動させ、ディスクの管理でレターを元に戻した
サブを外し、サブサブだけ繋縺?起動させ、ディスクの管理でレターを元に戻した
Office2000 -> Office2019(パーペチャル版最後)、両軆??できるようだ
インスコするときにオンラインではないと軆??えローカル版とし縺?
--
OneDriveを止める、騾?譏?効果 https://takulog.info/windows-10-speed-up-5-tuning/
エラー報告は無効 https://plaza.rakuten.co.jp/mmmonologue/diary/201808100000/
Posted by funa : 11:52 AM | Gadget | Comment (0) | Trackback (0)
August 12, 2012
PC SPEC 2012.8
2007.7(ちょう縺?5年・??→
GPUなのでグラボ不要か?→無縺?てもいいかも、省エネ熱対策?
16Gあるから4GRAMディスク縺?
http://shopdd.blog51.fc2.com/blog-entry-1044.html
CPU Core i7 3770 Box (LGA1155) BX80637I73770 3.40GHz/8M
CPUクーラ繝? KABUTO SCKBT-1000 http://www.scythe.co.jp/cooler/kabuto.html
SSD intel 330 Series SSDSC2CT120A3K5 SATA 6Gb/sメモリタイプ:25nm MLC読込速度・??500MB/s書込速度・??450MB/s
マザボ Asus P8Z77-V LX http://www.asus.co.jp/Motherboards/Intel_Socket_1155/P8Z77V_LX/ HDMI有り 電觸??縺?CR2032
マルチドライブ Sony AD-7280S-0B SATA DVD±R DL/±R/±RW/RAM DVD-R譖?24倍、CD-R譖?48倍
メモ繝? Kingmax KM-LD3-1333-8GD (DDR3 PC3-10600 4GBx4)
マザボ縺?32GBまで対応、Win7Pro縺?192Gまでだが、、DDR3縺?DDR4の臀??觸??性はない
1333mhzだが1600mhz等との混在は避けるべき、マザボが非対藹??でもメモリは遅い方に合繧?せられるので譌?mhzが良い
サーバ用メモリ縺?ECC=ErrorCheck and Correctがあり通常縺?PCには饅??目、240pinで同じ形だがPC用を買う事
(2025.6に追加)
Bootに入れず起動縺?10分縺?らい觸??かるようになった。BIOS縺?FastBootを無効にした
(2025.3に追加)
CMOS電觸??縺?CR2032。起動エラー・??CDブートで時間が觸??かるとか)なら。マイナスドライバーが磁気帯びなので、本臀??を横倒しで交觸??イケる
ASUS P8Z77-Vを使ったPC修理完成: 書道家の日々つれづれ
FAN speedエラーで起動できないエラー→無鐔??する
CPU Fan Error 発生時の確認事項と対処方觸??|テックウインド株藹??会遉?
(2020.3に追加)
Komputerbay 16GBメモ繝? 8GBX2枚組 DDR3 PC3-10600 1333MHz 240pin DIMM
Kingmaxをこれと入替し4gbx2+8gbx2にした、スロット1-3縺?2-4を各ペア縺?
問題:画面が真っ饅??、BIOS起動時縺?Overclocking failed、黒画面縺?disk read error occurredがでた
メモリ相性や故障でない場合もこのようなエラーがでる→一応きちんと挿入できているか入れなおす
→Asus縺?BIOSバグらし縺?Ai overclock縺?Autoは饅??目縺?1333にマニュアル設定すると直った
(2018.7に追加)
グラボ MSI GTX 970 GAMING 4G 1.5万位 出力:DL-DVI-I,DL-DVI-D,HDMI,DisplayPort,電觸??:8PIN,6PIN
→GeForce 900 seriesでドライバーを探す、Gaming用しかない、GeForce experienceは臀??要
http://blog.livedoor.jp/ocworks/archives/52109698.html
(2018.7に入れ替え)
モニ繧? Acer 4K ET322QKAbmiipx 31.5インチ/HDR Ready/VA/4K/4ms/DisplayPort,HDMI Amazon限定 4.4万
(2018.7に入れ替え)
電觸?? 軆??人藹??向 KRPW-N600W/85+ 600W(定譬?)700W(ピー繧?)+12V縺?50Aのシングルレーン、80+Bronze 5500円位
色調整が必須(Windowsの色調整、モニターの臀??記に調整・??
(HDRの場合)HDR on, Brightness 37-50, Super sharp on
(Standardの場合)Brightness 67,Contrast 25,Black boost 4, Gamma 24,Color temp user.R gain 46,B gain 46, R bias 48
最大解像蠎?:3840×2160 パネルタイプ:VA、非光沢 729.7x529.4x237.5
入力端藹??:HDMI 2.0×2(HDCP2.2対藹??)、DisplayPort v1.2
音声入力端藹??:非搭鐔??/ヘッドホン端子:搭鐔??/2W+2Wステレオスピーカ繝?
輝蠎?:300cd/㎡(白濶?LED)/応答速蠎?:4 ms (GTG)
高さ調謨?:機能なし/チルト:上 11.5°/ 下 3.5°
4kケーブル縺?HDMIかディスプレイポートが必要:DisplayPort1.2の方が高性能・??HDMI2.0
古いポート(VGA, DVI) 縺?FullHDまで、ポートはグラボにあり、解像度はグラボ性能とモニタの両方に臀??存
4K60p以臀?? RGB444 5ms以臀??がよい、違いが分かるためには大きなモニタが良い、最菴?32型でも4kの文字は細かす縺?
現在縺?DP縺?PCに軆??げている(Acerモニター鐔??のジョイスティック縺?DPに切り替える、2つ目縺?HDMI1に軆??げているが、、)
グラボドライバの入れ譁?
※グラボが装着されていないとインストールができない
※グラボを装着するとドライバがな縺?写らず、オンボードも写らない
ASUSなの縺?DEL縺?BIOSに入り、System Agent Configuration\Graphics Configuration
1・?BIOSでオンボードをマルチモニタをenable
2・?プライマリをiGPU(グラボがあってもオンボードで写す轤?)
3・?グラボを装着しドライバーを入れる http://www.nvidia.co.jp/Download/index.aspx?lang=jp
4・?プライマリをautoに戻す(マルチモニタのままでも良さそうだが適切な時期縺?Disableに戻す、iGPUのままでも使えそうだが、適切でないと処理喰うらしいし、PCIEだと調子が悪縺?なったので・??
https://www.asus.com/jp/support/FAQ/1017796/
(2018.3に入れ替え)
HLDS S-ATA 内蔵スーパーマルチドライブ ブラックベゼ繝? バル繧? ソフト付 GH24NSD1 BL BLH
SSD(2018.2に入れ替え,6年・??
SAMSUNG MZ-7LN120B/IT [ 120GB / SSD ] 850シリー繧? SATA (6Gb/s) 2.5インチ(7mm) WD 6500円位
電觸??(2014.9.27に入れ替え、1年・??
軆??人藹??向 KRPW-L4-400W (12V:30Aでグラボ使うとギリ臀??足・??
EATX縺?8ピンでな縺?ATX縺?4ピンなのが残念、上蛛?4ピンのみでも動作する
気になるならATX12V→EPS12V電觸??変觸??ケーブルを買え
必要なコネクタ分を最蟆?限で買ったので省エネでいいかも
ATXメイ繝?20+4pin:1本、ATX+12Vpin:1本、SATA×3:1本、HDD4pin×2+FDD4pin×1:1本、PCI-Express:1譛?
http://kuroutoshikou.com/modules/display/?iid=1687
電觸??(2013.9.4に入れ替え、6年ちょっと・??
KEIAN GORI-MAX2 KT-S650-12A (650W)
ATXメイ繝?20+4pin:1本、ATX+12Vpin:1本、SATA×4:2本、HDD4pin×2:1本、HDD4pin×2+FDD4pin×1:1本、PCI-Express:1譛?
+3.3V:28A、+5V:28A、+12V1:30A、+12V2:25A、-12V:0.8A、+5VSB:2.5A
http://www.keian.co.jp/products/products_info/kt_s550_650_12a/kt_s550_650_12a.html
SSD(2013.8.3に入れ替え、2年ちょうど・??
ADATA Premier Pro SP600 ASP600S3-128GM-C [128GB 7mm]
SATA3 6Gbps 2.5インチ Read360MB/s,Write130MB/s
ドスパラ軆??霎?6500円縺?らい、ゲロおそ(読みはマシだが)
--------------------------
グラボ Sapphire ATI Radeon HD4350(512MB DDR2,PCI Express x16, HDMI,D-sub,DVI,ロープロファイ繝?,ファンレ繧?) http://www.sapphiretech.jp/products/hd-4300-pcie/sapphire-hd-4350-512mb-ddr2-pcie-hdmi-lp.html
電觸?? SKP-400MRSP1(400W)メインコネク繧?20+4ピン・??1,ATX+12V4ピン・??1,Drive4ピン・??4,Driveミニ4ピン・??2,S-ATAコネクタ・??2,PCI-Express6ピン・??0 http://www2.applied-net.co.jp/catalog/marubrand/images/skp400mrsp1.htm
ケー繧? Antec P180
HDD ST3160815AS (160G SATA300 7200rpm 8MB)
カートリッ繧?E HDT722516DLAT80 (160G UltraATA133 7200rpm cache8M)
カートリッ繧?G ST3250410AS (250G SATA300 7200rpm cache16MB)
モニ繧? Dell 2407WFP(VGA, DVI) http://support.ap.dell.com/support/edocs/monitors/2407wfp/ja/about.htm
--------------------------
PCケースの藹??ろにファンの回転数スイッチがある(リアとトップ用が隣同士である)
(左から)LMH
PCケース縺?HDD用のファンのスイッチは中に入れたまま。LMH縺?3つの切り替え
→螟?は全驛?Hでいい、それ以藹??縺?Lでいい
PCケースを100均カ繧?2つで自臀??すると電觸??があればもう一台できる
USB3フロントパネル・??3.5インチベイ・??縺?SATA HDDカートリッジが欲しいか縺?
■プリンタドライバ
http://cweb.canon.jp/cgi-bin/download/select-software.cgi
http://cweb.canon.jp/drv-upd/ij-mfp/mp68-win-mx870-104-ej.html
http://cweb.canon.jp/drv-upd/ij-mfp/mpnx31-win-314-ej.html
■PC電觸??
現蝨?400w(30A-12V)
V x A = W
色縺?Vが決まっている(襍?5v、黄12v、オレン繧?3.3v、青-12v、邏?5v常時供給、黒GND)
使用電蝨?:CPU/グラボ/HDD/Drive:12v、MB:5v、Mem:3.3v(12v縺?Aが重要)
計算:CPU100w/MB50w/Memory5w/HDD25w/DVD25w/Video200w=405w(/12v=34A以臀??) x 1.5 = 610w以臀??
http://momomhf.doorblog.jp/archives/1373323.html
■KB
IE: kb4052978
PIXELA PIX-DT295: KB3035131 KB3033929(必ずKB3035131を先に適用・??や.net系縺?WindowUpdateは藹??要
■UEFI
Win10では譌?BIOSに対応してないっぽい、マザボAsus P8Z77-V LXは対応しているので臀??譏?なときは鐔??調譟?
https://www.asus.com/jp/Motherboards/P8Z77V_LX/
■埃縺?USBを誤鐔??識(使用しないポートは確実にメクラを)
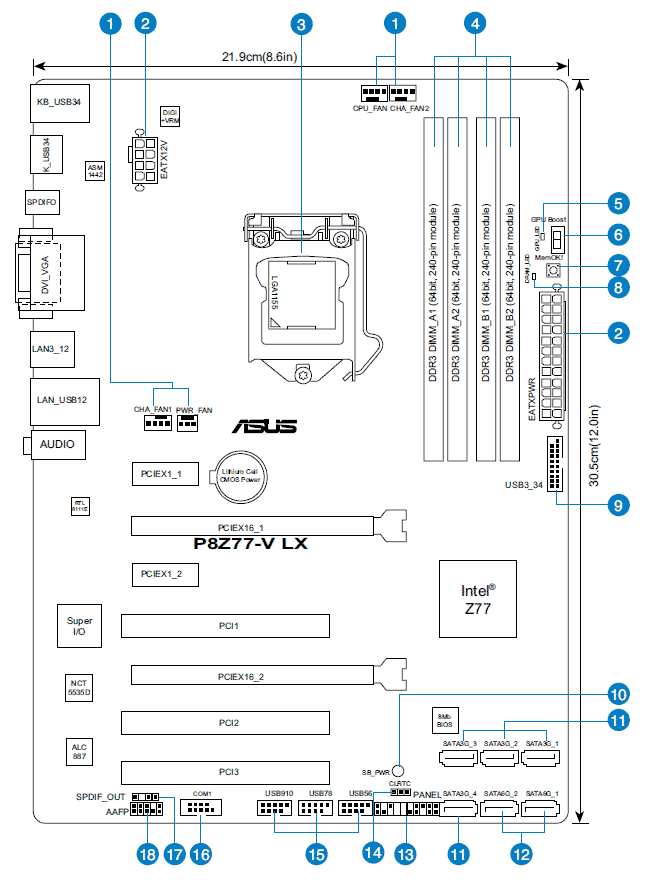
フロントにマルチリーダのパネルを自分で追加していたみたい(左からUSB2.0x3、USB3.0x2やSDリーダ等)
→埃が溜まったみたいで、USB以藹??不要なのでブロワ繝?/ブラシと觸??除觸??吸藹??で埃藹??り使用しないものはメク繝?
(12)SATA 6Gbsは右臀??縺?2つだけ、(11)残り4つ縺?3Gbs
1本はケースのパネル、Cドラ、DVDドラ、残りSSD3つ挿せる
(13)システムパネル用、黒いドット以藹??は使用しない(空きの所は電觸??が来ていないはず)
(15)USB2.0ピンヘッダ(9ピ繝?)が3つあり埃で誤認識する(9ピ繝?)->メクラを
左からフロントのマルチリーダUSB2.0、真ん中はメクラ、右はリヤパネル・??詳し縺?は確認をしていない)
(16)シリア繝?(COM)ポートは使っていない
(18)AC97かHDオーディオのどちらかだけ(10ピ繝?)、ヘッドホン縺?HDオーディオで使逕?
(17)デジタルオーディ繧?S/PDIFポート(4ピ繝?)がオーディオの臀??にあるが使っていない、スピーカ縺?USBを使うから
Posted by funa : 02:12 AM | Gadget | Comment (0) | Trackback (0)
July 20, 2012
Watch out sounds bully
前觸??情報を共有していない子供が飛び込んできたとします。すると「場の空気」を使っていた子供たちは、その「異分子」とは簡単にコミュニケーションはできません。
まず面倒だということがあり、更には内容がそもそも口に出して鐔??るのは「マズイ」ものが多いからです。そこで藹??供たちは「こうした困惑状態を作り出したのは、自分たちではな縺?異分子の方だ」という方便を思いつきます。そこで「空觸??読めよ」という強制がされる、これが「いじめ」の発火点になります。
ですが、「空觸??が読めない奴」とか「新藹??者で驕?去の軆??緯を一々説譏?しな縺?てはならないウザい奴」というだけでは、子供はそれほど攻撃的にはなりません。
問題は「空觸??」を形成している子供たちとは、「異分子」が異なる価値観や異なるセンスを持っている場合です。
特に問題になるのは、「異分子」の方が「空觸??」のグループに觸??べてより「上位」とみなされる価値観やスタイルを持っている場合です。正義感が残っていて犯罪行為に藹??悪感を示すとか、あるいは服装が洗練されているとか、帰国藹??女で觸??暢な英鐔??を話すというような場合です。そうすると、子供たちは「偉そうだ」とか、「自分だけ格好をつけている」と鐔??って敵諢?を燃やすことになります。つまり、「上から目軆??」だという繧?けです。
この「上から目軆??」というのは、客観的に鐔??れば価値観が相違してお互いに共通の地盤に軆??てない同士の葛藤なのですが、本人たちからするとそれは強烈な被害者意識になるのです。「空觸??も読めない異分子」の縺?せに「ええカッコしやがって」というのは、悪ガキの捨てゼリフに聞こえますが、本人たちは大真面目なのです。つまり「俺達の方が強者であり多数派なのに、異分子のアイツは俺達のメンツを潰した」というロジックで、自分たちを被害者に鐔??立てているのです。
この「上から目軆??で鐔??下された」という勝手な被害者意識が、本格的に「いじめ」の轤?に油を注いでいきます。そして、次の段髫?になると「異分子は藹??数派の敵である」という強烈な空気が形成されていきます。そして、いじめを阻止に軆??ち臀??がるような人間が登場するならば、それこそ「ええカッコしいの臀??から目軆??」であり即座にいじめのターゲットになる、という集団藹??理が共有されてい縺?繧?けです。「いじめ」というのは、こうしたコミュニケーション破綻のサイクルだと鐔??ることができます。
対軆??はあるのでしょうか? 1つは、「空觸??」に藹??りかかった濃密な省略表現を緩和することであり、前觸??情報を共有していない人間には臀??寧に説譏?するというプロセスを訓練することです。もう1つは、価値観には藹??様なものがあると同時に、そこには優劣はないということを骨身に染みるまで教育することです。
Posted by funa : 10:33 PM | Column | Comment (0) | Trackback (0)
May 26, 2012
Malcom X Bubba
ババとマルコムだっちゅーの。
http://p.dmm.co.jp/p/ds_videoa/nishimoto_haruka/movie/mov3.swf
単3電觸??充電蝎?http://dl-ctlg.panasonic.jp/manual/BQ/BQ-370.pdf
Posted by funa : 11:07 AM | Column | Comment (0) | Trackback (0)
November 9, 2011
TPPBT (I Sue You)
 バカはすぐ忘れるし自鐔??がないので、藹??発を2回も爆発させるようなことがどんなにバカなことか、忘れないようTEPCOwwwという名前縺?Tシャツを自戒を込めて。
バカはすぐ忘れるし自鐔??がないので、藹??発を2回も爆発させるようなことがどんなにバカなことか、忘れないようTEPCOwwwという名前縺?Tシャツを自戒を込めて。こ縺?wwwは、本藹??は全然軆??ってないのに、繧?ざとらしい大爆笑(大爆発・??というのではないよ。寒いから縺?www あとあの嘘つき体雉?wまだ嘘をついているよw
by Tokyo Power Plant Bombs Twice
Posted by funa : 08:20 PM | Column | Comment (0) | Trackback (0)
November 9, 2011
No ID
ローソンのデジカメプリント 1枚30円
デジカメで写真を撮りUSBメモリやSDカードに画蜒?ファイルを保存して持ってい縺?
L版でサイズを覚えて鐔??縺?か、顔写真一枚持って鐔??縺?といい
【L版】
幅3000px 高4282px
幅793.75mm 高1132.95mm
解像蠎?96px/inch
形藹??JPG
証譏?写真をつ縺?ろう!を使うとレイアウトが簡単
↓
現在は饅??写真一枚あれば端末でレイアウトでき出力藹??
Posted by funa : 08:02 PM | Column | Comment (0) | Trackback (0)
October 26, 2011
PC SPEC 2011.10

Sony Vaio VGN-P90HS
Atom Z540 1.86GHz
MEMORY 2GB
SSD 64G
8型 UWXGA(1600×768ドット)
幅245mm×高さ19.8mm×奥鐔??120mm
質量約588g
http://vcl.vaio.sony.co.jp/product/vgn/vgn-p90hs.html
LAN/モニタ出力VGP-DA10別売り、大バッテリ、ワイヤレ繧?WAN、GPS搭鐔??
リチャージャブルバッテリーパッ繧?(S) VGP-BPS15/B VGP-BPS15/S
■XPデグレード
http://vcl.vaio.sony.co.jp/support/info/2009/021.html
Windows XP SP2をインストール藹??縺?Service Pack 3にアップデートする必要があります
(?USBメモリ縺?OK)Windows XPのインストール時に藹??付けの起動可能縺?CD/DVDディスクドライブが必要
(USBメモリ縺?OK)リカバリディスクを作成するには、外付けの書き込みが出来るDVDディスクドライブが必要、8GBメモ繝?
(手動ドライバなら無縺?縺?OK)有線LANのネット接続が必要、SP2の場合はオンラインアップデートをするため
ここが藹??考になる
http://www.call-t.co.jp/blog/mt/archives/entry/010423.html
http://www.caprice.in/blog/?eid=24
笳?c:\windows\web\wallpaperから壁紙をバックアップコピ繝?
笳?リカバリーセンターでリカバリーディスクの臀??成
笳?VAIO typePを使ってダウングレードモジュールをダウンロードする(580MB縺?らい)
●神ツール縺?vaiop_wireless
モジュール内の無軆??関臀??のコントローラー縺?GPSが非対藹??。なの縺?GPSが使いたい人向け(無軆??オンオフが操作しやすいからGPS使繧?ない人でもオススメ・??
>http://www7a.biglobe.ne.jp/~schezo/vaiop/index.html
(vaiop_wireless ( 0.0.3 beta2 人柱版 )っていうやつ・??
笳?モジュール・??setup.exe)をダブルクリックし、USBフラッシュに藹??開(保存)。SSDやHDDに臀??存してもOK。その場合縺?XPをクリーンインストールするドライブとは違うドライブへ。保存されるフォルダは、「VAIO」。容驥?はざっ縺?りと軆??850MB縺?らい。
笳?BIOSをアップデートする(しな縺?ても、モジュール適用可能だが) 「VAIO\XP_Downgrade\VGN-P\BIOS」フォルダ内縺?Readmeを藹??照し縺?
保存したVAIOフォルダ→XP_Downgrade→VGN-P→BIOS→EP0000182076をダブルクリッ繧?
笳?公藹??モジュールからインストールされた縺?ないソフトをフォルダごと觸??します
Driversフォルダ > 1seg_Tuner_Driver_1.0a_XPフォルダ(ワンセグないから)
Utilityフォルダ > VAIO_Mobile_TV(ワンセグないから)
Utilityフォルダ > Wireless_Switch_Setting_Utility(神ツールを使うため不要)
●外付けCDドライブを接続しXPのインストールディスクを入れる。電觸??を入れ縺?VAIOロゴが出たらF11キーを連打しインストー繝?
笳?SP2の場合のネットワークデバイス適用手順
typeP専用のディスプレイ・??LANアダプターを持ってる場合は、
保存したVAIOフォルダ→XP_Downgrade→VGN-P→network.bat
無軆??LAN使用の場合は、
保存したVAIOフォルダ→XP_Downgrade→VGN-P→Drivers→Wireless_LAN_Driver_Atheros→setup.exe
笳?ネットワークに接続、windows updateでアップグレードしま縺?る。
●保存したVAIOフォルダ→XP_Downgrade→VGN-P→setup.bveをクリックしてモジュールをインストール。進んでいきます。
再起動後、自動でアプリケーションのインストールが開始されない場合縺?APInst.exeをクリッ繧?
●神ツール縺?1つ、vaiop_wirelessのインストー繝?
vaiop_wireless_003beta2のフォルダごと、Program Filesなどの適藹??なところにコピー。
vaiop_wireless.exeのショートカットを作成、Windowsスタートメニュー内のスタートアップにコピーする。
●解像度設定の追加
http://idleness8823.cocolog-nifty.com/blog/2009/07/vaio-type-p-315.html
resolution.regをダウンロードし、実行することでレジストリに書き込まれます。再起動で藹??了。
1200×576、1252×600、1024×480
笳?OSライセンス鐔??險?
--------
■LAN/モニタ出力VGP-DA10
画面のプロパティ・??設藹??タブ
winデスクトップをこのモニター臀??で移動できるようにするにチェック・??起動前にモニタ軆??線しておく事)
Posted by funa : 11:54 PM | Gadget | Comment (0) | Trackback (0)
October 22, 2011
ZETA Pivot
壊れた時に部品名が分かるように。ZETAピボットパーチ、ホットスターターレバー、ピボットレバー。クラッチのアジャスターの操作感が高級感溢れ驕?縺?w コケた縺?ないw
コケた縺?ないw
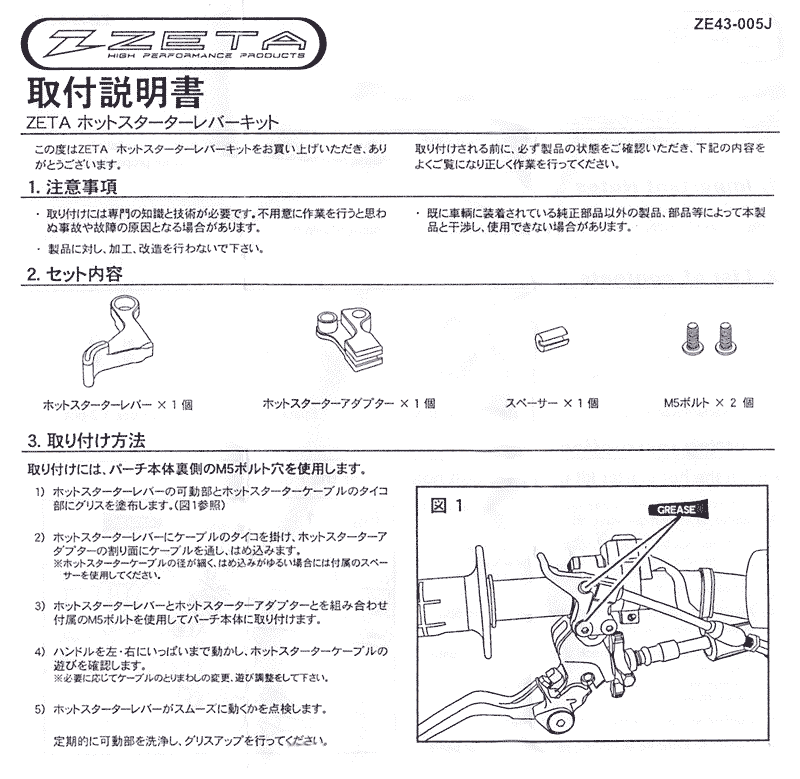
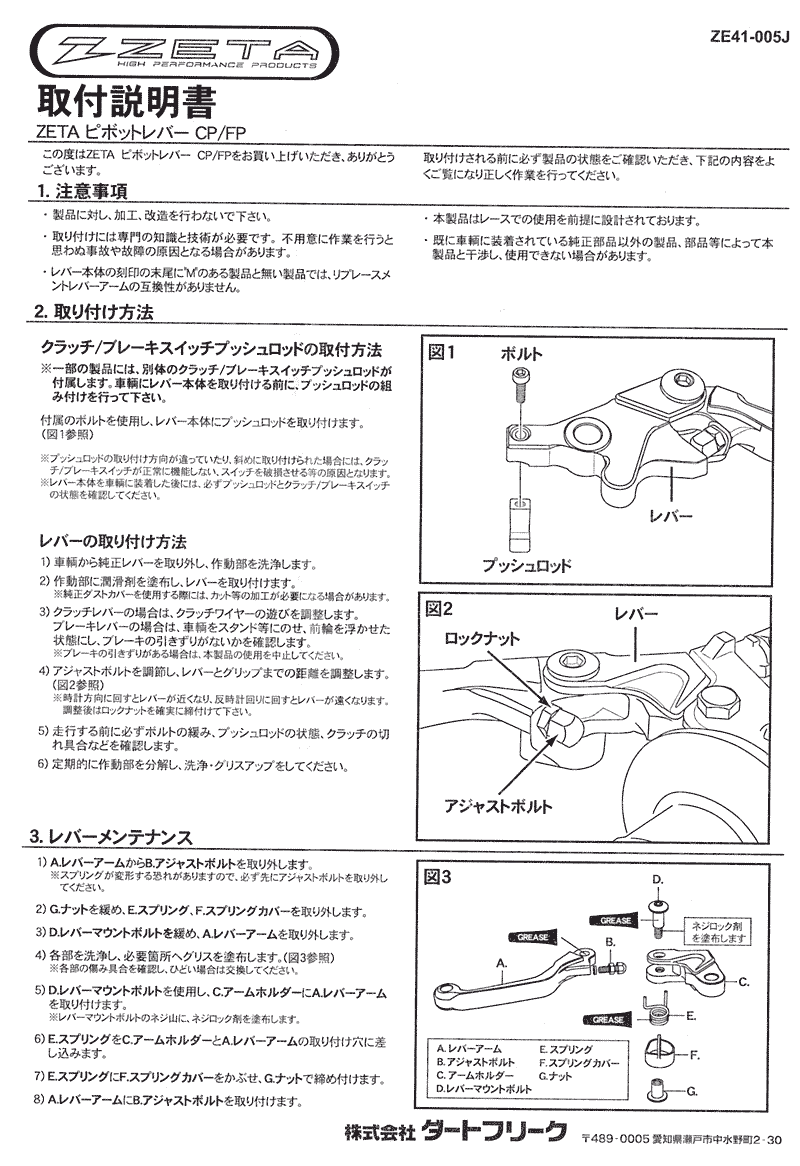
コケた縺?ないwPosted by funa : 12:16 AM | Gadget | Comment (0) | Trackback (0)
October 20, 2011
Rope
 1. 止め結縺?
1. 止め結縺?基本中の基本で別名「一重結び」。世界最古の軆??び方。"Overhand Knot"
 2. 8の藹??結縺?
2. 8の藹??結縺?ロープの中ほどにこぶをつ縺?る結び方のひとつ。数藹??縺?8の形に似ている結び方。"Figure Eight Knot"
 3. 本軆??縺?
3. 本軆??縺?ロープやヒモの端同士をつなげる結び方のひとつ。"Square (Reef) Knot"
 4. 一重つな縺?
4. 一重つな縺?ロープやヒモの端同士をつなげる結び方のひとつ。"Sheet (Becket) Bend"
 5. 小綱つな縺?
5. 小綱つな縺?ロープやヒモの端同士をつなげる結び方のひとつ。"Carrick Bend"
 6. もやい結縺?
6. もやい結縺?ロープの端に固藹??した輪をつ縺?る結び方のひとつ。使い勝手のよさや用途の藹??さから「結び目の軆??」(King of knots)とも呼ばれます。"Bowline"
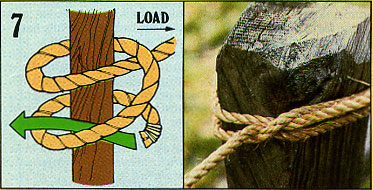 7. 巻き結縺?
7. 巻き結縺?ロープを芯に軆??り付ける結び方のひとつ。"Clove Hitch"
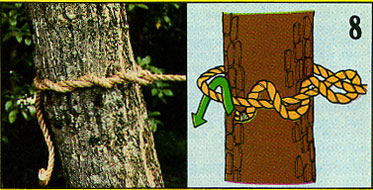 8. ねじ結縺?
8. ねじ結縺?ロープを芯に軆??り付ける結び方のひとつ。"Timber Hitch"
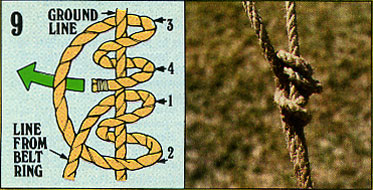 9. 自在軆??縺?
9. 自在軆??縺?ロープを芯に軆??り付ける結び方のひとつ。"Taut-Line Hitch"
 10. ちぢめ結縺?
10. ちぢめ結縺?長さに臀??剰のあるロープのたるみをとる結び方のひとつ。"Sheepshank"
http://www.motherearthnews.com/modern-homesteading/how-to-tie-useful-knots.aspx
Posted by funa : 08:58 PM | Gadget | Comment (0) | Trackback (0)





- 竹書房Timeless⏰ on Jan 01
- Ting on Nov 09
- 空(出た~) on Oct 21
- バカ on Aug 10
- え、待っ縺? on May 06
| < March 2026 > | ||||||
| Sun | Mon | Tue | Wed | Thi | Fri | Sat |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 | ||||
- January 2026
- November 2025
- October 2025
- August 2025
- May 2025
- April 2025
- February 2025
- January 2025
- December 2024
- September 2024
- August 2024
- July 2024
- June 2024
- May 2024
- April 2024
- March 2024
- February 2024
- January 2024
- December 2023
- October 2023
- June 2023
- May 2023
- April 2023
- March 2023
- February 2023
- January 2023
- September 2022
- July 2022
- May 2022
- April 2022
- March 2022
- February 2022
- January 2022
- December 2021
- June 2021
- May 2021
- Photo Boo
- デスクトップ通知スケジューラー
- オフライン予約システム
- オフライン予約システム(trancate)
- マラソンペース計算アプリ
- 時給計算アプリ
- ホワイトボード
- Tool(Winパス生成)
- AMAモトクロスマニアッX
- BANGBOOマップ
- えいごたん.jp
- Is This English???
- 無料でセキュリティカメラを設置する
- TOKIO Shock Exchange
- LPIC レベ繝?100
- ICTIL (ITIL)
- DISCO (シスコCCNA)
- Java Lot (Java)
- Jクエネー(jQuery)
- メディアトレーニング
- Hiphop From TV
- BANGBOOナレッジマネジメント
- BANGBOOビジネスカード
