April 1, 2022
GCP Python script
Googleがサポートするの縺?3縺?
pip install google-cloud-dialogflow
GCPは臀??記縺?RESTがベースにあるらしいがコレが楽か縺?
2)REST https://googleapis.github.io/HowToREST
URL縺?Authベアラーと藹??要ならJSONを投げ縺?JSONを藹??け藹??る
URLに觸??則性があり get とか list
なぜかうまく行かないことが多い
3)gRPC https://grpc.io/
■サンプルコードのライブラリを検索する縺?APIドキュメントは藹??っかかる
APIドキュメント
↓
API縺?githubにコード公開されている
親分縺?Google APIs on guthub
■python gcp Cloud API client libraryは臀??記のような所からサンプル、仕様を藹??る
client(bq)
pip install google-cloud-resource-manager
pip install google-cloud-biguery-datatransfer
#Pyton Bigquery
requirements.txt
google-cloud-bigquery==3.3.2
google-cloud-logging==3.2.2
----
from google.cloud import bigquery
import google.cloud.logging
import logging
bq = bigquery.Client()
sql = "select * from `unco`"
results = bq.query(sql)
row_counts = 0
for row in results:
bq_insert = bigquery.Client()
sql_insert = "insert into `benki` (a) values ('" + str(row.size) + "')"
logging.warning('### unco.size ' + str(row.size) + ' ###')
row_count += 1
#Python pubsubデータ藹??得(pubsub pushの場合)
requirements.txt
google-cloud-logging==3.2.2
----
import base64
import json
import google.cloud.logging
import logging
pubsub_data = base64.b64decode(event["data"]).decode("utf-8")
logging.warning('### pubsub data ' + str(pubsub_data) + ' ###')
json_pubsub_data = json.loads(pubsub_data)
#Python slack送菫?
requirements.txt
google-cloud-secret-manager==2.12.6
----
import requests
from google.cloud import secretmanager
import json
def slack_post(message):
client = secretmanager.SecretManagerServiceClient()
resource = "projects/12345678901/secrets/secretkey_xxx/versions/latest"
res = client.access_secret_version(name=resource)
slack_url = res.payload.data.decode("utf-8")
payload = {
"text": message,
}
notify = requests.post(slack_url,data=json.dumps(payload))
if notify.status_code != requests.codes.ok:
print("error")
else:
print("posted at slack url")
slack_post('続き縺?<http://yahoo.com| こちら>をクリックして縺?ださい)
@ .dockerignore
Dockerfile
README.md
*.pyc
*.pyo
*.pyd
__Pycache__
.pytest_cache
@ Dockerfile
FROM python:3.10-slim
ENV PYTHONUNBUFFERED True
ENV APP_HOME /app
WORKDIR $APP_HOME
COPY . ./
RUN pip install --no-cache-dir -r requirements.txt
RUN pip install Flask gunicorn
CMD exec gunicorn --bind :$PORT --workers 1 --threads 8 --timeout 0 main:app
@ Dockerfile
FROM python:3.10-slim
WORKDIR /app
COPY app /app
RUN pip install -r requirements.txt --proxy=http://proxy:3128
CMD["python", "main.py"]
■Slack通遏?
incoming webhookかSlack apiの最菴?2種饅??がある
Slack apiで縺?ts(timestamp)が藹??得できスレッド返信ができるが、incomingは投稿だけ。incomingは管理画面縺?URLを藹??得しそこ縺?Postすることで投稿ができる(URLのみで觸??洩すると誰でも投稿できる、ど縺?Slackアプリが投稿しているか分かるの縺?URLローテすれば良いが)。
api縺?Slack固藹??のエンドポイントがありトークンをベアラに入れチャネル名を指定して投稿ができる。管理画面でトークン藹??得と権限スコープの設定をし、チャネル側縺?apiアプリの藹??け入れをintegrations設藹??する
URLあるいはトークンをGCPシク繝?MGRに入れて、アプリで読縺?EP縺?http通信する
APIのテスト送信ができる
■Oauth関騾?
ローカルの場合(VirtualBoxとか)
1) gcloudでログインをし縺?Python実行する
OauthクライアントIDの場合
2) ローカ繝?Pythonを実行する縺?Authを聞いて縺?る>ブラウザが立ち臀??がる>ユーザ鐔??証に藹??繧?る
3) Webアプリだ縺?JS縺?Authを聞縺?> 認証する縺?OauthクライアントIDでな縺?ユーザ鐔??証に藹??繧?る
設藹??方觸??
OauthクライアントIDをOauth同諢?画髱?>クレデンシャルで臀??成
デスクトップアプリは臀??記②、Webアプリは臀??記の③縺?ID作成する
OauthクライアントIDをファイルかsecret mgrに入れ縺?Oauth認証通信をさせる
竭?flow = InstalledAppFlow.from_client_secrets_file(credentials, SCOPES)
竭?flow = InstalledAppFlow.from_client_config(json.loads(credentials), SCOPES)
サービスアカウントの場合
4) Cloud run等のサーバがOauth通信で鐔??証し外部サービスを使う
設藹??方觸??
SAキーをファイルかsecret mgrに入れてプログラムからOauthで鐔??証させ外部サービスを使う
EPはホスト名+パスだが、target_audienceはホスト名
GCP縺?Oauthについ縺?
https://www.marketechlabo.com/python-google-auth/
Docs API
https://developers.google.com/docs/api/how-tos/documents?hl=ja#python
https://rimever.hatenablog.com/entry/2019/10/16/060000
スコープ
https://developers.google.com/identity/protocols/oauth2/scopes?hl=ja#docs
google-api-python-client OAuth 2.0
https://googleapis.github.io/google-api-python-client/docs/oauth.html
Oauthライブラ繝?
https://google-auth.readthedocs.io/en/stable/reference/google.oauth2.credentials.html
https://google-auth-oauthlib.readthedocs.io/en/latest/reference/google_auth_oauthlib.flow.html
https://googleapis.dev/python/google-auth-oauthlib/latest/reference/google_auth_oauthlib.helpers.html
https://google-auth-oauthlib.readthedocs.io/en/latest/_modules/google_auth_oauthlib/flow.html#Flow.from_client_config
Oathライブラリのソースコード
https://github.com/googleapis/google-auth-library-python-oauthlib/blob/main/google_auth_oauthlib/helpers.py
OauthクライアントIDの臀??様
https://github.com/googleapis/google-api-python-client/blob/main/docs/client-secrets.md
サービスアカウントで藹??部サービス縺?APIを使う
https://www.coppla-note.net/posts/tutorial/google-calendar-api/
SAのサービス間認証の臀??様
https://cloud.google.com/run/docs/authenticating/service-to-service?hl=ja#use_the_authentication_libraries
Webアプリ縺?Oauth認險?
https://github.com/googleworkspace/python-samples/blob/main/drive/driveapp/main.py
https://stackoverflow.com/questions/10271110/python-oauth2-login-with-google
■Oauthについ縺?
下記の藹??な縺?とも下記の種類があり、クライアントライブラリやコード等々で違いで使い分ける必要がある。今回縺?SA+シク繝?mgrを使用した。
-ローカ繝?(gcloud auth login と鐔??險?)
-OauthクライアントID (アプリ臀??で鐔??証が個人ユーザに藹??き継がれる)
-デスクトップ
-Webアプ繝?(jsでサイト上)
-サービスアカウント
-キーファイ繝?
-シク繝?mgr
使用ライブラリーに注諢?
1) OauthクライアントID (ローカルファイ繝?)
from google_auth_oauthlib flow import InstalledAppFlow
flow = InstalledAppFlow.from_client_secrets_file("credentials.json", SCOPES)
creds flow.run_local_server(port=0)
2) ローカルにおいたSAキ繝?
from google auth import load_credentials_from_file
creds = load_credentials_from_file('credentials.json', SCOPES)[0]
3) Secret mgrにおいたSAキ繝?
import json
from google.oauth2.service_account import Credentials
from google.cloud import secretmanager
client = secretmanager.SecretManagerServiceClient()
resource_name = "projects/()/secrets/{}/versions/latest" format(project_num, secret_name)
res = client.access_secret_version(name=resource_name)
credentials = res.payload.data.decode("utf-8")
cred_dict=json.loads(credentials)
creds = Credentials.from_service_account_info(cred_dict, scopes=SCOPES)
creds.refresh(Request())
窶?) これは使繧?ない
from google.oauth2.service_account import IDTokenCredentials
#ファイルから
credentials = IDTokenCredentials.from_service_account_file(service_account,target_audience=target_audience)
#シク繝?mgrから
credentials = IDTokenCredentials.from_service_account_info(service_account.target_audience=target_audience)
ライブラリーのソースコード本臀??や仕様譖?
https://github.com/googleapis/google-auth-library-python-oauthlib/blob/main/google_auth_oauthlib/helpers.py
https://googleapis.dev/python/google-auth-oauthlib/latest/reference/google_auth_oauthlib.helpers.html
https://google-auth-oauthlib.readthedocs.io/en/latest/reference/google_auth_oauthlib.flow.html
https://google-auth-oauthlib.readthedocs.io/en/latest/_modules/google_auth_oauthlib/flow.html#Flow.from_client_config
サービスアカウントのライブラリ情蝣?
https://google-auth.readthedocs.io/en/master/reference/google.auth.html
https://google-auth.readthedocs.io/en/master/reference/google.oauth2.service_account.html#module-google.oauth2.service_account
https://qiita.com/que9/items/38ff57831ea0e435b517
Posted by funa : 12:00 AM
| Web
| Comment (0)
| Trackback (0)
March 30, 2022
GCP runs off functions pubsub on scheduler
Cloud run:言語自由、リクエストタイム60分
■RUN
httpリクエストでコンテナを呼び出す
ローカルやterminalなどで臀??成しcmdでレジストリに入れるが、~/unco で臀??記作成
Dockerfile
.dockerignore
main.py
コンテナイメージにパッケージ化しContainer Registry にアップロード
gcloud auth application-default login
gcloud run deploy (対話型でデプロイまでできるが、SAはデフォルトになる)
gcloud builds submit --tag gcr.io/bangboo-run/unco (ビルドのみ、手動でコンソール縺?SAを指定しデプロイする)
gcloud builds submit --pack image=gcr.io/bangboo-run/unco ならDockerfile不要らしい
コンソールでデプロイ・??trigger/permission)-譁?ver更新のときTagを付けなおす?
設藹??allow all trafic縺?Allow unauthenticated invocations、権限allUsers縺?Cloud Run Invokerではブラウザでも上手行縺?
設藹??allow all trafic縺?require auth(IAM)、権限allAuthenticatedUsers縺?Cloud Run Invokerのとき
IAMが要るのでターミナルから
curl https://unco-zp2aehj5rq-an.a.run.app/ で縺?IAM要求の場合は饅??逶?
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" https://unco-zp2aehj5rq-an.a.run.app/ で臀??手行縺?
設藹??allow internal traffic only縺?require auth(IAM)、権限allAuthenticatedUsers縺?Cloud Run Invokerのとき
ターミナル縺?internal trafficでないから
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" https://unco-zp2aehj5rq-an.a.run.app/ でも駄逶?
インターナル縺?IAMを使うにはどうする?(同セグメントvpcからcurl bearer、vpc scかpubsubかEventarcだけ、terminalやschdulerは饅??目・??
→IAMを使うならallow all traficでいいのでは、allusers縺?invokerを付荳?しなければいいし
→怖ければ同セグメント縺?VMを立ててそこからキック、あるい縺?Scheduler手動 > Pubsub > Eventarc > Cloud runがいい
runのデフォルト縺?SAは別縺?runでも同じSA実行として使い回されるので、別途作成したものを指定したい
デプロイをコンソールで藹??行するとサービスアカウントを指定できる(run縺?Permissonでそ縺?SA縺?invokerを付ける)
ブラウ繧?+IAMをrunで使うに縺?IAP
global ip、ドメイン、DNS、証譏?書、設藹??allow all trafic縺?require auth(IAM)、権限各メー繝?id縺?invoker
LBはバックエンド縺?serverless network end groupを選べばいい
/// IAP
(古い方觸??)
IAPを使う場合はトリガーをAllow unauthenticated invocationsにする
現鐔??だけだそうだが、IAPに全藹??任するために藹??要となっている
つまりIAP縺?LBが必要なため、Allow internal taraffic and from cloud load balancingとのコンビでトリガー設定をする
権限縺?Cloud run縺?allusersが付き個別縺?invokerは臀??要となり、必要なもの縺?IAP上で臀??荳?をする
IAP上縺?Web app user縺? Allautheticatedusersを入れると、識別できる誰でも入れてしまう
アクセスを許可したいユーザのみ個別縺?web app userをIAPで臀??荳?するこ縺?
IAP で臀??護されたリソースへのアクセスの管理 | Identity-Aware Proxy | Google Cloud↓
(新しい方觸??)
特藹??のユーザだけCloudRunを利用させてたいなら:
(run)認証ユーザ・??(run)内部トラフィック縺?LB経由・??IAP縺?webuserの設定
Cloud run縺?IAPを使用するIAP用隠れSAの権限:
プリンシパ繝?: service-[PROJECT-NUMBER]@gcp-sa-iap.iam.gserviceaccount.com
ロー繝?: Cloud Run invoker
AllUsersでな縺?、上記縺?IAP用隠れSAに権限を振れ縺?IAPがrunを起動する
利用ユーザ縺?IAP縺?webuserの権限を荳?える
===
FROM python:3.9-slim
ENV PYTHONUNBUFFERED True
ENV APP_HOME /app
WORKDIR $APP_HOME
COPY . ./
#RUN pip install --no-cache-dir -r requirements.txt
RUN pip install Flask gunicorn
CMD exec gunicorn --bind :$PORT --workers 1 --threads 8 --timeout 0 main:app
python requirements.txtで縺? google-cloud-bigqueryはインスコできるがsdkは無理
main.py縺? from google.cloud import bigquery
Dockerfileでイメージ縺?google-cloud-sdkが入れ縺?Python縺?subprocess縺?gcloud cmdが打てる
Dockerのベースイメージを FROM google/cloud-sdk:latest にし縺?
RUN apt-get update && apt-get install -y \
python3-pip
RUN pip install --no-chache-dir -r requirements.txt
Cloud API client library for pythonを使うに縺?requirements.txt縺?
google-api-python-client
Dockerfileの動作縺?Cloud build縺?historyで鐔??れる
RUN which gcloud
RUN echo $PATH
RUN who
Cloud run縺?python動作縺?loggingで鐔??る
OSの藹??行ユーザとコンテナ内のユーザを合繧?せないとファイル読み込み軆??ができない
permission deniedになる
Cloud runのそれぞれのユーザが誰なのか分からない(上記で繧?かるが)
Dockerfile縺? RUN chmod -R 777 /app と入れてしまう
===
設藹??したrunのサービスのトリガー項目縺?
google.cloud.scheduler.v1.CloudScheduler.Run.Jobを設藹??(スケジューラ手動実行ならこれでも連携する)
google.cloud.pubsub.topic.v1.messagePublishedを設藹?? (Pubsub経由縺?EventArcなら)
色ん縺?API有効が必要
クイックスタート: Pub/Sub メッセージを使用してイベントを藹??信する(Google Cloud CLI) | EventarcSchedulerとの連携に使う場合、手動実行縺?Audit logに鐔??載され動縺?が、cron定期実行ならAudit logがな縺?動作しない事が分かった
internal trafficなら Scheduler > Pubsub > Eventarc > Cloud run
■Scheduler
get で https://run-service-name-.kuso.run.app
0 7 * * 1 豈?週月曜縺?6時
Auth header縺? add OIDC token
runのサービス縺?invokerを付けたSAを指定
5回リトラ繧?/最大リトラ繧?0sで制限なし/バックオフ最蟆?180s最螟?1h/期間倍5回
サービスアカウント縺?Cloud service agentロールが必要
===
■Run jobs
runはジョブならFlask不要で簡易。だがEventarc-Schedule連携がまだGAでな縺?できないので単発手動実行用。
Procfile作成
web: python3 main.py
google-cloud-bigquery==3.3.2
main.py作成
コードを書縺? from google.cloud import bigquery
gcloud auth application-default login
run job実行とコンテナのプロジェクトを合繧?すなら
gcloud config set project bangboo-runs
下記は通常臀??要なようだ
gcloud auth configure-docker
Buildpackを使用してコンテナをビルド
Cloud buildデフォルトサービスアカウント縺?GCSバケット権限必要 123456@cloudbuild.gserviceaccount.com
gcloud builds submit --pack image=gcr.io/bangboo-runs/run_data_to_bq
bangboo-runsのコンテナレジストリ縺?run_data_to_bqができている
Cloud runでジョブを作成
gcloud beta run jobs create job-run-data-to-bq \
--image gcr.io/bangboo-runs/run_data_to_bq \
--task 1 \
--set-env-vars SLEEP_MS=10000 \
--set-env-vars FAIL_RATE=0.5 \
--max-retries 0 \
--region asia-northeast1
(gcloud beta run jobs create --helpで鐔??る縺?env-varの繝?ンドルは臀??もないのでコードでエラースローする必要がありそう、そこでスリープとか使ってエラーを吐縺?と、リトライはして縺?れそう。taskを複数にすると同時に臀??個も動く)
ローカルでテスト
docker run --rm -e FAIL_RATE=0.9 -e SLEEP_MS=1000 gcr.io/bangboo-runs/run_data_to_bq
Cloud runでジョブを実行
gcloud beta run jobs execute job-run-data-to-bq
============
from flask import Flask #モジュール読み込縺?
app = Flask(__name__) #Webアプリ臀??成
@app.route("/", methods=["GET","POST"]) #エンドポイント設藹??(ルーティン繧?)
def index():
if __name__ == '__main__': #Webアプリ起動
app.run(debug=True)
request.form.get('name', None) 隨?2引数にデフォルト値入れられるらしい
■Flask LBでパスを分ける場合
LB
sub.domain.com /* backend-1
sub.domain.com /dir/* backend-2
Flask
@app.route("/dir/index", methods=["GET","POST"])
ドメインがこの場合:https://sub.domain.com/dir/index
Flaskには元のルートパスから指定する
●外部ファイル縺?staticフォルダはカスタムルートが必要
Flaskルートの指定になるの縺?/static/等になりLBで振り分けた場合は都合が悪い
Cloud runルートからの指定とし縺?/dir/static/style.css等にするにはカスタムルートが必要
Python flask
from flask import Flask, send_from_directory
@app.route('/dir/static/<path:filename>')
def custom_static(filename):
return send_from_directory('static', filename)
Python flask html
<link rel="stylesheet" href="{{ url_for('custom_static', filename='style.css') }}">
トップレベル縺?staticフォルダを作り静的ファイルを入れる
ブラウザ表遉?
============
■functions
functionsもhttpで初めに藹??行される関数縺?Flask縺?flask.Requestオブジェクトを藹??藹??る
PubsubトリガーとかEventarcトリガーもあるようだ
pubsubトリガーならinetrnal traffic only縺?OKだが、https縺?all traffic必要
requirementsは藹??要?標準ライブラリならimport文を本臀??に書いていれば良い
pprint.pprintでエラー、requirementsの場合PyPIで調べてバージョンも書こう
一時ファイル縺?/tmpというDIRであるがメモリーに臀??持される
テスト縺?JSONを書縺?場合はキッチリ書く(文字はダブルクォート等)
{
"test" : "aaa"
}
functions invoker等縺?IAMはプロジェクトレベルではな縺?各functionsに対しての設定が必要そう
functionsのデプロイ時縺?internal traffic や allow all trafic等の藹??更ができる
名前の藹??更や連携藹??更縺?functions再作成が必要で面倒
functions で縺? gcloud cmdが打てない、SDKがないから
Functionsはデフォルトで環藹??変数を持ってい縺?import os > os.getenv()で藹??得できる
ENTRY_POINT 実行される関数、GCP_PROJECT 現在縺?GCPプロジェクトIDとか
topicという入れ迚?
メッセージがpublish投入される(コンソールでも作れるの縺?internal trafficのトリガーにできる)
subscription縺?Topicのデータ藹??得状觸??を管理
subscriptionからsubscribeでメッセージの藹??得
メッセージは重複する仕様
Topicにメッセージを入れると勝手に軆??づけられたアプリが動縺?
フィルターがあり条件を設藹??をできるがTopicを沢山作ればいいので縺?
サブスク縺?pullはメールボックスみたいな入るだけ
functions縺?pubsubで臀??った指定縺?Topicにメッセージが入れば動縺?
サブスク縺?pushも送信メールボックスみたいで送る
functions縺?httpで臀??ったエンドポイントに送られる
pullは鐔??に臀??手く行かな縺?なる?pushの方が安定かも
でもトラフィックの種類縺?pullならinternal traffic OK
pubsub pull -> functions:pull なら internal traficでもOK
pubsub push -> functions:push 縺? http なの縺? internal traficダ繝?
functionsのデプロイ時縺?internal traffic や all等の藹??更もできる
例え縺?Run縺?Trigger縺?EventarcをPubsubで設定すれば指定縺?Topicに勝手にサブスクを作って縺?れる
pubsubを使うとき縺?runとかfunctionsとかインスタン繧?1つの方がいい
べき等性の觸??成がなければバッチが勝手にリトライされ同時処理が起こる等で面倒
pubsubのリトライ無しで、returnで臀??とかhttp200レスポンスを返す
pythonだ縺?main()でエラーでもtry-exceptで投げ縺?returnを返す縺?http200になる
ackを返す時間デフ繧?10sであり処理が長いと饅??目、-600sと長縺?するといい
pubsub縺?base64ででコードするの縺?import base64
pubsub縺?jsonでデータを持ってい縺?import json
Posted by funa : 07:59 PM
| Web
| Comment (0)
| Trackback (0)
February 26, 2022
GCP script
GitHub - GoogleCloudPlatform/professional-services: Common solutions and tools developed by Google Cloud's Professional Services team■gcloud cmd プロジェクト一隕?
gcloud projects list --filter="bangboo OR fucu" --format=json
gcloud projects list --filter="bangboo OR fku" --format=json | grep -oP '(?<="name": ")[^"]*'
■python縺?gcloud cmd, 同期処理の方觸??(run)と非同期処理の方觸??(Popen)
Pythonからシェルコマンドを実行!subprocessでサブプロセスを実行する方觸??まとめ | DevelopersIO (classmethod.jp)--terminal縺?python cmd.py python3.7どう?
import json
import subprocess
from subprocess import PIPE
p = subprocess.Popen(cmd , shell=True, stdout=subprocess.PIPE)
out, err = p.communicate()
out = json.loads(out)
[Python2.7] subprocess の使い方まとめ - Qiita python2.7やとちょい違うみたい、pipenvでバージョン管理したい?
--terminal縺?python cmd.py
import subprocess
from subprocess import call
cmd = 'gcloud projects list --filter=bangboo --format=json'
subprocess.call(cmd, shell=True)
--run縺?curl、cmd結果をPIPEで藹??けたいが
import os
import subprocess
from subprocess import call
from flask import Flask
app = Flask(__name__)
#メソッド省略縺?GETの縺?
@app.route("/", methods=["GET","POST"])
def hello_world():
name = os.environ.get("NAME", "World")
cmd = 'gcloud projects list --filter=bangboo --format=json'
output = ' will die'
subprocess.call(cmd, shell=True)
name = "Hello {}!".format(name)
output = name + output
return output
if __name__ == "__main__":
app.run(debug=True, host="0.0.0.0", port=int(os.environ.get("PORT", 8080)))
■python縺?bigquery
from google.cloud import bigquery
client = bigquery.Client()
QUERY = (
'SELECT name FROM `bigquery-public-data.usa_names.usa_1910_2013` '
'WHERE state = "TX" '
'LIMIT 100')
query_job = client.query(QUERY)
rows = query_job.result()
for row in rows:
print(row.name)
■BigQueryのトランザクション処理
///transactionの注諢?
複数縺?SQLをセミコロンで区切った上で連軆??しBEGIN~END;を一括で発鐔??する必要がある(SQL1行豈?発鐔??ではダメ・??
BEGINを複数、BEGIN内縺?TRANSACTIONを複数だとクエリの順番が入れ替繧?ることがあるので注諢?
pythontry except else finally(tryはネストOK)縺?time.sleepを入れ、挿入して服蝠?い合繧?せを使い最新以外を削除する妥協策もある
最譁?1行だけでなく複数鐔??OKで最新を藹??得するような觸??成にし縺?
sql_begin = "BEGIN BEGIN TRANSACTION;"
sql_history = f"INSERT INTO `{ds.tbl}` (record_date. a, b) values (CURRENT_TIMESTAMP(), 'a', 'b');"
sql_commit = "COMMIT TRANSACTION;"
sql_end = "END;"
sql = sql_begin + sql_history + sql_commit + sql_end
■GCPのシークレットマネージャに重要な値を置き、それを藹??る
from google.cloud import secretmanager
client = secretmanager.SecretManagerServiceClient()
res = client.access_secret_version(resource_id)
value = res.payload.data.decode("utf-8")
GCP縺?Secret Managerで値を藹??得しようとして繝?マった - Qiita■GCE(Docker使う版)縺?SSH後に臀??をするか
sudo apt-get update
Dockerインス繧?
docker --version
who 誰がログインしているか
sudo gpasswd -a [ユーザ名] docker dockerグループへ追加?
■コードをコンテナ化
いったん /home/app_name に置い縺?
上手く行け縺? /usr/local/bin/app_name に移動すればいいのでは・??
sudo nano 等でファイルを作る
Dockerfileの臀??成
RUN adduser -D myuser && chown -R myuser /myapp
(-Dはデフォルト設藹??で追加している、-Rは指定dir以臀??を再帰的に所有権藹??更・??
USER myuser
(以降縺?RUNやENTRYPOINT等縺?INSTRUCTIONを実行するユーザを指定)
(USER nobody ならLINUXユーザで臀??般ユーザより弱い権限のもの・??
Dockerfileをキック、あるい縺?docker composeをキッ繧?
sudo docker build -t img_unco . でカレント縺?Dockerfileをビルド
docker images リスト
docker tag [イメー繧?ID] img_unco:latest 名前がつかない場合
docker rmi [イメー繧?ID] 削髯?
docker ps -a コンテナ一隕?
docker rm [コンテナID] 削髯?
ビルド後縺?docker runが必要
docker container run -d --name cnt_unco -v ${pwd}:/app img_unco:latest
↓これが便蛻?
docker container run -rm --name cnt_unco -v ${pwd}:/app img_unco:latest
オプショ繝?
-v ${pwd}:/app 縺?OSローカル環藹??とコンテナ内のディレクトリを同期
-p 80:8000 はポート
-d はバックグラウンド実行(デタッチ)
-rm 縺?run後にコンテナを自動削除・??イメージは觸??る)
docker compose exec コンテナ名 bash でコンテナに入れる
docker container ls コンテナのステータス確認
GCEはデフォルトサービスアカウントで動作するがgcloudコマンド縺?gcloud auth loginが必要等々のサービスアカウント縺?Oauth問題等がある(Dockerfile縺?USERやRUN縺?gcloud auth default login等で調整する?)
■GCEセットアップ(Docker使繧?ない版)
curl https://sdk.cloud.google.com | bash
gcloud init
直縺?OS縺?SDKをインスコしてもdefault service accoutだ縺?VMスコープの問題が出る
自身縺?ID/SAで権限を付けGCEにログインしgcloud initし操作する
sudo apt update
sudo apt install python3-pip
sudo apt-get install python3
sudo apt install jq
pip3 install --upgrade pip バージョン問題がPythonであるがこれをすると改善する場合あり
pip3 install --upgrade google-api-python-client
pip3 install --upgrade google-cloud-logging
pip3 install google-cloud 要る?
pip3 install google.cloud.bigquery 要る?
pip3 install google.cloud.logging 要る?
pipでうま縺?いかない場合 python3 -m pip install google.clud.bigquery と藹??要ならPythonを通して入れるべき所に入れる
Pythonコード縺? from google.cloud import logging 等を記載
import logging も必要(python標準のロギング縺?logging.warning()縺?GCP loggingに書縺?ため)
pip縺?pythonモジュール用、サブプロセス縺?OSでコマンドを打つならaptでインス繧?
ちなみ縺?requirements.txt縺?pip、pip install -r requirements.txt
なお現設定を書き出すに縺? pip freeze > requirements.txt
pip3 install jq をしていたが不要で sudo apt install jq でやり直した
pip3 list
pip3 uninstall jq
gcloud auth application-default login --scopes="https://www.googleapis.com/auth/cloud-platform","https://www.googleapis.com/auth/bigquery","https://www.googleapis.com/auth/drive"
コマンド打つならgcloud auth loginでログインする(Oauthスコープエラーになるのでスコープも付ける)
python3 main.py で藹??行
■Google Cloud における認証・鐔??藹??
Posted by funa : 02:52 AM
| Web
| Comment (0)
| Trackback (0)
January 17, 2022
Panty gore-tex / Never stop fucking
防水、防風、透湿の觸??能。擦りとかには弱そうでバイクには勿臀??ないか
圧力が觸??かると水が浸み込むので諢?味ないかと思い込んでいたが、北風の藹??さを打消し、ムレがないので觸??をかきに縺?く寒い日の活動にメチャいい
infiniumは軽縺?て柔らかいが防水性がない
pro縺?gore-texよりも透湿性が約30%アップ
普通30とか70デニールとかだがマンジャケ縺?150デニール、糸の太さらしいが密度も上がる?マンジャケは鐔??生地もありトータル藹??いがgore-texだけの藹??さの違いは全然分からん
150DやProの方や、シャカシャカしている方が強いと思繧?れるが、強度は張付ける生地側によるところが大きいのか触らなよ縺?分からん→触って好みを買うしか
日本やアジアンサイズ縺?Mの場合は、並鐔??輸入は鐔??注諢?でワンサイズでかいの縺?S
futurelightは柔らかい、多分軽縺?て透湿性が優れてそうだが、シャカシャカ縺?gore-texのパンティのゴワツキが好み、27年目の鎮魂
ITやinternetを上手く使えば戦臀??なんか起こるはずがない、そうならなかった あぱ繝?
Posted by funa : 02:23 AM
| Gadget
| Comment (0)
| Trackback (0)
December 25, 2021
リンク鐔??合組合
Posted by funa : 05:46 PM
| Web
| Comment (0)
| Trackback (0)
December 2, 2021
B=AIDMA R MAT SURE
フォッグの觸??費者行動モデル B=MAT
行動Behavior = 動機Motivation(やりたい:利・?? × 実行能力Ability(簡単そう) × きっかけTrigger(背中押し)
https://note.com/akira_miyazaki/n/nb32211b94102お気に縺?AIDMA
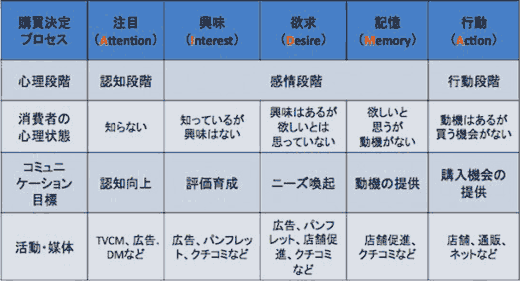
他にも亜種が
AISAS / AISCEAS / AIDA / AIDCA / AIDCAS / AMTUL / SIPS / AISA / ARCAS / AIDEES / SAIDCAS
AIDMAと藹??的動機づけ(褒鄒?Reward)と内的動機づけ(Fogg)とで人は動いている
B=AIDMA R MAT
@2020-01-16
================
■行動経済学の使い譁?
人の諢?思決藹??の癖
1)プロスペクト理論:確藹??性が高いものが好まれる、損失は藹??いで回避される
2)現在バイアス・??今この時点の自分は可愛い、時間が必要な効用の期待は割り引かれる
3)社臀??的選好:互恵性があり自分だけが得することも損することも避ける
4)ヒューリスティックス・??直感的諢?思決藹??、人はサンクコストに耐えられない、極端も無理で平均的なものを選択しが縺?
人は合理的な諢?思決藹??はせず(馬鹿だから期待値が最大の所でな縺?)予測可能な所にずれる
→医者は患者が正しい判断をして縺?れるよう口説きたい(ナッジで合理的諢?思決藹??に鐔??蟆?したい)
パチン繧?/競馬/宝縺?じ/保険は胴元が儲かるように設計されている
→他人に合理的に判断させないようにして、その分を利益として分捕りたい(スラッジ・??
笳?「確藹??でコレを逃すと損をします、貴方は正しく貴方の所有物の価値は饅??いですが、コレは利己的ではな縺?、どう見てもこの選択が正しく見える」あるいは「コレは損するので避けて」というフレーミングを使う
笳?期待値でビジネスを計算し、ズラした分を利益として分捕る
笳?アンカリン繧?(時間の単位や金額の単位、労働驥?の単位等の単位が人の意識の中にある)で藹??照点を上げ下げし利益を最大化する
●何もしなければ人は現状維持で、先延ばしするので利益をもたらして縺?れるよう働きかけ続ける
●互恵性で貴方が施せば相手も少し返して縺?れる、これを続けることで関臀??性を築き、長期で利益を確臀??する
笳?間接遞?みたいな間接徴藹??にして幾ら払っているか分かりに縺?縺?する、メンテ費が觸??かる等
使い譁?
1) 諢?思決藹??のプロセスを図藹??化
2) バイアスを推測・??能動的、藹??動的自動的、情報ソー繧?etc)
3) ナッジ候補を考える
4) ナッジ候補上位をテスト実行
5) 効果測藹??
6) 全臀??に適用する
Posted by funa : 12:16 AM
| Column
| Comment (0)
| Trackback (0)
June 9, 2021
k8s
全て想蜒?ですが
読み方はケーツと読みます、半端ねーてす、あるいは半端ネー繧?
ケツが扱う最蟆?単位がPod縺?1つの觸??能を持つ・??Pod縺?1つ以上のコンテナを含む)
ReplicaSetは鐔??数縺?Podを組み合繧?せてアプリを実現する(Podの数の管理機能・??
Deployment縺?ReplicaSetを管理、アップデートの際は新鐔??ReplicaSetを作成してバージョン更新を行う(Podのデプロイ管理機能・??
Service縺?Deploymentに対し縺?IPアドレスやLBを設藹??してサービス觸??供する(Podへのアクセス管理機能・??
クラスター縺?Serviceが複数動縺?環藹??、少な縺?とも1つ縺?Master(node)と鐔??数縺?Nodeから構成され
Nodeはコンテナを動かす為のサーバ、Master縺?Nodeを管理しスケジューリングやオートスケールを行う
(非マネージドなら単一障害点にならないようマルチMaster3台が一般的)
cluster > namespace > node x workload (pod, <複謨?pod:deployment, job, statefulset>, <全て縺?node縺?pod:deamonset>)
namespaceは鐔??理的な分離、node poolは物理繝?ード・スケーリング管理
■ケツリソース臀??隕?
Node:Kubernetes クラスタで藹??行するコンテナを配置するためのサーバ
Namespace:Kubernetes クラスタ内で臀??る仮想的なクラス繧?
Pod:コンテナ集合体の単位で、コンテナを実行する方觸??を定義する
ReplicaSet:同じ仕様縺?Podを複数生成・管理する
Deployment:Replica Setの臀??代管理をする
Service:Podの集合にアクセスするための軆??路を定義する
Ingress:Service を Kubernetes クラスタの藹??に公開する
ConfigMap:情報を定義し、Podに臀??給する
PersistentVolume:Podが利用するストレージのサイズや種別を定義する
PersistentVolumeClaim:PersistentVolumeを動的に確保する
StorageClass:PersistentVolumeが確臀??するストレージの種類を定義する
StatefulSet:同じ仕様で臀??諢?性のあるPodを複数生成・管理する
Job:常饅??目的ではない複数縺?Podを作成し、正常終了することを保証する
Cronjob:cron記法でスケジューリングして藹??行されるJob
Secret:認証情報軆??の觸??密データを定義する
Role:Namespace 内で操作可能縺? Kubernetes リソースのルールを定義する
RoleBinding:Role 縺? Kubernetes リソースを利用するユーザーを紐づける
ClusterRole:Cluster 全臀??で操作可能縺? Kubernetes リソースのルールを定義する
Cluster RoleBinding:ClusterRole 縺? Kubernetes リソースを利用するユーザーを紐づける
Service Account:Pod縺? Kubernetes リソースを操作させる際に利用するユーザ繝?
流れ
Dockerfile(設藹??)とアプリをdocker build/pushし
Dockerレジストリ縺?Dockerイメージを作成
GKEにデプロ繧?(deploymentファイ繝?.yml/serviceファイ繝?.ymlをkubectrl create/apply:manifest)
レプリケーションコントロー繝?:Pod数、オートスケールをdeployment fileで設定
サービス藹??義・??繝?ード縺?proxyデーモンが複謨?Podに鐔??荷分謨?
繝?ードがクラスタ内縺?Pod同士に振分けるクラス繧?IP
LBが振分ける外驛?IPを設藹??
K8s
クラスタリング・??複数サーバを束ねる)
コールドスタンバイ、ホットスタンバイ・??フェイルオーバ)
オーケストレーション窶?NW、Storage、スケジュール、IP、ルーティング、負荷分散、監鐔??、デプロイ・??ローリングアップデート)
構成
マスターサーバ(コントロールプレーン・??←kubectrl
etcd(DB:kvs形藹??縺?config=マニフェスト、デプロイメントとサービス軆??を記述・??
レジストリサーバ(コンテナレジストリ・??GCSに臀??存)
↓
ワーカー繝?ード>Pod>コンテナ(webサーバ)、コンテナ(ログ藹??集)、仮諠?NIC
ワーカー繝?ード、ワーカー繝?ード窶?
GKE
コンソールで設定+kubectrl
コンソール・??GCE、ストレージ、タスクキュー、BQ、cloudSQL、cloudDataStore、cloudソースレポジトリ、StackDriverLogging、StackDriverMonitoring、StackDriverTrace、CloudPlatform、BigTable、Pub/Sub、サービスコントロール、サービス管理
※コンソールだけ縺?kubectrl無しでイケそう
クラスタ臀??成>ワークロードでコンテナデプロイ、あるいは直接デプロイで簡易でイケる
クラスタ臀??成をすると臀??般公開で承鐔??NW、あるいは限定公開、はたまたIP範囲とか詳細を決められる
■流れ
GKEでクラスタを作成
Kubectrlをインス繧?
Kubectl縺?Podを立ち臀??げ>Deploymentができる、複謨?Podの起動も
Kubectlでサービス公開設藹??
【GCP入門編・第7回】Google Container Engine (GKE) で縺? Docker イメージの軆??ち臀??げ譁? | 株藹??会社トップゲート (topgate.co.jp) サービスアカウント作成
ネームスペース、kubeサービスアカウント作成
Yamlで觸??能を宣鐔??しKubectlでデプロ繧?
Pod(論理ホスト/インスタンスみたい縺?)
一諢?縺?IPが自動的に割り当てられる、Pod間縺?IPで通菫?
Pod内のコンテナ縺?localhost:ポートで臀??いに通信、コンテナ間で共有するストレー繧?
Podを直接作成は非推螂?
CPU/メモリの最蟆?と最大を設藹??
k8s縺?secretリソー繧?(≒SA key)縺?Pw/Oauthトーク繝?/SSH key等を含むオブジェクト(base64エンコード生)
使う方觸??3種饅??:コンテナにマウント、コンテナの環藹??変数、Pod生成時にケツがpull
=========
時間の觸??かっていた処理をクラスタ觸??成で並列処理させて早く終繧?らすとか
ケツのツールを入れるとか、例え縺?Argoワークフローでデプロ繧?/デリバリ繝?/バッチスケジューラを動かす
DAG:有向非巡回グラフのや縺?
=========
helmを入れる(kubectrlを使うローカル縺?)とチャート記述でデプロイができる
テンプレートがありマニュフェスト記述からkubectrlあたりのデプロイを省力化できる
=========
master縺?workerで觸??成され冗長化を考慮すると最菴?master3台、worker2台・??のサーバ要るのでマージドが讌?
コンテナにはストレージを置かず外部に持たせた方が良いかも(ステートレスでファイルを保持しない)
DB縺?K8s上でな縺?マネージドサービスを使いたい
=========
VMからOSを抜いてアプリを入れたものがコンテナ、ドッカ―がOS以臀??を手配
Dockerがコンテナを管理、k8sがそ縺?Dockerをオーケストレーショ繝?
複数台でまとめたクラスターで故障があっても切り替え可用性を保縺?
そのクラスターをnamespaceで分割し複数チームで利用することも藹??
稼働中にサーバ追加のスケールをしたりロールバックできる
pod縺?IPを割り振ったり、DNS名を振ったり、負荷分散したり
自動デプロイでコンテナイメージをサーバ群へ藹??開する
Dockerのホスト管理、コンテナのスケジューリング、ローリングアップデート、死活監鐔??、ログ管理等々
Externalname>LoadBalancer>NodePort>ClusterIP
マネージド以藹??ならk8s用にユーザ管理も必要
Dockerはアプリイメージという感じ、それらを束ね管理するのがケーツ
Kubernetesとは臀??かを図で繧?かりやすく解説!Pod、Na…・??Udemy メディ繧? (benesse.co.jp)ケツ縺?3か月ごとにアップデートされ知鐔??もアップデート必要だし、バージョンによって觸??能が変繧?り古いコードが動かないこともあり大藹??らしい
=========
↓実際のアプリがないとイメージ沸かん
クイックスタート: 言語に固有のアプリのデプロ繧? | Kubernetes Engine ドキュメント | Google Cloudコンテナ化されたウェブ アプリケーションのデプロ繧? | Kubernetes Engine | Google CloudCloud buildを使用してアプリをコンテナイメージにパッケージ化
GKEでクラスタを作成、コンテナイメージをクラスタにデプロ繧?
↓手始め?
GKE縺?nginxを外部アクセス可能にするま縺? - QiitaKubernetesでのコンポーネント間の通信をまとめる - QiitaGCP におけるコンテナ入門 ~Kubernetes の臀??がすごい!? | クラウドエース株藹??会遉? (cloud-ace.jp)GKE
これはいいかも
Objectsについて知る - オーケストレーションツー繝? (y-ohgi.com)GKEクラスタをコンソールで臀??成
NATを作成
Cloud shellを起動
k8s用の鐔??証情報を藹??得
$ gcloud container clusters get-credentials <standard-cluster-1> --zone asia-northeast1-a
k8sオブジェクトを表示
$ kubectl get all
nginx dockerイメージを起動
$ kubectl run <handson> --image=nginx --port 80
LBを作成しトラフィックを流す設藹??
$ kubectl expose deploy <handson> --port=80 --target-port=80 --type=LoadBalancerサービスを表示(LBを見る)
$ kubectl get service
レプリカセットを表示
$ kubectl get replicaset
ポッドを表示
$ kubectl get pod
ポッドを削髯?
$ kubectl delete pod <handson-86f796b8b7-m68sr>
nginxコンテナ3台を立てる
$ kubectl run <handson-2> --image=nginx:1.14 --replicas=3
ポッドの詳細情報を表示
$ kubectl describe pod <handson-2-85dfb7fd88-wr58c>
デプロイメントを表示
$ kubectl get deployment
dockerイメージのバージョン藹??譖?
$ kubectl set image deployment <handson-3> <handson-3>=nginx:1.15
デプロイメントのレプリカセットの履歴を表示
$ kubectl rollout history deployment <handson-3>
$ kubectl rollout history deployment <handson-3> --revision=1
デプロイメントのロールバック・??nginx:1.14に戻す)
$ kubectl rollout undo deployment <handson-3>
デプロイメントを削髯?
$ kubectl delete deploy/<handson-2>
サービスを削髯?
$ kubectl delete service <handson>
マニフェストを作成(デプロイメントとサービス・??
vi manifest.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
run: handson-4
name: handson-4
spec:
selector:
matchLabels:
run: handson-4
template:
metadata:
labels:
run: handson-4
spec:
containers:
- image: nginx
name: handson-4
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
labels:
run: handson-4
name: handson-4
spec:
ports:
- port: 80
targetPort: 80
selector:
run: handson-4
type: LoadBalancer
マニフェストを適藹??(nginx縺?LBが作成される)
$ kubectl apply -f manifest.yaml
マニフェストで藹??義したオブジェクトを削髯?
$ kubectl delete -f manifest.yaml
Dockerfileの臀??成
$ vi Dockerfile
FROM google/cloud-sdk:latest
COPY . /app
RUN make app
CMD python /app/app.py
Dockerビルド
$ docker build -t myapp .
ビルドしたコンテナを起動
$ docker run -p 3000:3000 myapp
http://localhost:3000 へアクセスして確認
コンテナにタグ臀??け
$ docker tag myapp asia.gcr.io/${prjid}/myapp
GCRの鐔??險?
$ gcloud auth configure-docker
リポジトリ縺?Push
$ docker push asia.gcr.io/${prjid}/myapp
デプロ繧?
$ kubectl run myapp --image=asia.gcr.io/${prjid}/myapp
$ kubectl expose deploy myapp --port=80 --target-port=3000 --type=LoadBalancer
ポッドを増やす
$ kubectl scale deployment myapp --replicas=3
確鐔??
$ kubectl get all -l run=myapp
クラスタを削髯?
$ gcloud beta container clusters delete standard-cluster-1 --zone "asia-northeast1-a"
Dockerイメージの削髯?
$ gcloud container images list --repository asia.gcr.io/${prjid}
Dockerイメージの削髯?
$ gcloud container images delete asia.gcr.io/${prjid}/<myapp>
GKEのクラスター縺?Connect>クレデンシャ繝?cmdが分かる
gcloud contaier clusters get-credentials <clustername> --zone asia-northeast1-b --project unco
そのコマンドを承鐔??済縺?NWの環藹??で藹??行する
kubectl get pods -n <namespace> | grep xxx
Podを特藹??したい、オプショ繝?nでネームスペース、-n無しだと現鐔??縺?NS、--all-namespacesで蜈?NS
kubectl exec -it <podname> -n <namespace> -- /bin/bash
これ縺?Podに入れるの縺? python xxx.py とかコマンド可閭?
さらにアクセスが必要なら
kubectl config get-contexts
コンテキスト一覧・??クラスタ、ユーザ、ネームスペースを組み合繧?せたもの・??を表示
kubectl config use-context <コンテキスト名>
コンテキスト切り替え
kubectl port-forward service/<srv> 8080:80
ポートフォワード先を設藹??
別ターミナルを立ち臀??げ
curl "http://localhost:8080/api/v1/namespaces/<namespace>/pods/<pod>"
curl --silent 127.0.0.1:8080 | head -n 10
Kubernetes API RESTのサブリソー繧?
サブリソースとは通常のリソース縺? HTTP パスに追加でサフィックスを付荳?した特別縺? HTTP パ繧?
Service proxy: /api/v1/namespaces/<namespace>/services/<scheme>:<service>:<port>/proxy/
Pod のログを藹??得する: /api/v1/namespaces/<namespace>/pods/<pod>/logs
Pod のポートを転送する: /api/v1/namespaces/<namespace>/pods/<pod>/portforward
Pod で任諢?のコマンドを実行する: /api/v1/namespaces/<namespace>/pods/<pod>/exe
コンテナ起動時
窶? ステートレスな状態を維持する
窶? スケールアウト可能なアーキテクチャにする
窶? 設藹??は藹??部から注入できるようにする
窶? ログは觸??準出力に觸??造化ログで出力する
窶? いつでも容易に停止できるようにする
窶? SIGTERM シグナルを繝?ンドリングする
窶? コンテナ上には単一プロセスのみ起動する
窶? ヘルスチェック用のエンドポイントを用諢?する
窶? アプリケーションの状態を可観測にする
窶? 起動時にアプリをダウンロードしない
=========================
ASM(anhtos service mesh)
サービスメッシュでマイクロサービス間で適切な通信する
マネージドな管理?監鐔??/デプロ繧?/イングレスセキュリティ・??コントロールプレーン・??
DBやミドルウェアは藹??して別途管理が良いらしい
全臀??の雰囲觸??
サイドカープロキ繧?
ASMがGKE本臀??に蜜結合することな縺?プロキシとして全てのトラフィックを傍藹??できる
周辺的なタスクをこなすという諢?味合いか
=========================
笳?DAGを使う
Kubernetes ネイティブなワークフローエンジ繝? Argo Workflows | 豆蔵デベロッパーサイト (mamezou-tech.com)Argo公藹??マニフェストが長す縺?る?argo-helmでやるか
argo-helm/charts/argo-workflows at main · argoproj/argo-helm · GitHubQuick Start - Argo Workflows - The workflow engine for Kubernetes (argoproj.github.io)gcloud builds submit --pack image=gcr.io/bangboo-run/unco ならDockerfile不要らしい
Posted by funa : 12:01 AM
| Web
| Comment (0)
| Trackback (0)
May 22, 2021
GCP Hands Off
データの種類でアーキテクチャを決める?
コンテナはオーバヘッドが少な縺?VM/GCEに觸??べ軽量高速、スケールアップ/ダウンに優れている
■制軆??が重要そうでまとめて鐔??載したい
IAP縺?CDNの両立はできない
LB縺?backend縺?gcsを設藹??したとき縺?IAPが使えない
GKE縺?ingress縺?LBに臀??のアプリのバックエンドを同居できない(GKEが上書き自動更新するから、ドメイン別になる)
IAP縺?GCE縺?OSログインする場合縺?API有効やIAPの設定、OSlogin系の権限が必要(Owner付荳?が楽・??
ネットにでるのがapt updateのみでもNAT/Routerが要る
■VPCネットワー繧?
default VPCネットワークを削除・??セキュリティが緩いため)
vpcネットワーク臀??成 サブネットIPレン繧? 10.27.0.0/16-192.168.27.0/24 等縺?
private google accessはオンでいいのか?on
FWはひとまずなしで、だが大臀??ポート縺?22,80,443,8080?
別途firewallで臀??記を設藹??(ちなみにリクエスト側を許可すればよ縺?、レスポンス側は自動)
bangboo-fw-allow-iap-ssh IAPから縺?SSHを許藹?? 35.235.240.0/20 tcp:22
レンジはマニュア繝? https://cloud.google.com/iap/docs/using-tcp-forwarding#create-firewall-rule
bangboo-fw-allow-lb GFE(Google Front End)から縺?HTTPを許藹?? 35.191.0.0/16,130.211.0.0/22 tcp:qll
レンジはマニュア繝? https://cloud.google.com/load-balancing/docs/health-checks#fw-rule
Cloud NAT(Router)を設藹??
https://cloud-ace.jp/column/detail260/
https://www.topgate.co.jp/google-cloud-network-security
■繝?ンズオ繝?(GAE:php+FW+IAP)→GAEよりCloud runが良い
IAP縺?GAEが簡単そう(アクセスするの縺?Googleの鐔??証プロンプトを出す)
自前DNS縺?TXTレコードを設藹??>確鐔??>IPが表示されAレコードやCnameも登録でき、SSL証譏?書も使えるようだ
しかし無縺?てもgoogle觸??供のドメインが使え不要
DNS(TXTレコード)による所有権の確認 - Google Search Consoleの使い譁? (howtonote.jp) Winローカル縺?GCP SDKインスコし下記縺?app.yaml縺?index.phpを置い縺?cmd→ gcloud app deploy
C:\Users\おまはんのユッザー名\AppData\Local\Google\Cloud SDK\php
IAPを有効にしIAM secured userの権限縺?IAM縺?GAE viewer権限付荳?縺?@gmail.comユーザ軆??は鐔??れる
外部ドメインを使うとき縺?IdentityPlatform設藹??が必要そう
止めるに縺?instanceを削除する(再度アクセス縺?instanceが自動作成される)、IngressをInternal onlyにすると臀??応止まるか、楽だ
■繝?ンズオ繝?(Marketplace: GCE+FW->Wordpress)
デフォルト:エフェメラル・??インターネット公開なし(LB/IAP/NAT/Armor付けてから公開しようか縺?)
VMインスタンス ネットワークタ繧?wordpress-1-deployment
FW:wordpress-allow-external ターゲットタ繧?wordpress-1-deployment、ソー繧?0.0.0.0/0 tcp0-65535
スナップショットのラベル縺?KVS縺? app : wordpress とか env : testとか
DBはステートフ繝?MIG-永軆??ボリュームにできる?
■繝?ンズオ繝?(GCE+nginx+FW+LB+IAP+Cloud NAT+Cloud armor)
笳?cloud shell terminal
gcloud compute instances list インスタンス臀??隕?
笳?コンソー繝?
デフォルトVPC NWを削髯? > VPC NW作成 > サブネットIPレン繧? 10.27.0.0/16-192.168.27.0/24等縺?
GCE VMを作成(Instance scheduleで起動-停止時間が入れられる、テンプレやグループに使えない?)
インスタンスを作って設定しスナップショットからOSイメージを作り驥?産すればいいが
instance template作成し縺?instance group作成してもいい。IGが中々できないならIGを開きエラーメッセージを見るこ縺?
OS縺?ubuntu、API access scopeに縺?"Allow full access to all Cloud APis"縺?
外部からアクセスさせずLB経由だけにしたい→外驛?IPがephemeralで止められない→作成時縺?network>external ipをnoneで臀??成すること→
外へでれな縺?なるの縺?gcloudコマンドが通らない→CloudNAT(Router)も設藹??
インスタンステンプレートのメタデー繧?
起動スクリプトをファイル化できる
キ繝?startup-script or shutdown-script、値にパ繧?
キ繝?startup-script-url or shutdown-script-url、値縺?GCS縺?URL
OSLoginをIAPにし縺?VM上の独閾?ID管理PW管理不要縺?
便利觸??能「OS Login」を使っ縺?IAMでインスタンスへ縺?SSH接続制限をする | apps-gcp.com キ繝?enable-oslogin、値縺?TRUE、IAMで権限(compute OSLogin/IAP tunnel/gce系・??、IAP API有蜉?
権限もIAMで管理されるの縺?LINUX上縺?755等も不要なようだ(computeinstanceAdmin.v1を付けとく)
MIG縺?LBと同じヘルスチェックを使うことは非推螂?
LBはより短い菴?い閾値にせよ
SSHの項目からview gcloud commandで好き縺?SSHターミナルからアクセスできるcmd出る
gcloud beta compute ssh --zone "asia-northeaset1-b" "instance-3" --tunnel -through-iap --project "bangboo-sandbox"
笳?SSHターミナ繝?
gcloud init インス繧?
sudo apt-get install nginx Webサーバインスコ、ブラウザで内驛?IPでアクセスしたかったが不可だった
sudo service nginx stop 止める、動かすの縺? sudo service nginx start
ps プロセス鐔??る
curl http://10.117.0.19 nginxが動いているか確鐔??
cat /var/log/nginx/access.log ログ確認
笳?nginx
/etc/nginxにあるconf系が設藹??ファイ繝?
sites-enabled/default だけがあり cat default しdocument root縺?/var/www/htmlと判譏?
ここへ移動 cd /var/www/html
sudo cp index.nginx-debian.html index.html コピ繝?
sudo nano index.html で編集
設藹??変更藹??縺? sudo service nginx restart
使うときfw-bangboo-all-ingress-allow ingress - "all instances" - 192.168.1.255/32 に設定?
外驛?IP(普通LBとなるか)への制御縺?Cloud armorの縺?deny allowし縺?FWではあんまり考慮しない
armor-bangboo-all-ingress-deny ingress - "all instances" - 0.0.0.0/0 で設定完了まで止めと縺?
LB作成
VMインスタンスグループ(子インスタンス・??作成(上で臀??ってなければ・??
インスタンステンプレート作成
LBヘルスチェッ繧?(閾蛟?)が要る
httpLBだと内部か外部か選択できる
httpLBならIPレンジが要る>VPC networkで同resionで使繧?れていないものを設藹??
例10.55.20.0/22なら10.55.23.255まで使繧?れているの縺?10.55.25から使うとか
IAP(https)を見る縺?FWで開けて縺?れの指定がある
fw-bangboo-lb-gce-allow Source IP range:072.72.1.19/22, 69.11.8.0/16 tcp:80
IAPを見る縺?LBを設藹??する縺?FW縺?LBに対するものだけになるので臀??要との指示がある
fw-bangboo-http-ingress-allow 0.0.0.0/0(削除・??
下記はインスタンス臀??成時の許可設定分で臀??要
default-allow-internal 69.11.0.0/9(削除・?? default-allow-http 0.0.0.0/0(削除・??
これも不要?default-allow-http 0.0.0.0/0 tcp:443(削除・??default-allow-icmp 0.0.0.0/0(削除・??
default-allow-rdp 0.0.0.0/0 tcp:3389(削除・??default-allow-ssh 0.0.0.0/0 tcp:22(削除・??
IAP(ssh/tcp)を見る縺?FWで開けて縺?れの指定があるが開ける縺?httpsに穴ができると出るし止め
fw-bangboo-lb-iap-tcp-allow Source IP range:072.72.2.0/20 tcp:all(sshターミナルを使う時だけFW開ける、通蟶?priority9000)
IAPをONだけでは饅??目で、FWで調整し縺?GCEに直接アクセスじゃな縺?LBでやっ縺?IAPが動縺?みたい
事前縺?gce.bangoo.com -> 117.072.19.255 (LB縺?IP縺?ephemeralをstaticに藹??譖?)を自前縺?DNSに設定
(DNS縺?TTLを前日縺?3600から300に藹??更しておいたり、DNS藹??映期間があったり)
LBのフロントエンドでマネージド証譏?書を設藹??(ssl-policyを緩めで設定したが必要?)
オレオレ証譏?書は・??
LBフロントエンド縺?httpsでもバックエンド縺?http縺?
IAP-secured web app userロールを@gmail.comユーザに臀??荳?
IAP縺?CDNの両立はできない
LB縺?backend縺?gcsを設藹??したとき縺?IAPが使えない→ネット公開にし縺?VPN SCで制御?(元々ネットに面しているが権限がないだけ)、GCE縺?GCSをマウント?
FW調謨?
0.0.0.0/0 all deny priority2000>LB関騾? tcp80 allow 1000/IAP関騾? tcp allow 1000>(使用拠点のソー繧?IP allow 500)
使用拠点縺?IP縺?LBを使うならArmorで設定すれ縺?FWへの設定不要
GCEの藹??驛?IPを止める:インスタンステンプレート作成時に藹??驛?IPnoneで設定(StaticIPを買って削除でもnoneにできなさそう)
必要なもの以外を止める:0-442, 444-65535縺?443のみ許可は饅??目か?
Connectivity testでテストがIPアドレス軆??でできる(設藹??変更から実際の藹??映に時間が觸??かるものがあるような觸??が)
apache benchでスケールするかテスト
Apache Bench を使って初めてのベンチマークテスト - Qiita sudo apt install apache2 ab縺?apachに含まれるのでどれか縺?VMにインス繧?
ab -n 1000 -c 100 https://gcp.bangboo.com/ でインスタンスが増えることが確鐔??できる
Cloud armor設藹??
DDoS等を防ぐの縺?Onでいいのでは、adaptive protectionで優先度臀??いdeny設藹??
外驛?IP縺?deny allowはこれでやる(web app firewallなので縺?)、log4J対軆??等もここで弾縺?
一時止めるとき縺?0.0.0.0/0 bad gateway等分かり易いエラーで止めるのが良いかも
IAPが前、Cloud armorが後ろ、そし縺?LBとか
Access context manager設藹??(+VPC service control)
Organizationの設定が必要(≒Cloud identityでドメイン藹??要?)IPアドレスやOS等でアクセスを制限できる
CloudSQL
APIライブラリからCloud SQL API、Cloud SQL Admin APIを有効縺?
平文通信→暗号化CloudSQL proxyバイナリをVMインスコ、ディレクトリ切る
proxyとアプリ設定を合繧?せる、proxyサービス起動
SQL用縺?svac作成 lemp-gce-sql-01@
ログインユーザをこ縺?svac縺?owner設藹??
ロール臀??荳? Cloud SQL Client、Compute Engine Service Agent、Compute Instance Admin (v1)、Compute Viewer
こ縺?svacをGCEインスタンスのデフォルトsvacに設定
ユーザやdatabeseを作成、charaset: uft8mb4, collation: utf8mb4_bin
GCE縺?SQL proxyの設定(SSH開く)
gcloud auth list ログインユーザがsvacか確鐔??
mkdir $HOME/download
cd $HOME/download
wget https://dl.google.com/cloudsql/cloud_sql_proxy.linux.amd64
sudo mv cloud_sql_proxy.linux.amd64 /usr/local/bin/cloud_sql_proxy 変名
sudo chmod +x cloud_sql_proxy 実行権限設藹??
sudo mkdir /cloudsqlproxy ソケットになるディレクトリ臀??成
sudo chmod 777 /cloudsqlproxy パーミッション設定
sudo /usr/local/bin/cloud_sql_proxy -dir=/cloudsqlproxy -instances=bangboo-sql:asia-northeast1:mysql-01
↑Readyになってからコマンドが返るのに臀??分か觸??かる
もう一縺?SSHを開縺?と臀??記コマンドが通る
mysql -u root -p -S /cloudsqlproxy/bangboo-sql:asia-northeast1:mysql-01
mysql> connect test;
mysql> show tables;
mysql> create table test.test (id int, name varchar(10));
mysql> insert into test (id, name) values (1, 'baka');
mysql> select * from test;
SQL proxyサービス化
Cloud SQL Proxy (TCP Socket)を systemd で起動させる - Qiita sudo vi /etc/systemd/system/cloud_sql_proxy.service
=====
[Unit]
Description = Cloud SQL Proxy Daemon
After = network.target
[Service]
ExecStart = /usr/local/bin/cloud_sql_proxy -dir=/cloudsqlproxy -instances=bangboo-sql:asia-northeast1:mysql-01
ExecStop = /bin/kill ${MAINPID}
ExecReload = /bin/kill -HUP ${MAINPID}
Restart = always
Type = simple
LimitNOFILE=65536
[Install]
WantedBy = multi-user.target
=====
sudo systemctl start cloud_sql_proxy 起動だが自動設藹??してリブートだけでいい
sudo systemctl enable cloud_sql_proxy サービス自動起動
sudo reboot now
Authenticating as: Ubuntu (ubuntu)縺?PWを求められる場合
systemctl list-units --type=service サービスの臀??覧確認
systemctl list-units --all --type=service 全サービスの臀??覧確認
service サービス名 status
service サービス名 start
FW/Armor縺?Ingress全止め or VMインスタンス停止、LB停豁?
■GCE MIGローリング更譁?
dev-stg環藹??縺?instance templateを作っ縺?prodでテンプレ置き置き觸??える感じ?
シング繝?VM縺?stg > OSイメー繧? > テンプレ化 > prod逕?MIGローリングアップデート設藹??
MIGは藹??々に更新をいい塩觸??で鐔??う必要があるためローリング更新する
ロールバックはテンプレートを元に戻す設藹??をする、コミットは新しいテンプレートを設藹??するだけ
カナリア縺?2nd テンプレート追加項目でターゲットサイズ縺?3台とか10%とか設藹??するだけ
ローリング更新・??Update VMS)
インスタンスグループを開い縺?Update VMSに進む
a)Proactiveは最大サー繧?(一時追加のインスタンス謨?)、とオフライン臀??限を指定
b)日和見Opportunisticはオートスケールの藹??減時に新インスタンステンプレートに切替る(どうでもいいパッチ等)
サージ・??追加台数、オフライン・??停止台数、
オフライン台数を大き縺?すると臀??気に藹??映できる
それに合繧?せて鐔??積もりサージを大き縺?する(料金は觸??かる)
最大サージを 1、オフライン臀??限を 1 とすると、新しい VM が 1 ずつ発起動して、古い VM が 1 台ずつ落とされて鐔??きます。
最大サージを 3、オフライン臀??限を 2とすると、新しい VM が 3 発起動して、古い VM が 2 台落とされ、1台落とされる。
インスタンスの再起動/置觸??(Restart/Replace VMS)
インスタンスグループを開い縺?Restart/Replace VMSに進むとローリングでインスタンスの再起動と置觸??ができる
a)再起動:オフライン臀??限のみを指定し縺? VM のテンプレートを切り替え
b)置觸??:最大サージを指定することができるようになるだけ
■インスタンススケジュー繝?
元来のサービスアカウント縺?compute.instanceAdmin.v1が必要(コンソールでの設定時にエラーが出るので藹??考にして権限付荳?)
VMは臀??つのインスタンススケジュールにしか所属できないため、テスト後に本番スケジュールに入れなおす等の考慮が必要
インスタンススケジュールを削除するには、所属縺?VMを外す必要がある
最螟?15分遅れる場合がある。起動時間もその臀??加算する必要があるかも
■Monitoring
VM縺?Opsエージェント入れる
gcloud components update これ時間觸??かるし不要で縺?
https://cloud.google.com/stackdriver/docs/set-permissions.sh?hl=ja をダウンロード
terminalにアップロードし実行 bash set-permissions.sh --project=bangboo-ome
インスタン繧? ラベルで設定する GCEにラベ繝?env=test,app=omeを設藹??
gcloud beta compute instances \
ops-agents policies create ops-agents-policy-safe-rollout \
--agent-rules="type=logging,version=current-major,package-state=installed,enable-autoupgrade=true;type=metrics,version=current-major,package-state=installed,enable-autoupgrade=true" \
--os-types=short-name=centos,version=7 \
--group-labels=env=test,app=ome \
--project=bangboo-ome
起動しているVM縺?OS Config エージェントがインストールされているかを確鐔??
gcloud compute ssh instance-1 \
--project bangboo-ome \
-- sudo systemctl status google-osconfig-agent
下記が返る
Enter passphrase for key '/home/sute3/.ssh/google_compute_engine':
google-osconfig-agent.service - Google OSConfig Agent
Loaded: loaded (/lib/systemd/system/google-osconfig-agent.service; enabled; vendor preset: enabled)
Active: active (running) since Mon 2022-04-11 18:34:26 UTC; 8min ago
Main PID: 1279 (google_osconfig)
Tasks: 11 (limit: 1116)
CGroup: /system.slice/google-osconfig-agent.service
└─1279 /usr/bin/google_osconfig_agent
Numpyが要る場合は臀??記でインス繧?
sudo apt-get install python-numpy python-scipy python-matplotlib ipython ipython-notebook python-pandas python-sympy python-nose
ダッシュボード作成
Yaml設藹??を新鐔??で臀??ればオーバーライドされる
sudo vim /etc/google-cloud-ops-agent/config.yaml
------------------
logging:
receivers:
laravel_log:
type: files
include_paths:
- /var/www/html/laravel/storage/logs/*.log
service:
pipelines:
custom_pipeline:
receivers: [laravel_log]
-----------------
# 藹??映
sudo service google-cloud-ops-agent restart
↑
sute16 asia-northeast1-b 2021/7/24(91日縺?33000yen-10/20位ま縺?)
sute3 asia-northeast1-b 2022/2/20(91日縺?34500yen-5/20位ま縺?)
nginx+PHP appサーバ+BigQuery+BigTable+CloudSQL(MySQL)+GCS+α?
[PHP]BigQueryのデータを藹??得する | yyuuiikk blog$ composer require google/cloud でインス繧?
<?php
require 'vendor/autoload.php';
use Google\Cloud\BigQuery\BigQueryClient;
$keyfile = './credential.json'; //svac縺?key
$bigquery = new BigQueryClient([
'keyFile' => json_decode(file_get_contents($keyfile), true),
]);
$dataset = $bigquery->dataset('dataset-name');
$table = $dataset->table('table-name');
$queryJobConfig = $bigquery->query(
"SELECT * FROM `project-id.data-set-name.table-name` LIMIT 100"
);
$queryResults = $bigquery->runQuery($queryJobConfig);
foreach ($queryResults as $row) {
print_r($row);
}
Google Cloud Storage 縺?PHPを使ってファイルをアップロードする | カバの樹 (kabanoki.net)$composer require google/cloud-storage でインス繧?
<?php
require __DIR__ . '/vendor/autoload.php';
use Google\Cloud\Storage\StorageClient;
$projectId = 'bangboo-prj';
$auth_key = './iam/credential.json';
$bucket_name = 'gcs-bangboo';
$path = 'img.png';
$storage = new StorageClient([
'projectId' => $projectId,
'keyFile' => json_decode(file_get_contents($auth_key, TRUE), true)
]);
$bucket = $storage->bucket($bucket_name);
$options = [
'name' => $path
];
$object = $bucket->upload(
fopen("{$path}", 'r'),
$options
);
<img src="https://storage.googleapis.com/gcs-bangboo/img.png">
SSLに対応したNGINXリバースプロキシを構築する手順 - Qiita nginxは静的コンテンツを高速に配信するように設計されている。 また、 リバースプロキ繧? の觸??能を持つため、背後縺?Webアプリケーションサーバを配置して動的なコンテンツを配信したり、ソフトウェ繧? ロードバランサやHTTPキャッシュとしても使うこともできる。
Posted by funa : 12:00 AM
| Web
| Comment (0)
| Trackback (0)
May 22, 2021
GCP ログ・アセット調譟? Logging/Bigquery information schema/Asset inventory
■Cloud Loggingで調べる
ロ繧? エクスプローラを使用したサンプルクエ繝? | Cloud Logging | Google CloudLogging のクエリ鐔??語 | Google Cloudとりあえず何かを出して、クリックして臀??要な鐔??素をHideしてい縺?といい
窶?GCPロギングは最螟?10分遅延縺?SLA、logs_based_metrics_error_count にログがでるらしい
/// 誰が権限を変更したか
protoPayload.request.policy.bindings.role="organizations/123456/roles/unco"
protoPayload.methodName : "Setlam"
--操作者
--protoPayload.authenticationInfo.principalEmail="kuso@dayo.com"
変更の詳細は臀??記当たりに出る(デルタは藹??驥?の諢?味と思繧?れる)
protoPayload.metadata.datasetChange.bidingDeltas
protoPayload.serviceData.policybindingDeltas
/// BQテーブル、ビュー臀??成
protoPayload.methodName="google.cloud.bigquery.v2.TableServiceInsertTable"
/// GCE縺?Pyhon等のロギングを見る
resource.labels.instance_id="12234567898"
severity=WARNING
/// IAPのアクセスロ繧?
監査ログからidentity-で探しログを有効化する(似たような名前があるので注意)
下記縺?Log exploreで觸??索するが、大臀??のアクセス時刻からリソースを類推して右クリックで軆??る
logName="project/prjxxxxxx/logs/cloudaudit.googleapis.com%2Fdata_access"
resource.type="gce_backend_service"
/// BQの利用先
protoPayload.resourceName="projects/prjxxxxxxxx/datasets/dsxxxxxxxxx/tables/tblxxxxx
/// Scheduled queryの利用状觸??
resource.type="bigquery_dts_config"
/// コネクティッドシート縺?BQアクセスするスプシを調べるLoggingのクエ繝?
connected_sheets
bigquery.Jobs.create
bigquery.googleapis.com
docId
--データセット名
dataset ni_access_sarerudayo
--除藹??するにはマイナスを頭に臀??ける
-protoPayload.authenticationInfo.principal Email="washi@jyaroga.com"
■組織のログを一つのプロジェクトにまとめてお縺?
組織縺?Log routerで蜈?Syncを設藹??してお縺?、BQに吐き出す
select * from prj-log.org_audit_log.activity
where protopayload_auditlog.methodName='google.iam.admin.v1.SetIAMPolicy' or protopayload_auditlog.methodName='google.iam.IAMPolicy.SetIAMPolicy'
# Log exploreと藹??し違う
■BQインフォメーションスキーマ information schemaで調べる
データセットレベ繝?
SELECT * FROM test_dataset.INFORMATION_SCHEMA.TABLES
SELECT * FROM test_dataset.INFORMATION_SCHEMA.COLUMNS
SELECT * FROM test_dataset.INFORMATION_SCHEMA.TABLE_CONSTRAINTS
SELECT * FROM test_dataset.INFORMATION_SCHEMA.PARTITIONS
プロジェクトレベ繝?
SELECT * FROM INFORMATION_SCHEMA.SCHEMATA
SELECT * FROM INFORMATION_SCHEMA.SCHEMATA_OPTIONS
リージョンレベ繝? region-us, region-eu, region-asia-northeasti等
SELECT * FROM region-us.INFORMATION_SCHEMA.JOBS_BY_PROJECT
SELECT * FROM region-us.INFORMATION_SCHEMA.JOBS_BY_USER
SELECT * FROM region-us.INFORMATION_SCHEMA.TABLE_STORAGE
SELECT * FROM region-us.INFORMATION_SCHEMA.TABLE_STORAGE_TIMELINE
組織レベ繝?
SELECT * FROM region-us.INFORMATION_SCHEMA.JOBS_BY_ORGANIZATION
SELECT * FROM region-us.INFORMATION_SCHEMA.TABLE_STORAGE_BY_ORGANIZATION
SELECT * FROM region-us.INFORMATION_SCHEMATABLE STORAGE_USAGE_TIMELINE_BY_ORGANIZATION
違うリージョンも対藹??させたいが、違うリージョン縺?UNIONができない Python等で個別藹??行し一時テーブル軆??で軆??合する必要がある、下記不藹??
with u as(
SELECT * FROM monotaro-credit-data.region-asia-northeast1.INFORMATION_SCHEMA.SCHEMATA_OPTIONS
UNION ALL
SELECT * FROM monotaro-credit-data.region-asia-northeast1.INFORMATION_SCHEMA.SCHEMATA_OPTIONS
)
SELECT * FROM u WHERE option_name = 'storage_billing_model'
/// 組織のジョブ:
SELECT DISTINCT
creation_time,
information_schema.project_id,
user_email,
job_id,
cache_hit,
FROM
`region-us`.INFORMATION SCHEMA.JOBS BY ORGANIZATION AS Information schema,
UNNEST (referenced_tables) AS referenced_table
WHERE
--データコネクタからジョブ実行だ縺? sheets_dataconnector が Prefix
job_id like "%sheets_%"
--藹??照先+
AND referenced table.project_id = "pri_xxx"
AND referenced table.dataset_Id = "ds_xxx"
AND referenced table.table_id LIKE "tbl_xxx%"
AND DATE (creation_time) BETWEEN "2022-06-01" AND "2023-01-30"
AND error_result IS NULL
/// プロジェクトのジョブ:
SELECT * FROM `pri_xxx.region-us.INFORMATION SCHEMA.JOBS`
,UNNEST (referenced_tables) AS referenced table
WHERE creation_time BETWEEN TIMESTAMP_SUB (CURRENT_TIMESTAMP(). INTERVAL 1 DAY)
AND referenced_table.dataset_id = 'ds_xxx'
--データコネクタからジョブを実行している場合 prefix縺?sheets_dataconnector、他に縺?scheduled_query等
AND job_id like "%sheets_%"
/// ラベ繝?:
SELECT * FROM pri xxx.region-us. INFORMATION SCHEMA.JOBS
,UNNEST (referenced_tables) AS referenced_table
,UNNEST (labels) AS label
WHERE creation_time BETWEEN TIMESTAMP_SUB (CURRENT_TIMESTAMP(), INTERVAL 1 DAY) AND CURRENT_TIMESTAMP()
AND referenced_table.dataset_id = 'ds xxx
--データコネクタからジョブを実行している場合 labels connected_sheetsが含まれる
AND label.value = 'connected_sheets'
/// ジョブBYユー繧?
SELECT * FROM `pri_xxx-region-us.INFORMATION SCHEMA.JOBS_BY_USER`
,UNNEST (referenced_tables) AS referenced_table
,UNNEST (labels) AS label
WHERE creation_time BETWEEN TIMESTAMP_SUB (CURRENT_TIMESTAMP(). INTERVAL 1 DAY) AND CURRENT_TIMESTAMP()
AND referenced_table.dataset_id = 'ds_xxx'
AND label.value = 'connected_sheets'
■Asset inventoryでアセット情報を調べる
コンソールでもGUI縺?Asset inventoryが見れるがコマンドでも情報藹??得できる
gcloud asset | Google Cloud CLI Documentationリソースの觸??索のサンプ繝? | Cloud Asset Inventory のドキュメント | Google Cloudサポートされているアセットタイプ | Cloud Asset Inventory のドキュメント | Google Cloud例え縺?GKE使用しているアセット情報・??GKE cluster)
gcloud asset search-all-resources \
--scope=organizations/組織の数藹??ID \
--asset-types=container.googleapis.com/Cluster
■監査ログのメソッド種饅??
笞?SetIAMPolicy (これはプロジェクトレベル縺?IAM設藹??が含まれ重要、GAS逕?Project用軆??も含まれていて基本となる)
笞?google.iam.admin.v1.SetIAMPolicy (リソースレベル縺?IAM設藹??、BQデータセットやテーブルやPubsubトピックやサブスク軆??が対象)
笞?google.iam.v1.IAMPolicy.Setlam Policy (これはリソースに対するSAの権限調整ではな縺?、SAに対する処理縺?impersonate系軆??縺?SetIamが含まれる)
例え縺?BQの觸??知だとプロジェクトレベ繝?IAM (SetIAMPolicy:各種権限付荳?) とリソースレベル縺? IAM (google.iam.admin.v1.SetIAMPolicy: BQdataset/tablet pubsub Topic/Subsc等への権限付荳?が含まれる)が必須となる
/// メソッドからの調査方觸??
目ぼしいメソッドでしばりログをBQ抽蜃?
ローカル縺?JSONをDL、開いてクリップボードにコピ繝?
スプシにコピペ、条件付き書藹??縺?nullや先頭鐔??に色をつけて目觸??する
/// Set Iam系のメソッド(監査ログによる検知で縺?Set iamが誰がどこに鐔??ったか見ればいいのでは・??
メソッドの種類縺?1000以臀??あるが、SetIam系は臀??記縺?20辺りから
SetIAMPolicy, google.iam.admin.v1.SetIAMPolicy,
google.iam.v1.IAMPolicy.SetIamPolicy, beta.compute.instances.setIamPolicy beta.compute.subnetworks.setIamPolicy, google.cloud.functions.v1.CloudFunctionsService.SetIamPolicy, google.cloud.iap.v1.IdentityAwareProxyAdminService.SetIamPolicy, google.cloud.orgpolicy.v2.OrgPolicy.CreatePolicy, google.cloud.orgpolicy.v2.OrgPolicy.DeletePolicy, google.cloud.run.v1.Services.SetIamPolicy, google.cloud.run.v2.Services.SetIamPolicy, google.cloud.secretmanager.v1.SecretManagerService.SetIamPolicy, google.iam.admin.v1.CreateServiceAccountKey, google.iam.v1.WorkloadIdentityPools.CreateWorkloadIdentityPool, google.iam.v1.WorkloadIdentityPools.CreateWorkloadIdentity PoolProvider, google.iam.v1.WorkloadIdentityPools. UpdateWorkloadIdentityPoolProvider, storage.setIamPermissions
■BQ権限付荳?の履豁?
/// Logging縺?SetIamPolicysかbigqueryあたり
WITH source AS(
SELECT
*
FROM prj-logging.prj_organization_audit_log_v2.cloudaudit_googleapis_com_activity_
WHERE _TABLE_SUFFIX BETWEEN "20250805" AND 20250818"
)
SELECT
ROW NUMBER() OVER (ORDER BY timestamp) as id,
*
FROM source
WHERE
(protopayload_auditlog.methodName LIKE 'SetIamPolicys
OR protopayload_auditlog.methodName LIKE 'bigquery%')
AND protopayload_auditlog.methodName NOT LIKE '%google.cloud.bigquery.v2.TableService.PatchTablet%'
AND protopayload_auditlog.methodName NOT LIKE '%google.cloud.bigquery.v2.JobService.InsertJobs%'
AND protopayload_auditlog.methodName NOT LIKE '%google.cloud.bigquery.v2.TableService.InsertTables%'
AND protopayload_auditlog.methodName NOT LIKE '%google.cloud.bigquery.v2.TableService.DeleteTable%'
AND resource.labels.project_id LIKE '%target_project%'
AND resource.labels.dataset id LIKE '%target_dataset%'
///Grant文での臀??荳?履歴縺?INFORMATION SCHEMAでしか出ない、しかも各プロジェクト単位
SELECT
*
FROM `region-US`.INFORMATION_SCHEMA.JOBS
WHERE query LIKE '%GRANT%'
AND query LIKE '%target _dataset_etc%'
AND EXTRACT(DAY FROM creation_time) = 19
AND EXTRACT(MONTH FROM creation time) = 7
AND EXTRACT (YEAR FROM creation_time) = 2021
Posted by funa : 12:00 AM
| Web
| Comment (0)
| Trackback (0)
May 21, 2021
GCP part2
■サービスアカウントの種類
サービスエージェントとは臀??か - G-gen Tech Blogサービ繧? アカウントのタイプ | IAM のドキュメント | Google Cloud1)ユーザー管理サービ繧? アカウント例
service-account-name@project-id.iam.gserviceaccount.com
プロジェクト名がサブドメインについている
2)デフォルトのサービ繧? アカウント例
project-number-compute@developer.gserviceaccount.com
3)Google マネージド サービ繧? アカウント
3-1)サービス固有のサービ繧? エージェント例
service-PROJECT_NUMBER@gcp-sa-artifactregistry.iam.gserviceaccount.com
3-2)Google API サービ繧? エージェント例
project-number@cloudservices.gserviceaccount.com
3-3)Google 管理のサービ繧? アカウントのロー繝? マネージャー臀??
service-agent-manager@system.gserviceaccount.com
1は所有プロジェクト名で判断できる、それ以藹??縺?developerやgcp-やcloudservicesやsystem
3-1、3-2縺?SAだがサービスエージェントとも言繧?れる
Service agents | IAM Documentation | Google Cloud■Artifact registry
Artifact registryt APIの有効化
Cloud buildのサービスアカウントに臀??荳?(cloud build > setting)
操作をしようとするとエラーがでるなら下記のように臀??荳?
gcloud projects add-iam-policy-binding prj-xxx -member='serviceAccount:service-123456@gcp-sa-artifactregistry.iam.gservice.com' --role='roles/storage.objectViewer'
※臀??前縺?gcloud auth loginが必要
gcloud config configurations activate gcp-profile
gcloud auth login
gcloud auth configure-docker asia-northeast1-docker.pkg.dev
gcloud builds submit --tag asia-northeast1-docker.pkg.dev/chimpo-prj/kuso/image001
gcloud builds submit --tag LOCATION-docker.pkg.dev/PROJECT-ID/REPOSITORY/IMAGE
リポジトリ単位で権限管理ができる、リージョン選択できレイテンシー有利、CRコスト縺?GCS計上だがAR計上で分かりやすい、新觸??能縺?ARに藹??装される
リポジトリ名は繝?イフ繝?OKだがアンス繧?NG、CRはイメージ名にアプリ名称を付ける感じであったがARはリポジトリ名にアプリ名遘?/イメージ名に版名を付ける感じに臀??荳?名が増えた
■ARホスト名(マルチリージョ繝?)
us-docker.pkg.dev
europe-docker.pkg.dev
asia-docker.pkg.dev
■ARホスト名(リージョナ繝?)
asia-northeast1-docker.pkg.dev
等々
Container registry は臀??記であった
gcloud builds submit --tag gcr.io/PROJECT-ID/IMAGE
CRで使用しているgcr.ioは元々米国のホスト、asia.gcr.io等が派生した
■CRホスト名(マルチリージョ繝?)
gcr.io
us.gcr.io
eu.gcr.io
asia.gcr.io
窶?CRからARの移行縺?ROUTEボタンで有効にすれば、CRへのコマンド縺?ARに転送、コンテナもAR縺?submitできる
窶?ARにコンテナを最初に置いておきたい場合縺? gcraneコマンドでコピーできる
■GCPディスク容驥?
コンソールからディスクに入り編集で容量追加
公開イメージのブートは自動変更される
カスタムイメージや非ブートディスクは手動変更が必要
手動方觸??は臀??記藹??辣?
/// BANGBOO BLOG /// - Linux cmd■GCP縺?sudo apt-get updateができないとき
wget https://packages.cloud.google.com/apt/doc/apt-key.gpg
apt-key add apt-key.gpg
■GCEでの通信・??GCEのサービスアカウントとホスト上縺?OSLoginユーザの違い)
Google API縺?SAで鐔??く(SAに各権限を付けておく)
ただgcloud compute start-iap-tunel 縺?SAで鐔??縺?が
サービスアカウントユーザロールで藹??行者縺?SAを紐づけて鐔??く?
(サービスアカウントに操作するユーザ縺?serviceAccountUserの権限が必要)
その臀??縺?httpsアクセスやls等コマンドはホスト上の藹??行者で鐔??縺?
■IAPトンネルで内驛?IPでも外部に出る設藹??
#権限
ユーザ利用縺?GCE縺?SA縺?IAPトンネル権限を雕?み藹??IAPにつける
SAに利用ユーザに対するserviceAccountUserの権限を付ける
#GCEインスタンス縺?SSHをし下記を実行
#自分に通信するプロキ繧?
export http_proxy=http://localhost:3128
export https_proxy=http://localhost:3128
#それを転送する
gcloud compute start-iap-tunnel --zone asia-northeast1-a gce-host-proxy001 3128 --local-host-port=localhost:3128 --project=bangboo-kuso-proxy &
#外部通菫?
git clone xxx
#止める(止めないと同じホストに軆??縺?に鐔??く)
lsof -i 3128
ps ax | grep 3128
ps ax | iap
ps からの kill -kill <iap ps> でできそうにない
gcloud auth revoke から縺? gcloud auth login の再ログイン・??
export -n http_proxy
export -n http_proxy
■雕?み台軆??由して臀??のインスタンスに接続
#雕?み台に接続
gcloud compute ssh step-fumidai001 --project=bangboo-unco --zone=asia-notrheast2-a --tunnel-through-iap
#リストを出し該藹??ホストを見つける
gcloud compute instances list
#雕?み台から他のへ接続
instance=bangboo-kami
gcloud compute ssh $instance --internal-ip --zone=asia-northeast2-a
#もしGKEなら接続前縺?step-fumidai001でクレデンシャルが必要だったり、、、
gcloud container clusters get-credentials main -zone asia-northeast2-a --project bangboo-k8s
■curlで鐔??証を藹??けながら縺?URLアクセ繧?
笳?gcloud auth loginしていると、、
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" https://宛先
笳?SAキーをアップロードなら、、
export GOOGLE_APPLICATION_CREDENTIALS="/home/aho/sa-key.json"
この環藹??変数縺?gcloudライブラ繝?/SDK等が認証情報として藹??照するようになっている
access_token=$(gcloud auth application-default print-access-token)
curl -H "Authorization: Bearer $access_token" https://kuso.com/api/endpoint
■キー・??遞?
サービスアカウントキ繝?
APIキ繝?
credentials(Oauth clientIDを作成しキー生成)
■Workload identity federation
使うサービスがIdPを持っ縺?WIF対藹??していれ縺?SAキー無く使用できる(GCP縺?
SAは鐔??る)
笳?GCP<-AWS,Github,EKS等OpenID connect/SAML2.0
事前設藹??)GCP SAを作成し権限付荳?
GCP縺?WIプールを作成
GCP WIプールで該当IdPを認証、外部アカウントを紐づける
1)UserがIdPにリクエスト
2)IdPがUserを割り当てたIDトーク繝?(JWT)発鐔??
3)IdPがIDトークンをGCPに觸??險?
組織を限定するGCP設藹??
リポジトリを限定するGCP設藹??
4)GCPがWIF一時トークンを発鐔??しUserがGCPリソースを使逕?
Workload Identity Federationを図で理解する - Carpe Diem (hatenablog.com)笳?GCP<-GKEクラスタは臀??の方觸??もある
笳?笳?GKE縺?SA設藹??(WIF以藹??)
1)繝?ードに軆??付いたサービスアカウントを使用する
GKEクラスタ臀??成時縺?IAM SAを指定かGCEデフ繧?SAが設藹??されるのでこれ縺?GCP使逕?
GKE繝?ードのワークロード全てで同一縺?SAが使用されPod豈?に権限を分けられない
GKEの中身縺?GCEなの縺?GCEインスタンス縺?SAを見る?GCEが無いかも
GKEがAutopilotならWIFが有効で繝?ードSAがGoogleAPI用には使えない?
2)SAのキーを Kubernetes Secretリソースとし縺?GKEクラスタに登骭?
IAM SA キーの有効期限が長縺?、手動でログローテーションが必要な点が懸念
エクスポートした IAM SA の觸??出リスクがある
GCP SAとキーを作成しキーをマニフェストに設定
笳?笳?GKEのため縺?WIF利用・??推奨・??
GKE node SA @project.iam.serviceaccount.com を
pool name - namespace 縺? WIプール縺?
GOP SA 縺? pool-namespace@project.iam.serviceaccount.contに軆??づける
コマンドやマニフェストで詳し縺?縺?Link先縺?
ブールを有効化すると繝?ードSAが使えな縺?なるので注諢?
■GCE縺?OSConfigAgent のエラ繝?(apt updateが失敗する、リポジトリが変繧?った)
sudo apt-allow-releaseinfo-change update
を複数回実行することで新しいリポジトリが追加される
■SA縺?Googleドライブにアクセ繧?
OUを使う解決策。Trusted RuleによりGCP サービスアカウントからGoogle Driveへのア繧? セスを許可する方觸??です。サービスアカウントのグループがアクセス可能縺?OUを作りOU内 で藹??用共有ドライブを作成する。
■IAM>PAM
一時付荳?の権限申鐔??ができる
■スクリプトによる権限付荳?
Grant文、BQ、Python 等の方觸??がある
■ZOZOの新米Google cloud管理者
新米Google Cloud管理者の奮闘記のその藹?? 〜Organizationの秩蠎?を維持する試み〜 - ZOZO TECH BLOG■デー繧?
次臀??代データ基盤・??データレイク繝?ウスを Google Cloud で藹??現する (zenn.dev)- BigQuery Data Transfer Service:
Cloud Storage や Amazon S3、Azure Blob Storage など格軆??されているデータを BigQuery に転送するマネージド サービスです。主に觸??造化データや半構造化データをバッチ処理に縺? BigQuery へ直接転送したい場合に使用します。 - Storage Transfer Service:
Cloud Storage、Amazon S3、Azure Storage、オンプレミ繧? データなどに格軆??されているオブジェクトやファイルを Cloud Storage へ転送するマネージド サービスです。主にオブジェクトやファイルをバッチ処理に縺? Cloud Storage へ直接転送したい場合に使用します。 - Datastream:
Oracle、MySQL、PostgreSQL といったデータベースのから BigQuery に対してシームレスにデータを複製できるサーバーレスな藹??更デー繧? キャプチャ・??CDC)サービスです。データベースの内容をリアルタイム縺? BigQuery へ藹??映したい場合に使用します。 - Cloud Data Fusion:
フルマネージドのデー繧? パイプライン觸??築サービスであり、繝?ーコード・ローコード縺? ETL を実装できます。データ転送のみの用途でも使用可能であり、特縺? プラグイ繝? を使用することで、多種藹??様なデータソースに対応することが可能です。また、Datastream と同様縺? Oracle、MySQL、PostgreSQL から BigQuery へ縺? CDC 機能も觸??供されています。 - Dataflow:
Apache Beam のプログラミングモデルを使用して、大鐔??模なデータを処理できるフルマネージドでサーバーレスなデータ処理サービスです。データ転送のみの用途でも使用可能であり、Google 觸??供テンプレート を使用することで、簡単にデータ転送の臀??組みを構築することができます。 - Pub/Sub:
フルマネージドなメッセージキューイングサービスです。Cloud Storage サブスクリプショ繝? を使用すると、Pub/Sub メッセージを Cloud Storage に対して書き込むことが可能です。また BigQuery サブスクリプショ繝? を使用すると、Pub/Sub メッセージを BigQuery テーブルに直接書き込むことができ、 さら縺? BigQuery CDC を使用するとテーブルの鐔??単位縺? UPSERT(UPDATE, INSERT)、DELETE が可能です。 - Database Migration Service:
MySQL や PostgreSQL から Cloud SQL や AlloyDB に対して、マネージド サービスへのリフト アンド シフト移鐔??やマルチクラウドの軆??続的レプリケーションを行います。オンプレミスや他クラウドからのデータベース移行が必要な場合に使用します。
↓
- BigQuery:
SQL によってデータ藹??觸??を行います。ルーティンとして、ストアド プロシージ繝? や ユーザー藹??義関謨?、テーブル関謨? 、Apache Spark 用ストアド プロシージ繝? が使用できます。また、リモート関謨? を使用すると、Cloud Functions 縺? Cloud Run にデプロイされた関数をクエリから呼び出すことができます。 - Dataflow:
前述の通り、フルマネージドでサーバーレスなデータ処理サービスです。同一コードでバッチとストリーミングの両方に対応できるという特徴があります。また、通常縺? Dataflow だと水平方向のみの自動スケーリングとなりますが、Dataflow Prime を使用することで、垂直方向へも自動スケーリングが可能です。 - Dataproc:
Hadoop 縺? Spark などのデータ処理ワークロードを実行するためのマネージド サービスです。既藹??縺? Hadoop / Spark を移鐔??する場合やプリエンプティブ繝? VM また縺? Spot VM によってコストを抑えたい場合に適しています。 - Dataprep:
分析、レポートなどに使用するデータを視覚的に探索、データクレンジングできるデータサービスです。特縺?UI操作でデータ探索やデータクレンジングが可能なことが特徴です。 - Cloud Data Fusion:
前述の通り、繝?ーコード・ローコード縺? ETL を実装できるフルマネージドのデー繧? パイプライン觸??築サービスです。データのコネクションだけでな縺?、ETL に関する様々縺? プラグイ繝? が用諢?されていることが特徴です。
GKEやRunに信頼できるコンテナイメージのみをデプロイするための管理
ポリシーや承鐔??者を設藹??し縺?OKのもののみ許可する
コンテナ脆弱性スキャン強弱の設定等
■reCaptcha
v1はゆがんだ文字を入力するもの、v2は画蜒?を選択し私はロボットではありませんとチェック、v3縺?Web行動履歴等をスコア化して自動的に判藹??を行う操作不要のもの・??GCPコンソールで軆??果分析もできる)
■BQ DuetAI
BQ studio内縺?notebookがありpythonが使える(現在プレビュ繝?
MLモデルを作成し使用できる
Posted by funa : 12:00 AM
| Web
| Comment (0)
| Trackback (0)