May 6, 2025
え、待って→カルチュラル・アプロプリエーション
↓
のっとりばっかり
これはいいのっとり、焼売で食当たりしてイオマグクッソしたシューちゃんです、とオッサンが言っている(昔見たユニコーン以来だが観て良かった、逆位相は起こせる>ハサウェイパンプ禁も見てた
マチュの即断即決でタフな感じ、強い少女像、好感度高い
宇宙世紀はあまりに争いと悲しみに満ちているので、ジークアクス時空の輝きは良いものだ
https://www.msn.com/ja-jp/news/opinion/ar-AA1HxTJz
複数の調を重ねて斬新な音響を生み出す複調
キーに属さない音やコード(転調やセカンダリーなど)のオフキー
スケールを意図的に外れた即興的な音使いのスケールアウト、aiko skirt不協和音かね
質問:アルミホイルで電磁波は本当にカットできますか?電子レンジでも使われている2.4Ghz帯の波長は6mmの穴を抜けられない大きさ
アルミは遮断物質として優れているが半球では逆に電波を集めてしまう、隙間がないように覆う必要がある
Design at the speed of AI
Stitch - Design with AI3Dプリンタ(欲しい部品があるなら作ればいいのでは)
「3d プリンター」「プロダクトデザイン」から探す | ココナラAutodesk Fusion | 3D CAD/CAM/CAE/PCB が1つに集約されたソフトウェア | 無料体験版 メカを触るならこの辺か、AutoCADとかMayaとか3D系ある
(1) ストリキ on X: "きたぁ 2時間格闘して内部の機構解明した これで作れる https://t.co/ziHEcfeezr" / Xわずか2000円で10年使えるソフトバンクの超格安SIM「1NCE」3000万回線突破、世界中で使えて対応デバイスも続々登場 | Buzzap! 1年200円で50MB、1日150kB?週1レポート等か?IoT SIMでセンシング等で使える
■100均
DIYフック(1×4用、角S型、ブラック) - 100均 通販 ダイソーネットストア【公式】ビニールネットケース(A7)抗菌すべり止めシート(アイボリー) - 100均 通販 ダイソーネットストア【公式】エンボス加工食器棚シート(抗菌、クリア) - 100均 通販 ダイソーネットストア【公式】ゴキブリ用ホウ酸ダンゴ8個入 - 100均 通販 ダイソーネットストア【公式】Posted by funa : 06:06 PM
| Gadget
| Comment (0)
| Trackback (0)
April 16, 2025
AIエージェント MCPサーバ
■MCPサーバによる連携
Model Context Protocol(MCP)の基礎に関して、社内勉強会で使用したスライド資料を公開します! | DevelopersIOroo-logger: Cline Memory Bankとは違うAIの記憶システムを(MCPで)作った理由MCPサーバー自作入門MCP入門MCPを活用した検索システムの作り方/How to implement search systems with MCP #catalks - Speaker DeckリモートMCPサーバーカタログ #AWS - Qiitaプログラマー必見!FastAPI-MCPでAI時代のAPI開発を加速する方法(初心者向けコード付き) #Python - QiitaMySQLのスキーマ情報を圧縮して提供するMCPサーバーを作った - $shibayu36->blog;MCPを理解する - Speaker DeckローカルRAGを手軽に構築できるMCPサーバーを作りました[B! MCP] MCPサーバーを使って請求書作成から送付まで自動化してみた話MCPアーキテクチャパターン - Carpe DiemClineとDDDと私 - コドモン Product Team BlogGemini CLI の簡単チュートリアル[B! AI] Cline利用におけるデータの取り扱いについて - サーバーワークスエンジニアブログCline駄目そう?一般的な規約という声もある
Clineのデータの持ち方 一応通信はないらしい
Cline - AI Autonomous Coding Agent for VS CodeWE CLAIM NO OWNERSHIP RIGHTS OVER YOUR USER CONTENT. とはあるが再利用に使わないという意味ではないらしい
Privacy. By using the Service, you acknowledge that we may collect, use, and disclose your personal information and aggregated and/or anonymized data as set forth in our Privacy Notice.とあるのでな
■構成
MCPホスト:Cline等のAIエージェント
↓
MCPクライアント:Json設定のProxy (これ以降が狭義MCPサーバ? あるいは全体でMCPサーバ)
┣→ここでコマンドを打つように設定すればそのままローカルがEPになる
↓ (uvはPythonパッケージ管理/仮想環境ツール) uv run python src とか
API EP
■外部APIに通信かローカルか2種類と考えていい
stdio ローカルのサーバと通信
remote リモートのサーバと通信(SSE→Streamable http)
メッセージはJSON-RPC2.0
ローカルにおきDockerを動かす形
機能は3つ
Resources:事前に情報をファイルで読み込ませる感じ
Prompts:プロンプトのテンプレ設定しておく感じ
Tools:使うツールを設定しておく感じ
(MCPクライアントは2つ:無意識でいい)
Sampling:MCPを使うよ~
Roots:MCPを使うファイルシステム確認~
これで人間が操作していた内容をMCPで実施するようにする
LLM→人間→Github/Slack/GCP etc.
↓
LLM→MCP→Github/Slack/GCP etc.
■MPCサーバとは何者?
Model Context Protocol (MCP)は、特にLLMを活用するアプリケーションにおいて、モデルとのやりとりを標準化するためのプロトコル
API EPやローカルプロセスをMCPサーバと言っているケースもあるが、MCPの文脈からするとMCPサーバは仲介。MCPクライアントは広義のMCPサーバに含まれている
MCPにおける構成
[ユーザー] -> [LLM (MCPクライアント)] --> [MCPサーバ] -> [API/CLI/ローカルプロセス】
■github-mcp-server設定
GitHub - github/github-mcp-server: GitHub's official MCP ServerGithub トークン発行はココで→ https://github.com/settings/personal-access-tokens
クラシックトークンのrepo全体でも良さそう
MCP Marketplace>Remote server>Edit configuration>下記コードをコピペする
{
"mcpServers": {
"github": {
"command": "docker",
"args": [
"run",
"--rm",
"-e",
"GITHUB_PERSONAL_ACCESS_TOKEN",
"ghcr.io/github/github-mcp-server"
],
"env": {
"GITHUB_PERSONAL_ACCESS_TOKEN": "github_pat_xxxxxxx"
},
"disabled": false,
"autoApprove": []
}
}
}
上手く行かないので、Cline自身にMCPサーバの調整をしてもらうと下記となった (Docker、DockerGroup、Proxy等)
{
"mcpServers": {
"github": {
"command": "sg",
"args": [
"docker",
"-c",
"docker run -i --rm -e GITHUB_PERSONAL_ACCESS_TOKEN -e http_proxy -e https_proxy ghcr.io/github/github-mcp-server stdio"
],
"env": {
"GITHUB_PERSONAL_ACCESS_TOKEN": "github_pat_xxxxx",
"http_proxy": "http://proxy:3128",
"https_proxy": "http://proxy:3128"
},
"disabled": false,
"autoApprove": []
}
}
}
■ローカルサーバ
//// UV
curl -Ls https://astral.sh/uv/install.sh | sh
cd /mnt/c/Users/unco/Desktop/local_test/MCP/kuso-app
uv venv 該当ディレクトリに仮想環境を設定
source .venv/bin/activate アクティベート
uv pip install google-cloud-asset
uv pip freeze > requirements.txt
python3 main.py
deactivate 停止
gcloud auth application-default login --no-launch-browser
gcloud auth login --no-launch-browser
消したければ、venvを削除するだけ
上記はpip+requirementsだが下記の方がいいかも、add+tomlで管理
uv init myproject (myprojectディレクトリ、tomlファイルが作成される)
uv add numpy
uv remove numpy
nv sync
uv lock
uv tree
uv python install 3.10 3.11
uv python list
uv python pin 3.11
uv tool install ruff
uv tool list
uvx pytest 一時的に仮装環境を汚さず実行
uv exports --format-requirements.txt
権限確認API(analyzeIamPolicy)
curl \
'https://cloudasset.googleapis.com/v1/projects/prj-xxxxx:analyzeIamPolicy?analysisQuery.accessSelector.roles roles%2 Fbigquery.dataowner&analysisQuery.identitySelector.identity=user%3Axxxxx%40xxxxx.com&key=[YOUR_API_KEY]'\
--header "Authorization: Bearer $(gcloud auth print-access-token)"\
--header Accept: application/json' \
--compressed
※APIキー不要だた、HTTPやJSの方法も出る
parentでエラーがでてもscopeという意味> organizations/123, folders/123, projects/my-project-id, projects/12345
400 Missing parent field in request. [field_violations {
field: "parent"
description: "Missing parent field in request." }
↑
■2023-04-24
Dialog flow ES - Chatbotの作り方
対話式アプリの有効性>何か対策をしときたい
Dialogflow:FAQのチャットボットを作りたい
intentをFAQの数だけ作る
intentグループがあれば纏められるが、、
色は赤や青で分ける必要がある? entitityは色だが単語で分ける
entitiy: colors、単語:赤、類語:Red、朱色等
単語:白、類語:ホワイト等
entitity 個別項目(色、サイズ、キーワード)トレーニングフェーズで使う用語を設定しておく
intent 意図(選択、買う、確認、支払)チャットで引きあたる項目で、数多く作ることになる
上の2つを結びつきを強くするcontext
input context 該当のインテントの変遷の一つ前の別名を指定
output context(コンテキスト用エイリアス名) 該当のインテントの別名を設定する
Training phrases(想定するユーザの入力文)
Responses(答えへの反応
料金 無料の範囲である程度賄える
項目を500から選ぶとしても大丈夫 外部のデータソースを使う(できそう)
色を10個を選択するとしても大丈夫
結果を外部に連携することもできそう
AI型は入力された質問に対して、FAQから適切な回答を表示(正誤で学習し判定上がる)
シナリオ型は入力値から分岐を判定して進む、あみだくじタイプの定型処理に持っていく
■Dialog flow ES
下記の辺りを設定すれば、チャットボットが回答するようになる
ESとしては、ユーザ入力を構造化データにする処理を行いパラメータへ検索を掛ける挙動となっている
ユーザ行動の履歴から検索ヒットの改善を学習するタイプのAI
インテント分類(ユーザの意図のパターンを設定)
┣トレーニングフレーズ(質問の例文を指定)
┣アクション (何を実行するか指定)
┣パラメータ/エンティティ(質問から抽出すると型を指定)
┗レスポンス (何を返答するか指定)
コンテキスト: input (一つ前のインテント〉 と output (当インデントの別名)
イベント:エンドユーザーの発言からではなく、発生したイベントに基づいてインテントを呼び出す
アクション: デフォルトfallbackにはinput-unknown がついている
パラメータ:下記くらいの考慮で良さそう
@sys.any キーワードを設定してしまう?
@sys.url
@sys.person ロールや役職を設定してしまう?
@sys.email
■Agent 設定
Agent > ML setting > Train でトレーニングさせる。
megaでなく普通のエージェントの方が分かり易い?
Agent > environment > publish パブリッシュし公開?
■ intent
テキストレスポンスにタグが使えずリンクにならない。
ユーザエクスプレッションの単語をドラッグ反転させ techinical_terms 等で検索するとEntityを反映することができる。
(Entity登録済みなら熟語でもOKだが、未登録なら単語で設定したような)
■Entitiy 設定
業務で使用している重要用語は @technical_termsとして作り、揺らぎを全て入力したい
BigQuery: BQ、ビッグクエリ、、、
個人情報: パーソナルインフォメーション, PII、、、
■Integration設定
WebDemoを有効化
DialogMessangerを有効化(こっちのがCoolでは
■FAQを簡単に構築するコツ
検索を網羅するように質問を重要単語を全て入れた形で複数設定する
代表的な質問をレスポンスに入れてしまうとFAQとして分かり易い
参考になりそうなの一例を回答します。
Q「ああああ」
A「いいい」
■思うような結果にならない場合のチューニング
トレーニングフレーズを追加するのが基本
できるだけキーワードをEintity化することもよい方法
Trainingに過去キーワードがあり正誤判定することができる
Validationにトレーニングフレーズの追加等の問題提起が出ているので対処
Posted by funa : 07:57 PM
| Web
| Comment (0)
| Trackback (0)
February 4, 2025
現代思想
現代思想
■ニーチェ(1844-1900) - ルサンチマンからの脱却
- 強者に対して羨望と恨みを抱いてきた大勢の弱者たちは、「強者は悪」という否定的な評価を下し、「弱者こそが善い」という価値評価を作り上げた。キリスト教的価値観を奴隷道徳と呼ぶ。
- 恨みや怨念を行動によって晴らすことができないため、想像の中の復讐によってその埋め合わせをはかる心の動きをルサンチマンと呼ぶ。
- 人間にとって本当の意味で正しい行為は、感情的なもので、生の実感と直結した自然なものなはず。快が伴う力の高揚感にこそ道徳の本来の根源がある。
- 高貴な者とは、自分の生を肯定できるも者、奴隷とはこの肯定力がスポイルされた者。弱者=奴隷、強者=高貴な者と呼ぶ
- キリスト教道徳では、利他的であるべきという要請に基づく義務的行為だが、高貴な者の人助けは力の発現に基づいている
- 自分を弱者として捉えたがる過剰な自意識の殻から自らを解放し、身体から溢れる力(大いなる理性)を取り戻せと主張した
- 神も天国も道徳もなければ人生の目的も価値もない、あらゆる肯定的な世間的な価値も超越的な価値をも拒否し何も信じない立場をニヒリズムと呼び、すべてが無意味なものとなった後も宗教が約束する来世を拒否し受難や苦痛を含めた生そのものを肯定し無意味な永遠の繰り返しに耐える存在となるよう鍛えよと説く
- 余談:キリスト教が偶像崇拝を認めないのは、それが本来の信仰ではなく良い人っぽく見せるための自分のための行動だから
■マルクス(1818-1883) - 疎外論
- 車がまったく通るはずのない道路で赤信号を待っている。これは本来的な危険の有無から疎外され、信号機という装置に支配されているということ。疎外とは自らが作り上げたルールに支配されることを意味する。
- 本来の労働の意味から疎外され不幸せになるために働くなど、疎外を克服するには社会の諸関係そのものの矛盾を分析することが課題。
■アーレント(1906-1975) - 全体主義
- ナチスドイツとスターリン統治下のソ連を総括して全体主義と呼ぶ。
- 全体主義政権が勢力を握るに至った最大の要因として、階級社会から大衆社会への移行を挙げる。小作農、地主、商工業者、貴族、僧侶など、それぞれの利害を共有する集団(階級)に分かれていた。そこで政治を運営するため議会制民主主義(代議制)をとり各党が利害を調整し最終的に多数決で議決をしていた。階級社会がWWⅠによって終わりを告げた後、大衆社会が到来した。人々は階級へと組織されず一人ひとりバラバラな為に政党や政治から吸引力が失われ、また大衆自身もいつでも取替えがきくという寂しさを持った。そうした状況に寂しさを埋めてくれる共通理念や共同体幻想を与えてくれるものとして全体主義が登場した。
- 全体主義には政治的目標はなく、経験的な現実に向き合うよりも、正しく深い現実を把握していると現実逃避的に一方的に宣言するだけと解釈する。そこで重要なのは、可能な限り人を運動に参加させ(人数と時間)組織し高揚させることだけであった。(洗脳)
- 大衆は一人ひとりバラバラであり、議会は代表の場でない状況下、大衆が求めたのは共通の理想像である独裁者であった。全員に共通する像などあり得なく空疎であると喝破する。
- 余談:バラバラになり大衆化することは、全体主義化しやすく独裁者を生みやすい。階級社会の脅威である。
■フロイト(1856-1939) - 無意識、超自我とトラウマ、転移
- 18世紀末ウィーン上流階級の患者(変調が身体上に現れるが肉体には目立った病がない)の自分では意識できない葛藤を探り出し、これに適切な解釈を通して意識化させると患者の症状が解消されることを発明した。意識の深部には我々を支配する自分では意識できない領域=無意識があることを確信した。理性が人間に判断・行動させているというそれまでの哲学・思想の根拠を崩し、人間は非理性的であるとした。
- 無意識が欲動によって構成されていること、置き換えや圧縮によってその形を変え、何とか自我の検閲を逃れて、意識の中に侵入しようとすること(夢の中や言い間違え、やり損いといった失錯行為にそれは現れる)、さらに動悸やヒステリーといった神経症の諸症状は、無意識と自我の争いの結果、抑圧された欲動が意識を介さずに直接肉体を支配しようとするものであることを指摘した。
- 精神分裂病の場合は、無意識を抑圧する機能を果たす自我が何らかの原因によって崩壊することにより無意識(欲動)がそのまま露出した症状とかんがえられる。
- 無意識は我々を真に支配するものであり、そのままの形では絶対に意識化できない。
- なぜ自我は無意識を抑圧しなければなくなったのか?赤ん坊は自我を持たず、心も組織化されておらず、あるのは本能の欲求(欲動)だけである。この人称性のない快楽原則の心的状態をエスと呼んだ。しかし成長するにつれ本能の満足を一時的に断念したり延期したほうがかえって快楽を達成しやすいことに気づいていく。現実に合わせ必要な迂回をして快感に達することを目指す現実原則が作られていく。我々の自我とは、こうしたエスと現実の矛盾を調節する役割を果たすために生まれた機能に他ならない。両親の機嫌を損ねない事は快楽の必須項目であるから両親のメンタリティをよく学習する必要がある。いやそれよりも両親像を自我の一部として内在化してしまうのが一番である。これが超自我である。自我は、超自我の意向を汲んで現実原則を働かせエスの欲動を抑圧する。このとき抑圧され意識内に居場所をなくした欲動が無意識を形成するのである。
- 超自我の意向を汲んで行動しているのに快楽を受けられないのなら、とんでもないことになってしまう。自我の危機は容易に訪れるだろう。そうなってしまった場合には全力を挙げて無かったことにしなければならない。こうした事件が作る傷が精神外傷=トラウマである。トラウマも無意識の領域へ押し込められることになるが、それは消滅したわけでなく常に明るみに出ようとし自我はそれを抑えようとする。見方を変えればその葛藤こそが今ある自分を形成した原動力であると言える。
- 神経症の患者たちが自分では意識できない葛藤を探り出すために自由連想法を使った。この方法を使うと患者は心理的に退行していき幼年時代の体験が甦ってくる。ところが治療がある時点に達すると患者の自由な連想が滞ってしまう。これを患者の自我による無意識的な抵抗ととらえた。つまり連想が隠していた核心に近づいたため、せっかく抑圧に成功した欲動がこのままでは意識の明るみへと引き出されてしまうと、自我が必死の抵抗を始めたのである。この抵抗は認知したくない欲動を抑圧したときに働いた患者の自我の作用とおなじものである。そう考えたフロイトは、隠している事に分析の焦点を合わせた。するとついに患者の抑圧した葛藤が生き生きと再現されることになった。それは甦った幼児期の感情や欲求を分析者に叩き付けるようにして現れた。この現象が転移=transferenceである
- 余談:ケアの方法として、トラウマになった事柄を超自我に伝え、超自我が悪かったと超自我に謝ってもらうことで傷を癒していく。超自我に甘えヨシヨシしてもらう、幼児期をやり直すのである。超自我(親)が支離滅裂な場合は自我が作れない
■ユング(1875-1961) - 普遍的無意識
- ある妄想型分裂病患者が現れ、太陽にはペニスがありその動きが風の原因であると告げた。そこから分裂病者の幻覚や妄想には世界の様々な神話や伝説や昔話などと極めて類似性の高いイメージや主題があることに気づいていく。彼はここから、人間の意識の底には精神病者にも正常者にも、また時代や文化を異にする人々にも共通な心の層があると推論しそれを普遍的無意識=collective unconsciousと名づけた。
- この意識の深層を通して太古から現代まで遺伝してきたイメージが元型=archetypeである。これは日々経験するありふれたことから意義ある行動を創出するパターンである。アニマ=運命の女性、英雄、影、老賢者、アニムス=男性などがあり、英雄の元型を自分に投影して勇敢になったり、影という元型を人に投影して絶対的な悪人として見たり、運命の女性を見出したり、女性は自分のアミムスを嫌悪て女らしくなろうとする。
- 余談:スターウォーズは、英雄=ルーク、アニマ=レーア姫、アニムス=ハンソロ、影=ダースベーダ、老賢者=オビワンなど元型が勢揃いしておりヒットしたと言われる
■ベイトソン(1904-1980) - ダブルバインド
- もう子供じゃないんだから自分でやりなさい、まだ子供だから一人じゃ無理。親の言うことを聞きなさい、お父さんのような人になってはいけない。このように論理的な矛盾があり人間を行動不能に追い込むのがダブルバインド=二重拘束である。ダブルバインド状況が作り出すディレンマは子供の精神に深いダメージを与える。これを避けようとする心的規制こそが分裂病の主要な原因の一つとなると考えた。
- ダブルバインド状況下では与えられた命令に完璧に従うことが不可能で、妄想型は妄想に落ち込むことによって命令を無化する。破瓜型はすべてを文字通り=リテラルにとらえることで命令の文脈を無化する。緊張型は自分の内面だけに集中し外界にないものにする。こうすることで解決不可能な状況に必死に抵抗するのである。
- 余談:両親以外の兄弟や祖父母など意見の違うものがいればダブルバインド状況に縛られることが少なくなるだろう
=====
マネジメント-基本と原則
成果をあげるマネジメントこそ全体主義に代わるものであり、われわれを全体主義から守る唯一の手立てである
■戦前のマネジメント
1)生産性向上のための科学的管理法
2)組織構造としての連邦分権組織
3)人を組織に適合させるための人事管理
4)明日のためのマネジメント開発
5)管理会計
6)マーケティング
7)長期プランニング
■新たなニーズ(マネージャは起業家であるべき)
知的生産性を上げる
マネージメントをグローバルに行う
■マネージャの役割
部分の和よりも大きな全体、すなわち投入した資源の総和よりも大きなものを生み出す生産体を創造すること
ただちに必要とされているものと遠い将来に必要とされるものを調和させていくこと
■マネージャの仕事
1)目標を設定する
2)組織する
3)動機付けとコミュニケーションを図る
4)評価測定する
5)人材を開発する
■コミュニケーション
コミュニケーションは、知覚であり、期待であり、要求であり、情報ではない
コミュニケーションは知覚の対象であり、情報は論理の対象である
コミュニケーションと情報は相反する。しかし両者は依存関係である
情報は、感情、価値、期待、知覚といった人間的な属性を除去するほど有効となり信頼度も高まる
=====
経営組織論
■組織と人間
1)賃金
目的達成の効率的達成を目指し組織は歯車であり、人間は賃金によって働く経済人。
2)人間関係
人間は友情・集団への帰属・安定感の欲求など社会的欲求で動機付けられる社会人。また非公式組織にも属し、感情を中心に動き、感情で業績が決まる。
非公式組織:人々の間に共有された規範や感情あるは態度で結び付けられた非公式の組織、メンバーの行動は影響される
苦情を述べる機会を与えるとモラルが良くなる->社会的欲求があることが分かる
3)自己実現
個々のメンバーは自己実現の欲求を持っている意味探求人。人間は意味の充足(働き甲斐や生き甲斐)を求めており自然に働く
職務拡大:職務が労働者に、より多く、より重要な意味のある内容になるよう職務を再編成し新しい仕事を与え単調感による労働意欲の低下を防ぐ
職務充実:仕事の契約や工夫、ペースなどに自主性を持たせ、働き甲斐、生き甲斐の職務によりモチベーションを高める
4)組織投資
絶えず変化する環境の中で将来のため組織の有効性を維持するためメンバーの技術や能力に投資することを主張する
5)指示系統
意思決定者の能力の限界により組織がある、メンバーの中には考えたくないフォロワーもいる
■組織の形態
職能部門別組織
生産、研究開発、営業などのライン部門(命令の一元性)
経理、人事、総務などラインに対してサービスを行うスタッフ部門
専門化による技術的利点、人間関係を重視しており調整面で有利
全体的視野に欠け、部門間のコミュニケーションが困難
将来のトップの知識が片寄る
事業部制組織
事業規模が大きくなると複雑化を避けるため
事業部レベルでの意思決定、独立採算
部門間の調整の必要性が少ない
ゼネラルマネージャの育成に適する
メンバーのモチベーションが高くなる
マトリックス組織
人的資源を有効に使える
組織が複雑になるため、一時的なプロジェクトチームや共同計画に用いられる
■風土の判定
閉鎖的:評価、統制、策略、中立、優越、確信
オープン:記述、問題志向、自然、感情移入、平等、暫定
■業績に対する関心 x 人間に対する関心
9x9)仕事に打ち込んだ者が業績を成し遂げる。組織目的という筋を通し各人の自主性が守られ信頼と尊敬による人間関係
1x9)和気藹々として仕事の足並みもそろう
5x5)仕事を成す必要性と職場士気がバランスよい
9x1)業績中心に考え、人のことはほとんど考えない
1x1)与えられた仕事のため最小の努力を払えば、心地よく過ごせる
■率いやすい組織
組織のタイプ:課業を重視(大よそ良いが時には最悪になる)、人間関係を重視(可もなく不可もない)
リーダとメンバーの関係:良いほうがよい
課業構造:非定型的より定型的がやや良い
リーダの地位の権力:強くても弱くてもどちらでも
※どっちでもいいので、天才的なリーダでないなら、普通以下のリーダをやりながら成長していく戦略も
■リーダ
-伝達
変革の意味、理念、ビジョンを明確化しメンバーに共有させる
自己の信念や理念、組織の使命、ビジョン、基本方針を明確に伝達することが必要
メンバーとのコミュニケーションによって意味や価値、解釈の不一致を取り除いて共通性を生み出すことが必要
-秩序
組織について多様な解釈という多義性を除去することによってある共通の解釈ないし意味の共有化を図り、組織としてひとつのまとまった価値体系を構築し秩序を維持していく役割を負う
-コンフリクト解消
変革に対するメンバーの抵抗を解消する
環境の変化や危機的状況を避けるよりも、それを利用して変革のきっかけを作り出す
-変革
すでに確立されている秩序や価値を変革できる
変革によって得られる利益をメンバーに保証する
変革型リーダシップとは、組織のためと部下の利己心を超越させる
リーダーシップは環境の変化に対応して組織のコンテキストを絶えず変革して組織を存続発展させる過程である
-能力
抵抗を排して新しく創造する創造的リーダシップ、理想や価値の高さ、実現しようとする意思の強さ、環境とその認識能力、説得力が必要
■コンフリクト管理
コンフリクトは良くも悪くもない、解決しようとせず管理する
高い業績に導く最適レベルのコンフリクトがある
コンフリクトからイノベーションを発見できる
創造的なコンフリクト管理には、他人の立場、より広い視点、より長期的視点、高い視点でコンフリクトを考慮することが必要
■コンフリクトの源泉
心理:価値観や好き嫌い、目標、態度の違い
組織:地位や役割、責任の違い
環境:風土、政治、宗教、文化の違い
コミュニケーション:使う言葉の違い
■コンフリクトの解消方法
1)当事者間での議論
2)上位目標の設定
3)与える資源の拡大
4)回避、撤退、冷却期間
5)調和
6)妥協、第三者の介入、交渉評決
7)上司の命令
8)態度や行動を変える、訓練
9)組織の改編
10)多数決
11)玉虫色(解決案を曖昧にしてどのような意味にでも解釈できるようにする)
12)共通の敵
■コンフリクト解消のスタイル
回避:自己の保護
抑え付け:他人の要求を一切聞かない自分の要求を主張
同調:他人との調和
妥協:中間案
統合:双方の要求を満たす最善案を見つける
■状況がコンフリクトを解消する場合がある
官僚型:問題を先送りする間に状況が変化し、問題でなくなる
独断実行型:自己に有利になるようコンフリクトでなく状況を変える
偶発的譲歩型:状況が変化し譲歩せざるを得なくなる、ソ連の体制崩壊型
状況対応型:場当たり的に対処療法をする内に解消している
創造的問題解決:従来にない新しいコンテクストを作り価値観を変える
■モラル
モラルの高い人→普通業績が高くコンフリクトを隠す
モラルの低い人→普通業績は低くコンフリクトを生む→改善しやすい
モラルが高い人がコンフリクトを生む:リーダの資質がある
モラルが高いの人のコンフリクトは有益な事が多く、リーダや組織が気づいて対処しコンフリクトを管理すべき
発言することでモラルが高まる、発言できる環境を作る
■ビジョン
ビジョンの内容は、現実的で信頼ができ魅力的な将来
正しいビジョンはコミットメントを引き起こす
理想が高いよりは保証があり長期に続くものが良い、理想が高くなくても短期的でもビジョンはエネルギーになる、ビジョンに保証があれば絶対的パワーとなる、高すぎると逆進的
間違ったビジョンを持てば危険な方向に加速していく、長期的視点とコミュニケーションの取れる運営が間違いに気づかせてくれる
説得力を持たせるには、高度で深いスキルが必要
ビジョンはコンフリクトの解消に貢献する
=====
■ハーズバーグの二要因理論
動機づけ要因と衛生要因があり、給与や休暇は衛生要因で上げてもやる気は上がらない。疎かにすると下がる。下記には社会的意義とか自分の正義は入っていない
動機づけ要因として:
達成感:目標を達成したり、困難な課題を克服した際の満足感
承認:上司や同僚からの評価や感謝の言葉
仕事そのもの:業務内容が興味深く、やりがいを感じられること
責任:重要な役割や責任を任されることによる自己成長の実感
昇進:キャリアアップの機会や職位の向上
成長:スキルアップや自己啓発の機会
■恋愛がもたらす健康効果
ストレス軽減:恋愛によってオキシトシンが分泌され、ストレスホルモン(コルチゾール)が減少。仕事のストレスも和らぐ。
心臓に優しい:血圧が下がり、心臓病のリスクが低減。スキンシップで副交感神経が優位になりリラックス効果も。
免疫力アップ:幸せな気持ちのポジティブな感情が免疫機能を向上させ、風邪をひきにくくなる。
健康的な生活習慣を促進:長生きや魅力向上を意識し、運動や食生活の改善につながる。
幸福感アップ&うつ病予防:セロトニンやドーパミンが分泌され、幸福感が増し、うつ病のリスクが低下。
※孤独はパートナーが不調を発見し助けることがないため、すぐ死ぬ、ザコシ
Posted by funa : 09:27 PM
| Column
| Comment (0)
| Trackback (0)
January 31, 2025
Corporate Law, Accounting, General Affairs, and Labor
会社法、経理、総務、労務
■会社法
ルールが専門的、お金と決議>人事
自主で学ばないと平民から隠してる感ある、落とし穴多い
株式会社、合同会社、合資会社(地方の酒造)、合名会社(実績0)の4つ
日本の合同会社LLCはパススルー課税(法人利益でなく構成員の所得税のみ)がない
合同会社は議決権や配当が定款で柔軟にできる
合同会社は所有と経営が分離していない、社員がオーナーかつ業務執行者
類似商号もok、同一商号同一本店は駄目、類似で損害賠償のリスクは有り
代表取締役が複数なら代表取締役印も数だけある>ややこしい
株式会社は出資比率に応じた議決権、普通決議でも主席した株主の過半数要る
他に特別決議(2/3必要)や特殊決議(3/4必要)がある
51%や議決権なし株発行が良いかも
優先株式:議決権が多く割当される種類もある
取締役会は必須でなくなった
するなら取締役最低3名と監査役か会計参与、3ヶ月に1回以上必要
取締役の数は上限がなく多すぎや複数は良くない
取締役会非設置なら1株でも株主提案権行使できる、設置なら100分の1が要る(あるいは議決権300)
重要な財産処分、多額の借財、利益相反取引、譲渡制限株の承認等は取締役会が要る
株主総会や取締役会は開催せず書面決議にできる
株主総会は代理出席ok、取締役会はリモートでも出席必須
計算書類:貸借対照表、損益計算所、株主資本等変動計算書、個別注記表
持株会社の割当株数は出資比率でなく貢献度等で自由にできる
利益相反取引に注意 社長が会社からお金借りる、取締役となっている会社と取引等
社外取締役/監査役は10年役員でなかったり親族不可の要件がある
特別決議(2/3必要)→ 会社の重要な変更(定款変更、M&A、解散など)
- 定款の変更
- 取締役・監査役の解任
- 資本金の額の減少
- 募集株式の有利発行(特定の者に有利な条件での新株発行)
- 自己株式の取得(特定の株主からの取得)
- 事業の全部または重要な一部の譲渡
- 合併・会社分割・株式交換・株式移転
- 解散(例外あり)
特殊決議(3/4必要)→ 株主に大きな影響(種類株式の変更、株式取得の変更など)
- 種類株式の内容変更
e.g.普通株式を優先株式に変更する場合
- 種類株式の取得条項の追加・変更
e.g.一定期間後に優先株を買い上げ、退職時にstock op買う条件を付与
- 会社が特定の条件で株式を取得できるようにする変更
- 全部の株式の取得条項の設定
- 会社がすべての株式を取得できるようにする定款変更
e.g.M&Aや持株会社化や株主の整理の為に買い上げが記載される
- 閉鎖会社(譲渡制限会社)の株式譲渡制限の厳格化
e.g.株主総会の承認が必要になるよう変更する場合
- 会社の組織変更(株式会社から合同会社への変更など)
金の貸し借りや株>条件をつける
新株発行、新株予約権、社債、借入、助成金等の金策がある
vcの投資で議決権が無くなったり、契約上出来る事が縛られる>弁護士等と要確認
株発行は公募、株主割当、第三者割当の3種
venture capitalへの決まった割当なので第三者割当ということ
vcはキャピタルゲイン狙いなので上場しなければ金を返して欲しい>株式買取条件
条件は代表権、議決権なし、黄金株の拒否権、譲渡制限、配当、残余財産等
特定事項のみ議決権あり、取得請求権(5年後以降に買取等)
非公開会社(譲渡制限で株を譲渡不可)なら属人的株式で条件を変えられる
DES =debt equity swap 社長の会社への貸付金を株発行に変えるスワップ等
社債は取締役会だけだが、新株は株主総会と登記が必要で、新株予約権付社債は急げる
1億、引受人50名以上で銀行か信託銀行の社債管理者が必要
キャッシュで返済なら新株発行しないということ
全部取得条項付種類株式
特別決議で決定可、無償でも可なので、苦しくて100%減資の条件で融資とかの時
この株主は反対したい、買取請求や差止め請求
敵対的少数株主排除のキャッシュアウト、株式併合でもできる
濫用で株主総会決議取消の対象になる
売渡請求
単独議決権90%以上の特別支配株主が全部買える、特別決議不要
協力者から一旦取得して再分配は税務リスク等がある
転換社債:事前に定めた価額で株にできる社債
コンバーチブルノート:株に転換する際に株主総会や登記する契約上のもの
役員の構成>機関設計>幾つか形態がある
役員の任務懈怠には損害賠償責任がある、免除を定款に入れられる
監査役会設置会社
取締役会+監査役(会)、従来型の日本企業の標準的な形態
業務執行は取締役(兼務可)>トヨタ、ソフトバンク
指名委員会等設置会社
取締役会+3つの委員会(指名・監査・報酬)、執行と監督を分離しガバナンスを強化
業務執行は執行役>ソニー、日立
監査等委員会設置会社
取締役会+監査等委員会、中間的な形態で監査機能を取締役会に統合
業務執行は取締役(兼務可)>任天堂、楽天
代表取締役、取締役
取締役は会社の基本方針を決定する
執行役(指名委員会等設置会社のみ)
執行役は取締役会の決定に基づいて実務を遂行する(取締役は会社の基本方針を決定する)
執行役員 会社法上ではない
従業員の最上級、取締役の手前などマチマチ
登記簿に載せる取締役を減らす、意識決定の迅速化
ストックオプション 役員や従業員への新株予約権
新株予約権
行使し株式の交付を受ける、登記が必要、約束した金額は支払う必要
登記変更申請に3万等のお金や手間が掛かる
新株予約権の内容変更は新株予約権者全員の同意が要る
多重代表訴訟
親会社の株主が子会社の役員を訴えることができる
M&A
他地域進出、不採算部門の売却、後継者不足等の理由が多い
表明保証 前提として守るべき事項を決め違反で損害賠償など
事業譲渡 債権者保護不要、労働者承継等手続き不要、登記不要
債権、債務、労働者の個別の同意要る
子会社株式譲渡 影響が大きい場合のみ株主総会の特別決議
消滅会社の株主に合併新株を交付、あるいは交付金や三角合併
交付金は税務上適格合併にならないしキャッシュアウトで無効請求もある
外国会社の親会社の三角株式は消滅側の株主総会の承認が難しい
免責の登記 商号を継続利用で旧会社の債務は負わない登記
組織再編スキーム
合併、会社分割、株式移転、株式交換、事業譲渡、株式譲渡、組織変更
吸収合併 事後処理が規則整備や社風等で負担、事前に税務会計社保等外注したい
三角合併 親会社の株式を合併の対価として渡す
簡易合併、略式合併 一定の場合は株主総会不要、規模が小さいや既に大株主の場合
会社分割 負債のみを分割会社に残すのは濫用、債権者は詐害行為取消か履行請求を訴える
会社分割の労働契約
分割会社か承継会社か協議や異議申立、出向
MBO 後継者問題で経営幹部がオーナーから買う、融資を受けたりで
ダブル公告で催告を省略 官報と電子公告等
解散 大体、取締役が清算人をする
特別清算手続き
破産手続き
みなし解散 12年登記なしで
役員の任期は最大10年なので通常は再任の登記をするはず(原則は取締役2年、監査役4年)
有限会社>特例有限会社(有限会社はもう作れない)
役員の任期に制限なし、決算公告義務なし、株主間の株譲渡自由
外国会社
支社 合同か株式会社
支店 登記だけでOK
上場
譲渡制限は廃止
募集株式発行は有利な金額で発行する等が無ければ取締役会で決議できる
有利発行等で既存株主に不利のため差止め請求を受けたり
支配権が変わるなら通知か公告が要る、10分の1反対で株主総会の承認が要る
減資
債権者保護が要る、時間が掛かる、印象も悪い
助成金の為や、欠損補填し減資した上で他から増資等の理由が通常ある
大会社(資本金が5億円以上、負債総額が200億円以上)
監査役の設置が必須
会計監査人(公認会計士または監査法人)の設置義務
■労務管理のツボとコツ
超高齢化社会、長時間労働は無理、効率化の改革が必要
柔軟な働き方、同一労働同一賃金
採用は適切でない年齢制限は不可
面接で聞けない
本籍、出生地、生い立ち、生活(間取り)
家族、職業、地位、収入、資産
信条、労働組合等
試用期間14日、延長や有期変更も可(解雇予告は要る)
5年超の契約社員は無期切替の主張が出来る
社員ではなく無期、定年後採用の場合は主張無理
クーリング期間6ヶ月の途切れがあれば期間通算できない
残業 1日8時間、週40時間
36協定で月45時間、年360時間
繁忙期の特別条項、月100時間等にできる
月60時間超は5割増
管理監督者の残業代不要(深夜は出るが)
パワハラに該当する可能性
暴行、傷害等の「身体的な攻撃」
傷や暴言等の「精神的な攻撃」
無視等の「人間関係からの切り離し」
進行不可能なことへの強制や仕事の妨害等の「過大な要求」
能力や経験とかけ離れた程度の低い仕事を命じること等の「週小な要求」
私的なことに過度に立ち入る「個の侵害」
接待、ゴルフの経費が会社でも労働時間にはならない
インターバル規制で終業時間から次の始業時刻の間に最低でも連続11時間の休息が要る
健保の傷病手当金で三分の二が最長1年6ヶ月間でる
8割以上出勤するとバイトでも有給要る、日数は勤務時間で違う
備品等の損害賠償を社員に請求できる
合同労組は社外で一人でも入れる
労働審判は3回まで、初回までに全ての主張と証拠を出す
就業規則は雇用形態に係わらず10名以上で届け出必要
社員代表の意見書添付、不利益変更は大方の同意か合理性が必要
みなし労働とは?労働時間の計算が難しい場合に、実際の労働時間にかかわらず事前に定められた労働時間を働いたとみなす制度
===========
善管注意義務(民法
忠実義務(会社法
業務上のミスで会社に損害を与えた場合一部の損害賠償責任を負うことがある
業務上横領、背任:会社の資産を私的に流用、不正な融資等
企業秘密の漏洩や営業秘密の不正利用
個人情報を勝手に外部に提供
インサイダー取引
ハラスメント・差別
大企業が下請企業に対して不当な取引を強いる
投資の落とし穴=儲け話が向こうから来ることはない、退去通知はいつか?各入居者の家族構成や滞納率や入居開始日などのリスト、現地確認
誠実さが希少化しつつある社会 - ゆうれいパジャマβSFCで4年生の人が美しいプレゼン資料でなめらかな弁舌でとんでもなくショボい成果物を発表。1年生は割とプレゼンは下手だが、時間をかけてそれなりの成果物を仕上げている人が多かった。つまり大学でそのハッタリスキルが磨かれていた
対立している状態でも誠実な敵のほうが嘘つきの味方より百倍マシでリスクを回避するのが必須スキル、まず人を信じない状態をデフォルトにしておく必要がある
Posted by funa : 11:15 PM
| Column
| Comment (0)
| Trackback (0)
January 3, 2025
竹書房 p probability diddy
高確率なものは本能的行動
■勘違いが人を動かす 教養としての行動経済学入門
論理も情熱も人を動かすには弱い
不安や同調や本能を使い勘違いさせ誘導する、思考の穴を突く
人は安定思考なのでバグらせないと行動変容させられない
ハウスフライ効果:特定の情報を繰り返し目にすることで、その情報が正しいと信じてしまう心理的バイアス
癖付け(教育も癖付け、広告も詐欺も思考に癖付ける、同調圧力もある種
心理的距離:共感度、遠ければ苦手な人とも上手く行く(共感せず上辺だけ)
相手の嫌なことは嫌なことで返し強化させない
生理的欲求
食欲:生命維持に必要なエネルギーを摂取したいという欲求
睡眠欲:休息し、心身を回復させたいという欲求
性欲:子孫を残したいという欲求
社会的欲求
愛情欲求:他者と親密な関係を築きたいという欲求
所属欲求:集団に属し、仲間と繋がりたいという欲求
承認欲求:他者から認められたい、尊敬されたいという欲求
自己実現欲求
成長欲求:能力を向上させ、自己実現を達成したいという欲求
創造欲求:新しいものを生み出したいという欲求
防衛本能
危険回避:危険な状況から身を守りたいという本能
闘争本能:敵や脅威に対して戦おうとする本能
逃避本能:危険な状況から逃れようとする本能
■思考の穴
思考には不具合がある、無知で勘違い
何もわかっていないし、実は何もできないが出来る気になっている
不眠に睡眠時間を増やすべき、では解決にならないだろ、相関や因果は分かれ
メカニズムがあると思い込むと因果関係に相関関係がなくても信じてしまう
綿密な計画を立てることでスムーズに進むと錯覚し逆に酷くなった→見積の倍を確保するとよいが、思考の穴があるやつの見積とは何ぞや?
確証性バイアス、信じたことの裏付けの証拠ばかりを集め強化する、幸福度は高いが悪循環なら最悪→反芻しない、one more brand new day、正反対のことを検証すると避けられる
流暢性の罠→動画を見ると踊れると勘違い→訓練をちゃんとする
歴史、文化、経済、政治の信条的なバイアス→強い拒否感で問題になり易い、公正に公共の利益を守る別システムを意識的に再構築するしか
因果関係を誤信させる→共通点・類似性を提示しよう、原因と勘違いしてくれる
大数の法則では少数より大数が常に優れ誤謬が避けられる→大数の統計データより個人のストーリーを発信し影響力を行使
平均への回帰→調子がありより良い時もあればより悪い時もあるが好まれる方を押し出す
ネガティビティバイアス→5%避妊に失敗より95%避妊成功の方が印象良いので言い方
保有効果→保有による愛着で痛覚、鎮痛剤が効き痛覚が低いと冷静、昔は損=死であったが現代は損切りも必要
押入から全部床に出して何を残すか(コンマリ断捨離で保有効果を回避し収得する感覚にする
損失回避→期待値よりリスクを見て損をさけようとする、これも痛覚→期待値で設計するより得する感覚を押し出す
利己→他者が置かれている状況を重ねられるようにする→ワーストケースシナリオを共有する
子供は嘘をつけない、他者の考えが違うことを知らないから、サイコパスと同じ利己
遅延割引、確実性効果→遅れて得られる報酬の価値は割引れる、苦痛も先延ばししがち→即効性や100%を約束する
マシュマロ待ちテストでまてた子はsatが高くなる、待つ期待値を正しく評価した方がいいかも、gritにも繋がる
自己管理能力の高く社会的経済的地位が低いと心血管疾患が多い
困難なタスクには極端にハイレベルな自己管理力が必要
中レベルの自己管理力は高困難タスクにうまく対処できなかった→スーパーマンでなければ個人の幸福度を優先した働き方が良い?
ア●公には必要な教養、高慢かつ神経質だから人気?→少し新規性があったが具体的には自分の経験として詐欺的に試すしか実感でけへんなぁ
■ベイズの定理
原因Xが起こったもとで結果Yが起こるというのが条件付き確率の計算式
P(Y|X)= P(X,Y)/P(X) X→Yが起こる確率をXで割っている
↓
ベイズの定理は、結果Yが起こったもとで原因Xが起こる確率が分かるという逆を出せる
P(X|Y)=P(Y|X)P(X)/P(Y) 条件付き事後確率を原因Xで掛けて結果Yで割るとYかつXである確率が分かるという神の数学
↓
元々の確率が尤度(ゆうど、likelihood、もっともらしさ、新しいデータ)を受けて確率がどう変化するか計算できる
■ユダヤの商法 藤田田
合理、契約、ケチ、疑い深い、信用、仕事お金至上
金を巻き上げる/お金は奪い合い
取引額を倍々に増やし現地を耕した後に進出して直売りに変更等エグイ
日本の大企業の社員は自分の力を過大評価し世界では通用しない
食を楽しむ
宗教上休みをきっちり取るし、食を楽しむやイイ女を囲ったり楽しんでる
風呂でシッカリ体を洗い清潔
金持ち、女と口、好きなものより苦手なものを売った方が割り切れる
ターゲットは金持ち/女性を狙う等、これは確実に見習いたい
田さん陳さん東大でGHQに通訳アルバイトし19に弟子入りし銀座のユダヤ人になった
買い切りかリピート購入/サブスクか、買い切りは長く続ける商売でなく店を畳んで違う商品をやる
広告投資管理7割:年間に支払う平均金額(1年LTV)>客一人獲得に掛かる広告費上限(CPO)
■確率思考の戦略論
客引きもバンカーも運転手も世界各国で同じ雰囲気>法則がある
ブランドに対する好意度:preference=ブランドイクイティ+価格+製品パフォーマンス
プレファレンスが高いものはより高頻度で購入される=>シェア
人はそれぞれのカテゴリのEvoked setを持ってる:エビス50黒ラベル30一番搾り20
プレファレンスに基づいたエボークトセット持ち、その中のカテゴリーの購買回数分だけサイコロを振って選んでいるだけ
Preference好意度(ブランドイクイティ+価格+製品パフォーマンス)+Awareness認知+Distribution配荷
年間購入者の全世帯に対する割合=認知率x配荷率x過去購入率xEvokedSet率x年間購入率
年間売り上げ=総世帯数x1年間に買う人浸透率x平均購入回数x平均購入金額
シェア=参入順位xプレファレンスx宣伝費比率x間合い年数
どれだけ競合に比べて宣伝できているかが大きい
次回購入タイミング=平均購入回数xプレファレンス とかデータ化、確率見ていく
差別化して先鋭化しても自社を選んで貰えるとは限らない
差別化でターゲットを絞ってマーケットが小さくなる危険性
ベストセラー>観光大使/政府/首相>人を巻き込みPRに
コーラは原液販売に注力し現地生産フランチャイズにし配荷拡大した
商品棚をその店/客のプレファレンスに合わせ配荷の質を改善
都合が悪くなるとルールを変えてでも勝とうとする西洋人
スポーツマンシップは油断させるプロパガンダでしかない
サイコパス:感情が意思決定の邪魔にならない>選ぶストレス無しに最適判断できる
+人心掌握(
※勝ち馬しか人は選ばない、第一想起にどう入るか、高くても良い大量の広告を打つ
オペを遅くしてでも行列を作る、先着サイコロ無料話題をつくる、ライトが明かる過ぎるとか目立つ店構え
====
多変量解析
消費者の行動を左右する要素は様々だが、「絞り込むと本質的には3つ程度しか残らない」
最も重視すべきは「プレファレンス(相対的好意度)」。次にどれだけ知ってもらえているかという「認知」、その後、消費財であれば製品の手に取りやすさを示す「配荷」、テーマパークであればパークまでの「距離」が続く。企業が重視しがちな品質や技術力といった「パフォーマンス」の優先順位は低い。「新機能を搭載しただけでは、消費者に響かない」。相対的好意度、認知、配荷のどれかが足りないと、どんなにいい製品も埋もれてしまう。
商圏
テーマパーク業界の失敗例を調べ全国で閉園になった約50の遊園地を見ると、すべて需要を上回る投資をしていました。 需要は商圏の大きさやその人口を調べると分かります。明らかにお金を使ってはいけないところに投資をしていたのです。
可視化
思考力に強みを持つ人を「T(=Thinking)型」、人とつながる力や伝える力が強い人を「C(=Communication)型」、人を率いて動かす力を強みとする人を「L(=Leadership)型」として、3つに分類し可視化。可能性の高い分野に資源を集中。
====
国の大学教育の目標人材「思考力、判断力、俯瞰力、表現力の基礎の上に、幅広い教養を身につけ、高い公共性、倫理性を保持しつつ、時代の変化に合わせて積極的に社会を支え、論理的思考力を持って社会を改善していく資質」
↓
1)分野を超え先端の学問を学び時代の変化に合わせて積極的に社会を改善していく人材
2)高度な教養と専門性がある人材
3)高い実務能力がある人材
■データ解釈学入門
garbage in garbage out ゴミを見てるとゴミしか出てこない
測定が難しい、欲しいデータが取れないことの問題
ランダム要素の和は正規分布が多い
観測のプロセスがデータに既に影響を与えている
ピークが複数ある、外れ値等で分布を見ておきたい
実数を見たら割合も見る
因果関係が特定→メカニズム理解
因果関係がある→介入で影響力出せる
相関関係がある→予測できる
目的変数または従属変数 ワインの質
説明変数または独立変数 天候温度等
両方が量的変数なら重回帰分析
目的変数がカテゴリ変数で説明変数が量的変数ならロジスティック回帰
目的変数が量的変数で説明変数がカテゴリ変数なら分散分析や多重比較分析
目的変数も説明変数もカテゴリ変数ならクロス集計表
予測は例外事象に弱い
内挿=interpolation データ内で完結
外挿=extrapolarion データがない領域の予測
史上最高温度でのアイスの売上(1日2個食べる、暑すぎて外出控え買わない、他の流行
パーセンタイル 大小で並べた特定%分
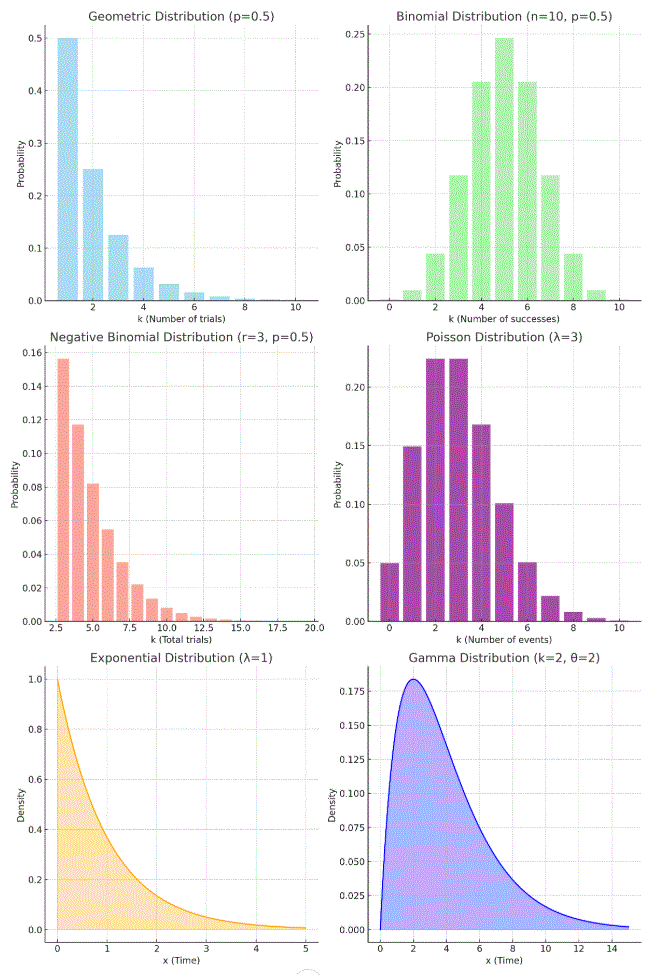
幾何分布
試行を繰り返し、初めて成功するまでに必要な試行回数をモデル化する離散分布。
例: コインを投げて初めて表が出るまでの回数。
二項分布
一定回数の試行で、成功する回数をモデル化する離散分布。
例: 10回コインを投げて表が出る回数。
負の二項分布
成功が指定回数起こるまでの試行回数をモデル化する離散分布。
例: サイコロを振って、5回目の「6」が出るまでの試行回数。
ポアゾン分布
単位時間または単位空間内での稀な事象の回数をモデル化する離散分布。
例: 1時間内に受ける顧客の電話数。
指数分布
事象が発生するまでの待ち時間をモデル化する連続分布。
例: 顧客が来るまでの時間。
ガンマ分布
複数の指数分布の待ち時間を足し合わせた分布。
例: 3件目の電話がかかるまでの待ち時間。
誤差 error
確率分布 probability distribution
正規分布 normal distribution aka ガウス分布
平均値 mean
分散 variance
最頻値 mode
標準偏差 standard deviation
確証バイアス confirmation bias
相関係数 correlation coefficient
交絡因子 confounding factor
因果効果 causal effect
平均処置効果 average treatment effect
実験群 experimental group
対照群 control group ゾロ投薬
重回帰分析 multiple regression analysis
サンプリング調査 sample survey
二項分布 binomial distribution
帰無仮説 null hypothesis
対立仮説 alternative hypothesis
有意水準 significance level
正規性 normality
等分散性 homoscedasticity
樹状図 dendrogram
汎化 generalization モデルが他のデータにも有効
再現性 Reproducibility 他者が同じデータと方法で同じ結果を得られる
Replicability 独立した研究で同様の結果を得られる
特異性 specificity
妥当性 validity
納得感 plausibility
整合性 coherence
類似性 analogy
誤謬 fallacy
■データサイエンス入門
jupyter notebook: pythonの実行環境、googleコラボラトリみたいなもの
分析か機械学習か、この回は分析
プロット打って線形から予測>重回帰分析>説明変数から目的変数を出す
p<0.05場合により0.01なら説明変数に影響力があることが分かる
p値が高いものは抜いたモデルでも良い
定数という意味で切片constant、で、これは必須
交互作用>説明変数の掛け算>特徴量
データから重回帰分析結果を整理してモデルを作成>未来予測
説明変数間で相関が大きいマルチコしていると駄目
y軸との交点という意味で切片intercept
ロジスティック回帰分析は正誤判定の2項分布でS字グラフ、確率
ポアゾン回帰分析は発生回数で、正規分布
セグメント分けk-means、ターゲットのセグメントを予測
次元削減するとセグメントを出せる>寄与率(落した次元が落した情報残存率)
セグメントの意味は人間が考える
pcaならmodel_dim.componentsで要素出現をマップ化できる
セグメントをさらに関係化し階層クラスタリング
クラスタ数推測> エルボー法>自動推測ならx-means
アソシエーション分析> 同時発生調査、DAG関係性
support(同時発生率)、confidence (Aの内のAB同時発生率)、lift (Bの内のconfidence率)
2時間で覚える!Pythonによる機械学習の基本〜教師あり学習編〜【Pythonデータサイエンス超入門】 - YouTube機械学習:ラベルを教えターゲットのラベルを予測
強化学習:報酬の定義を教え、最大化する行動を予想(解釈不能だが精度が高い
回帰問題regression→数値で予測
分類問題classification→ YかNか予測
決定木分析:影響のある順に2択を繰り返す(データ偏りに弱い、精度が低いが解釈しやすい
サポートベクターマシン (SVM: 綺麗に分ける線を見つける
ランダムフォレスト: 決定木を沢山つくり多数決
勾配ブースティング: 決定木を徐々に改善 (精度が高い
精度:結果が分かっているデータを使った回帰モデルの誤差を2乗し平均を取る(平均2乗誤差
分類の精度は横)結果2×縦)予測2=4パターンの混同行列しかない。横の合計が実値、縦の合計が予測値
正解率(全体)
平均再現率(Y/Nそれぞれの正解率を平均: recall)
平均適合率(各予測の正解率を平均:precision)
平均F値(再現率と適合率の調和平均:f1-score)
学習用とテスト用(結果を隠す)にデータを分け、モデルの精度を確認
学習用データでモデルの精度を計測>>テスト用データでモデルの精度を計測→過学習かも、同じ位が良い
↓
分析
プロットを作成し線形性を確認してから予測
重回帰分析を用いて説明変数から目的変数を予測
ML教師なし
クラスタリング(例:K-means、階層クラスタリング)を用いたセグメント分け
強化学習
報酬を定義しそれを最大化する行動を学習(解釈は難しいが、精度が高い)
ML教師あり
回帰問題(Regression):数値を予測(例:線形回帰、ランダムフォレスト回帰)
分類問題(Classification):クラスを予測(例:Y/N、A/B/Cなど)
Posted by funa : 11:55 AM
| Column
| Comment (0)
| Trackback (0)
January 1, 2025
law enforcement
■電子帳簿保存法一問一答
電子帳簿保存法一問一答(Q&A)~令和4年1月1日以後に保存等を開始する方~|国税庁電子帳簿保存法一問一答電子帳簿保存法とは?対象書類や保存要件・改正内容についてわかりやすく解説 | 経営者から担当者にまで役立つバックオフィス基礎知識 | クラウド会計ソフト freee法令/監査対応なら基本はオリジナル側で対応。もしデータロードした業務DB側でも法令/監査対応が必要なら要件を聞いて対応
データロードした業務DB側は利用上の保管の必要性があるようなら削除しない
法令上必要なもの: 帳簿、取引記録、財務、電子帳簿、金融取引、税法、賃金出勤、電気通信ログ、個人情報保護、マイナンバーあたり
検索して閲覧ができ状況を追えるようになっていればよさそう
オリジナルかどうか: EDIは最低の加工ができそう。領収書等は原本が必要。それぞれ要件が細かくある
■GDPR (General Data Protection Regulation)
EUのデータは欧州経済領域EAAの域外に持ち出せなかったのでは?:日本へは十分性認定がありOK?
個人情報や購買情報、行動履歴等の分析やデータ処理ができなかったのでは?
EU域内の個人データを対象
EUに拠点がない企業でも、EU域内の個人(データ主体)のデータを処理する場合にはGDPRが適用される可能性がある
EU域内の個人データを取り扱う場合の例: EU居住者向けのウェブサービス、オンラインストア、マーケティング活動
EU居住者の行動を監視する場合の例:ウェブサイトでのクッキーを使ったトラッキング
GDPRでの個人データは、特定の個人を識別できるあらゆる情報を指します。例えば:
名前、住所、メールアドレス、電話番号、IPアドレス、クッキーID、健康データ、財務情報など
正当な個人データ処理の根拠を確保することが必要です。例えば:
データ主体の同意(具体的で明示的な同意が必要)
契約の履行(契約を遂行するための必要性)
法的義務の遵守(例えば税務関液データ)
データ主体または第三者の重大な利益保護
特に日本の企業がマーケティング目的でデータを利用する場合、明確な同意の取得が重要です。
データ主体(個人)の権利を尊重する。以下の権利を持っています:
データへのアクセス権:自分のデータの確認を求める権利
修正権:不正確なデータを修正する権利
削除権:「忘れられる権利」として知られるデータ削除を要求する権利
データポータビリティ権:自分のデータを他社に移転する権利
日本の企業がこれらのリクエストを受けた場合、適切に対応できる体制を整える必要があります。
データ保護体制が必要です。例えば:
一定規模以上のデータ処理を行う場合、DPO (Data Protection Officer) を任命することが求められます
データの収集、処理、保管方法を文書化し、必要に応じて提出できる体制を整える
必要に応じてデータを匿名化または暗号化して保護する
データ時の対応計画が必要です。例えば:
GDPRでは、データ漏洩が発生した場合72時間以内に監督当局(例:EUのデータ保護機関)および影響を受けたデータ主体に報告する義務がある
漏洩時の対応手順を事前に策定しておくことが重要
日本での具体的対応:
プライバシーポリシーの見直し
GDPRに基づいたデータ収集目的、保管期間、権利行使方法の明記
データ処理者(プロセッサー)との契約確認
データを処理する外部業者(例:クラウドプロバイダー) もGDPR準拠が求められます。契約内容を確認し適切な管理を行う
越境データ移転の対応: EUから日本へのデータ移転には特定の条件が必要です。日本は「十分性認定」を受けており、一定の条件下でEUから日本へのデータ移転が認められます。
+++2010-08-09+++++++++++
個人情報保護法と特定電子メール法 ー Information privacy & antispam law
で下記を書いていたが滅茶苦茶ではないか?古い
■個人情報保護法
- 不要なものは破棄しろ
- あらかじめ伝えた目的外に使うな
- 要求にはできる範囲で対応しろ
- 利用目的、問い合わせ先を開示しろ
- 本人からの照会、訂正依頼には対応しろ
- データを管理しろ、データ委託先を監督しろ(責任はこっち持ちだ)
個人情報は同意を元に収集しその方法でのみ使用
利用目的が変わると同意の取り直しが必要
委託等第三者へ提供する場合本人に同意をとる
第三者から受け取った場合は記録を残す
安全管理を徹底させる
※例外としてのデータ提供が可能
警察、検察、弁護士会、からの照会、国への協力
生命、児童や公衆衛生に関する場合
※過剰反応はするな
5000人以下なら守らなくてもよい
目的に同意をもらえば名簿を配布できる等
http://www.caa.go.jp/seikatsu/kojin/index.html↓
個人を識別できる情報
氏名だけ 携帯のIMEI等の番号だけ 顔写真 生存人物(プライバシーマーク:Pマークは死者も個人情報)
コンテキストによって地域と性別と身長などだけでも個人識別できれば個人情報になりえる
↓
以前は履歴情報や特性情報は氏名を切り離せば良かった
厳しくなるが利用すべきという声も
↓
免許証番号→個人情報
生体情報→個人情報
匿名加工情報→個人情報ではなく商店街や地域連携ができ目的外利用も
個人情報への紐づけをなくさなければならない
類推で個人特定できたもだめ(A町の198cm男はBさん)
匿名加工情報の具体的な作成方法 https://www.meti.go.jp/policy/it_policy/privacy/downloadfiles/tokumeikakou.pdf
■特定電子メール法
- 事前に同意を取れ(オプトイン)
- 同意の時期と方法を記録しろ(送信しなくなってから1ヶ月経過するまで)
- 送付者は誰か、受信拒否の通知先を表示しろ
- 不要意思があれば送るな(オプトアウト)
※次の場合は同意なしに送付できる
名刺をもらった相手、取引関係、サービス契約者に付随的に広告宣伝を含む場合、公表しているメールアドレス
http://www.soumu.go.jp/main_sosiki/joho_tsusin/d_syohi/m_mail.htmlhttp://www.caa.go.jp/representation/index.htmlhttp://www.dekyo.or.jp/soudan/http://www.caa.go.jp/representation/pdf/091214premiums_1.pdfhttp://www.caa.go.jp/representation/pdf/100401premiums2.pdf■警視庁vs総務省
警察庁「サイバー犯罪条約では上限3カ月の保存を要請」
日本のISP事業者の多くが平均で半年間、大手では2~3年程度のログ記録を保全
総務省「情報流出によるプライバシー侵害を恐れ、早期消去を主張」
Posted by funa : 05:49 AM
| Column
| Comment (0)
| Trackback (0)
December 27, 2024
GitHub Actions
ChatGPTかGeminiかに聞けば良さそう
■GitHub Actionsの動作内容はリポジトリ内に設定されている.github/workflows内のYMLにある
steps:
- name: Checkout
uses: actions/checkout@v4
@以下はバージョン、特定のコミットSHAにもできる @3df4ab11eba7bda6032a0b82a6bb43b11571feac #v4
onセクションにPushやPR作成やスケジュール実行等のトリガーや対象ブランチやパス等も書かれている
Secretsや環境変数は、Terraformでクラウドプロバイダーにアクセスする場合等で、GitHub Actionsのsecrets で認証情報が設定されていることが多い。これらはリポジトリのSettings > Secrets and variables > Actions で確認可能。
name: Deploy Terraform
on:
push:
branches:
- main #この場合、mainブランチへのpushでトリガーされる
jobs:
terraform:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v3
- name: Setup Terraform
uses: hashicorp/setup-terraform@v2
with:
terraform_version: 1.4.0
- name: Initialize Terraform
run: terraform init
- name: Apply Terraform
run: terraform apply-auto-approve #terraform planなしじゃ
Posted by funa : 09:25 PM
| Web
| Comment (0)
| Trackback (0)
December 24, 2024
He is a good egg.
ゆで卵 キン肉マン 聖なる夜 メリーXマス
茹でる前に画びょうで平ケツに穴をあける
湯に酢を入れる
7分強茹でる
余熱5分くらい(ゆで計測器で測る)
Posted by funa : 09:00 PM
| Column
| Comment (0)
| Trackback (0)
September 5, 2024
Flask
■formaction (hidden以外でのSubmit先変更方法)
buttonや inputのtype=submit/image に付与できる
ベースとなるのはformのidのformタグ<input... form="formのid">
<form id="form" method="post">
<button type="submit" formaction="app.html" name="transition" value="a" form="form">戻る</button>
<button type="submit" formaction="ok.html" name="transition" value="b" form="form">送信</button>
下記のような属性がある
formaction
formenctype
formmethod
formnovalidate
formtarget
■jinja2
///dict
my_dic['name'] = 1
return render_template('index.html', message=my_dic)
テンプレ側
{{message.name}}
///リスト
num_list = np.arange(10)
return render_template('index.html', message=num_list)
テンプレ側
{% for num in num_list %}
<div>{{ num }}</div>
{% endfor %}
///改行
{%- xxx -%} jinjaタグの前後マイナスで改行空白を除外する
+はtrim_blocks(改行詰め)、Istrip_blocks(空白詰め)を無効化する設定で俺は使わない
from jinja2 import Environment
jinja_env = Environment()
jinja_env.trim_blocks = True
jinja_env.Istrip_blocks = True
///置換
{{ "aaagh" | replace("a","oh,","2") }}
-> oh,oh,agh
{{ input['txtarea'] | replace("\n","<br />") }}
///エスケープ
safeフィルタがなければhtmlエスケープがかかる
{{ output | safe }}
あるいは
{{% autoescape False %}}{{ output }}{{% endautoescape %}}
///コメント(複数行ok)
{# note: commented-out we no longer use this
{% for user in users %}
…
#}
///生
{% raw %}
<ul>
{% for item in seq %}
<li>{{ item )}</li>
{% endfor %}
</ul>
{% endraw %}
///extend と block と include
●flask
page=page_a.model(user)
return render_template("layout.html",title=title,page=page)
●layout.html (テンプレ切替と共通ブロック、共通ブロックはテンプレに書いた方分かり易い?)
{% if page['destination']== 'confirm' %}
{% extends "template_confirm.html" %}
{% elif page['destination']== 'complete' %}
{% extends "template_complete.html" %}
{% else %}
{% extends "template_html" %}
{% endif %}
{% block body %}
{% include "header.html" %}
<p>content here.</p>
{% endblock %}
●template.html
<html>
<body>
<h1>{{ title }}</h1>
{% block body %}
{% endblock %}
#0以上の入力データの確認 (空の確認やintへのキャスト)
#{% if 'inquiry_id' in page['input'] and page['input']['inquiry_id'] is not none and page['input']['inquiry_id'][int > 0 %}
{% if page[input']['inquiry_subject'] %}
<input name="inquiry_subject" type="text" placeholder="例)a" value="{{ page['input']['inquiry_subject'] }}">
{% else %)}
<input name="inquiry subject" type="text" placeholder="例)a">
{% endif %}
{% include "footer.html" %}
</body>
</html>
●header.html
<p>date:2024-8-27</p>
●footer.html
<p>author.p</p>
●page_a.py
def model(user):
value_return = ""
input = {}
error = {}
value_return <br>under constructions taken place by user '<br>'
#入力があった、
if request.method == "POST":
transition = request form.get("transition")
#get, post, 取得するもので書き方が違う
#request.args.get("inquiry_id")
#request.form.get("inquiry_id"
#request.json.get("inquiry_id")
logging warming('#####' + user + 'transition: ' + str(transition)+'#####')
if transition == "new" or transition == "error" or transition == "confirm back":
flag_ng=0
#入力値の判定
error_txt_inquiry_subject = []
inquiry_subject = request.form.get("inquiry_subject")
ff not checkRequire(inquiry_subject):
error_txt_inquiry_subject.append("件名が空欄です”)
flag_ng=1
input[inquiry_subject] = inquiry_subject
if flag_ng == 1:
error['error_txt_inquiry_subject] = error_txt_inquiry_subject
#エラー画面を出す
destination = "error"
else:
#確認画面を出す
destination = "confirm"
#End of transition == "new" or transition == "error" or transition == "confirm back":
else:
#transition == "confirm_proceed"
#登録処理し完了画面を出す
destination = "complete"
else:
#初期画面を出す
destination = "new"
return ("value":value_return, "destination":destination, "input":input, "error":error)
■改行
プレースホルダー内での改行は
:に置き換える
<textarea placeholder="例) aaa bbb">
JINJA2のフォーム入力後の確認HTMLの改行は?
置換ではhtmlエスケープが掛かり<br>がそのまま表示されてしまいダメ
{{ input | replace("\n", "<br>") }}
htmlエスケープ(HTMLエスケープは<>&のみだった)
• 入力があればhtmlエスケープ+改行<br/>変換
• html表示はそのままhtmlエスケープ+改行<br/>変換状態で出力
• DBにそのままhtmlエスケープ+改行<br/>変換状態で出力入れる
• htmlフォーム内表示はhtmlエスケープを解除し表示
↓
入力値はそのままinput変数に保持
confirm画面でエスケープ (html.escape()+改行<br/>変換) しescape変数に保持
DB保存時にはescape変数にプラスしてダブル/シングル/バッククォート、セミコロン、バックスラッシュをエスケープし保存
DBから取り出す際はそれらをアンエスケープしescape変数に保持
Docへはinput変数で保存
画面表示時はアンエスケープ (改行<br />変換+html.unescape())
def escapeHtmlBr(text):
if text is None:
return text
elif isinstance(text, list):
list_escaped = [html.escape(item) for item in text]
list_escaped [item.replace("\n', '<br>') for item in list_escaped]
return list_escaped
else:
escaped_text = html escape(text)
return escaped_text.replace('\n', '<br>')
def unescapeHtmlBr(text):
if text is None:
return text
elif isinstance(text, list):
list_unescaped = [item.replace('<br>', '\n') for item in text]
list_unescaped = [html.unescape(item) for item in list_unescaped]
return list_unescaped
else:
text text.replace('<br>', '\n')
return html.unescape(text)
def escapeDB(text):
if text is None:
return text
elif isinstance(text, list):
list_escaped = [item.replace(';', ';') for item in text]
list_escaped = [item replace('"', '"') for item in list_escaped]
list_escaped = [item.replace("'", ''') for item in list_escaped]
list_escaped = [item.replace('\\', '\') for item in list_escaped]
list_escaped = [item.replace('`', '`') for item in list_escaped]
return list_escaped
else:
escaped_text = text.replace(';', ';')
escaped_text = escaped_text.replace('"', '"')
escaped_text = escaped_text.replace("'", ''')
escaped_text = escaped_text.replace('\\', '\')
escaped_text = escaped_text.replace('`', '`')
return escaped text
def unescapeDB(text)
if text is None
return text
elif isinstance(text, list):
list_unescaped = [item replace('`', '`') for item in text]
list_unescaped [item.replace('\','\\') for item in list_unescaped]
list_unescaped [item.replace(''', "'") for item in list_unescaped]
list_unescaped [item.replace('"', '"') for item in list_unescaped]
list_unescaped [item.replace(';', ';') for item in list_unescaped]
return list_unescaped
else:
unescaped_text = text.replace('`','`')
unescaped_text = unescaped_text.replace('\', '\\')
unescaped_text = unescaped_text.replace(''', "'")
unescaped_text unescaped_text replace('"', '"')
unescaped_text = unescaped_text.replace(';', ';')
return unescaped_text
■文字確認
def check_special_characters(a):|
#チェックする記号のセット
special_characters = ['<', '>', '"', '&']
#特定の記号が含まれているかをチェック
if any(char in a for char in special_characters):
raise ValueError(f"変数 'a' に禁止されている文字が含まれています: {a}")
try:
a = "Hello & World"
check_special_characters(a)
except ValueError as e:
print(e)
■DBのnull行の排除
bq = bigquery.Client()
sql = f"""SELECT a FROM `ds.b' WHERE c = '{pri}'"""
results=bq.query(sql)
list = list()
for row in results:
if row.a is not None:
list.append(str(row.a))
■Flask-WTF CCSRF対策でhiddenに入れる
https://qiita.com/RGS/items/c8c99970054a481ac80d
requrement.txt Flask-WTF==1.2.1
from flask_wtf import CSRFProtect
app = Flask(__name__)
app.config['SECRET_KEY'] = 'mysecretkey'
csrf = CSRFProtect(app)
<input type="hidden" name="csrf_token" value="{{ csrf_token() }}"/>
PRGパターンでGETで完了画面に行くがエラーとならない、WTFはPOSTのみ利くようだ
●完了画面でセッション変数がない場合はエラーとする
保存処理でdoc_idをセッション変数に入れ
不正で直接完了画面にいくとエラーとする
https://xxxx.com/complete?doc id=ddd
■重複登録の回避策(PRG方式+JSボタン無効)
・リダイレクト POST/Redirect/GET パターン
・連打を避けるためボタンのJS無効化
片方のみのためquerySelectorAll() を使う>ページ遷移しなくなった>下記JSを使う
@app.route('/submit', methods=['POST'])
def page():
page = model
if complete:
session['doc_id'] = page['input']['doc_id']
redirect(url_for('thank_you'))
else:
retrun template('layout.html')
@app.route('/thank_you')
def thank_you():
if 'doc_id' in session:
page['input']['doc_id"] = session['doc_id"]
session clear()
return render_template('complete_layout.html', page=page)
else:
return render_template('error.html", message="missing arg")
@app.errorhandler(404)
def page_not_found(e)
return render_template('error html', message="Page not found"), 404
error.html側
<h1>{{message }}</h1>
submit側
連打を避けるためボタンの無効化
片方のみのためquerySelectorAll() を使うとページ遷移しなくなる等がある
<script>
document.addEventListener('DOMContentLoaded', function(){
const form = document.getElementById('form');
const buttons = form.getElementsByTagName('button');
form.onsubmit= function(event) {
//クリックされたボタンを取得
const clickedButton = event.submitter;
//隠しフィールドを追加して、ボタンのname と value を送信
const hiddenField = document.createElement('input');
hiddenField type = 'hidden'
hiddenField.name = clickedButton.name;
hiddenField.value = clickedButton value;
form.appendChild(hiddenField);
// すべてのボタンを無効化して二重送信を防止
for (let i = 0; i < buttons.length; i++) {
buttons[i].disabled = true;
}
}
}
</script>
Posted by funa : 11:34 PM
| Web
| Comment (0)
| Trackback (0)
August 17, 2024
モバイルキーボードアクションカメラ
モバイルキーボード Bluetooth 3.0 Keyboard KIKIGOAL
低電圧でLED青灯、充電4hrsで60hrs使用、充電時は赤灯で完了時は消灯
Fn+C(青歯アイコン)でBluetooth灯が点滅しペアリング準備中(Bluetooth 3.0 Keyboard)
接続時に消灯、CapsLockでLED白灯
システム切換:Fn+WでWin用、Fn+QでAndオイド用、Fn+EでiOS用
AndオイドはShift+Spaceで日本語切り替え
コピペ:メール等のテキストappはカーソルがでるのでShift+←→で選択、Ctrl+c/v
ブラウザは、反転させてから後ろへはShift+→で選択できる、もっと良い方法は?
F10で英数不可問題:システムをandオイドにせず、winだとスマホの機能はFnで呼び出さない
つまり入力時はFn+WでWin用にすると良い
F6:ひらがな/F7:全角カナ/F8:半角カナ/F9:全角英数/F10:半角英数
変換問題:スペース後に早すぎる決定があると最初の候補が選ばれる?
変換時にSpaceで切替てEnter押しても変、タッチパネル使う?
↓
安価タブレットの方が読書メモには使いやすい<画面デカいし入力予測の選択がやり易い
2024/11に1万円だが、モッサリし過ぎなのでもうちょい良いのが欲しいが
タブレット BMAX I9Plus
Android14 1.8GHz 8コアCPU
ディスプレイ 10.1inches 1280x800 FHD1080p
メモリ4G+8G 64GBストレージ
bluetooth5, 802 11 acbgn, microsd
==========
アクションカメラ XTU S6 JP-S6
Ambarella H22 CPU Cortex-A53/1.2GHz 4コア
SONY IMX386、1/2.8''CMOSセンサー
170度広角、6軸ジャイロ手ぶれ補正4.0
H.264/265コーデック
Mirco SDカード クラス10UHS-3以上 64-256GB
1350mAhバッテリー
【SuperView超広角機能&縦向き撮影機能】スーパービュー機能で臨場感のある広角映像を撮影できます。4:3 のアスペクト比で撮影した映像が 16:9 のアスペクト比にダイナミックに引き伸ばされます。カメラセンサーの 4:3 比率で得られる上下幅を利用するため、カメラを水平線に向けている場合でも撮影範囲に入る空や地面が広くなる(4K/30fps,1080P/60fps)
【WiFi/リモコン/音声制御可】Wi-Fiが内蔵、スマホに専用アプリをインストールすれば、ライブビューモードで画像を確認するだけではなく、撮影した映像を動画共有サイトやSNSに直接に投稿することができます。10Mの遠隔操作ができるリモコンコントロール付。音声で録画はじめ、終了と制御出来ます
【Gyroflowアプリ対応&Type-Cポート対応&HDMI出力】手ブレを補正するジャイロデータモードが搭載されているため、手ブレ補正アプリ「Gyroflow」に対応。手ぶれ補正のレベルや画像効果を自由に編集することができます。Type-Cで高速充電可能です。さらに、MicroHDMIも搭載されているため、映像をテレビやプロジェクターなどの大画面で再生できます。USBType-Cで充電や外部マイク可。
風切り音?ケースの振動打音?が酷い、外部マイクが適さないため、吸音系の処理をしたい
当日テスト撮影してAWBとISOと明るさを決めるのが良さそう(AWB/ISOは自動で明るさだけでもいいが)
↑
■中央サイズ表示:録画設定
4K30、4K30(SuperView)、2.7K30、1440P60、1440P30、1080P120、1080P60、1080P60(SuperView)、1080P30、1080P30(SuperView)、720P240-30>720P60(か1080P60)
セグメント:自動、1/3/5分>5分
録音on/off>ON
事前記録9-20s/off>OFF
測光モード:中央重点/評価/スポット>評価
露出:+3to-3>-0.5
LDC(Lens Distortion Correction:歪曲の曲面補正)>ON
手振れ補正:オフ/普通/ジャイロデータ>スーパー補正
AWB(オートホワイトバランス):自動/晴れ/曇り/白熱灯/蛍光灯>自動(晴れ)
ISO:100-1600>自動(100から出来るだけ低め)
シーンモード:自動/人物/風景/露補正>風景
シャープネス:高/ミディアム/低>高
コントラスト:1-6>3
明るさ:1-6>2
彩度:1-6>5
画像の品質:標準/高>高
フィルタ:オリジナル/モノクロ/ビビッド/セピア/ワーム/クール>オリジナル
エンコード:H264/H265(見れんかった)>H264(mp4 低圧縮だがwinデフォで使える)
■コグアイコン:設定
自動スリープ:オフ10-60s>30
自動オフ1-5m>3m
wifi 周波数50/60Hz>50
WDR(ワイドダイナミックレンジ)逆光や白飛びや黒つぶれハードウェア処理、文字が見難くなる>ON
マイク音量:ノイズ小/デフォ/高>ノイズ小
前画面の視角(FOV:field of view)>デフォ
Flipホーム画面を90/180/270°回転>0
スタンプ(時間を記録)>ON
操作音(ボタンの押下音、シャッター音)
グリッドガイド(参照グリッド線のon/off)
日付
音声制御(ビデオスタート、ビデオ停止、スクリーンオン、スクリーンオフ、wifi on、wifi off、写真を撮る)>ON
SDフォーマット
初期設定に戻す
■絵アイコン:再生
再生一覧
■ビデオアイコン:撮影モード
撮影モード(録画、タイムラプス:静止画を定期的に撮影して繋げる、スローモーション、夜景モード、ドラレコ、録画+撮影)
※モードを選ぶと使えるサイズとFPSが決まる、手振れ補正使えないサイズもある、スローは音無し>(通常)録画
■操作:下にスワイプ
wifi on>off
画面回転
リモコン>on
音声制御>on
画面ロック
電源off
■物理ボタン
電源/撮影モードボタン
撮影開始/停止/3s長押しで前後モニター切り替えボタン
※電源と撮影開始ボタンの間に内蔵マイク穴
▲ボタン(設定メニュー、長押しwifiスイッチ)
▼ボタン(録画設定)
■リモコン
赤カメラアイコン:写真
グレービデオアイコン:動画
■撮影
カメラを装着、電源を真ん中ボタン長押しで入れ、リモコンのグレーで撮影開始、リモコンのグレーで撮影停止
ハンドルバーにセットだけで逆撮りだが撮影可
ブレが修正されており、画像も綺麗で問題ない
逆画面になっているがプレイヤーでもエディターでも回転できる
タイムラインで選択してプレビューで⊕を回転ドラッグ
自撮り棒は振動で角度が駄目になるのでフェンダー固定が必要そう
※電源が入らず2025/1に交換した v1.06>v1.08のマニュアルになった、3年保証で補償も悪くない
過充電か過放電?数回の使用で何もしてないが気を付けられるのはそこだけ
Posted by funa : 07:20 PM
| Gadget
| Comment (0)
| Trackback (0)